
Gemini Developer API
Get a Gemini API key and make your first API request in minutes.
Python
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
response = client.models.generate_content(
model="gemini-2.0-flash",
contents="Explain how AI works",
)
print(response.text)
Node.js
const { GoogleGenerativeAI } = require("@google/generative-ai");
const genAI = new GoogleGenerativeAI("YOUR_API_KEY");
const model = genAI.getGenerativeModel({ model: "gemini-2.0-flash" });
const prompt = "Explain how AI works";
const result = await model.generateContent(prompt);
console.log(result.response.text());
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash:generateContent?key=YOUR_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[{"text": "Explain how AI works"}]
}]
}'
Meet the models
Explore the API

Explore long context
Input millions of tokens to Gemini models and derive understanding from unstructured images, videos, and documents.
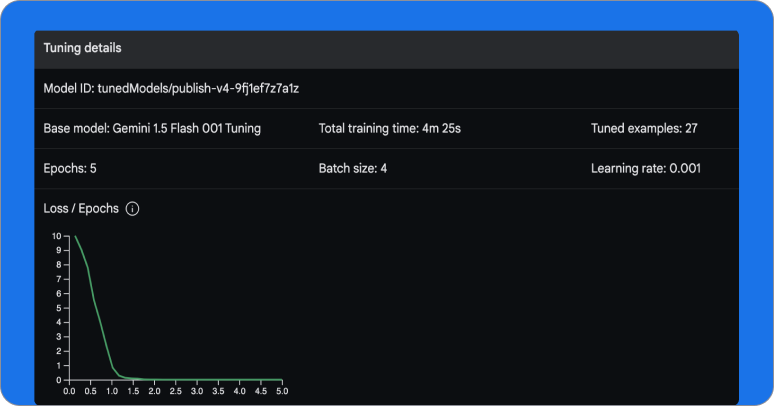
Solve tasks with fine-tuning
Modify the behavior of Gemini models to adapt to specific tasks, recognize data, and solve problems. Tune models with your own data to make production deployments more robust and reliable.
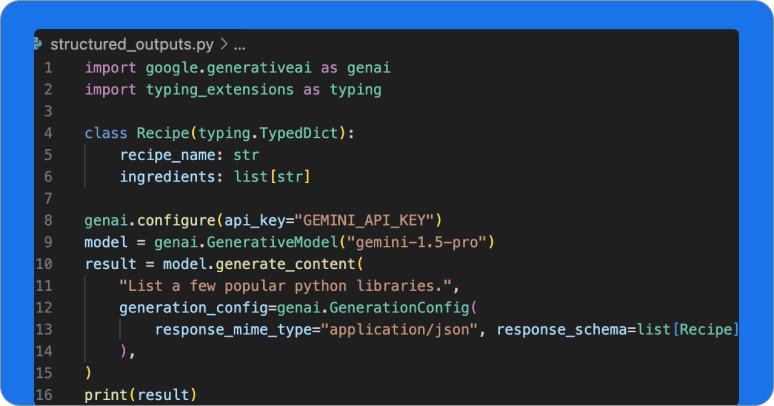
Generate structured outputs
Constrain Gemini to respond with JSON, a structured data format suitable for automated processing.