
Gemini 系列人工智能 (AI) 模型 各种类型的输入数据,包括文本、图片和音频。由于这些 模型可以处理多种类型或模式的数据,因此 Gemini 模型 称为多模态模型,或者解释为具有多模态功能。
本页提供了有关将媒体文件与 Gemini API 的提示。如需了解如何针对 上传媒体文件,并将媒体文件添加到提示中,请参阅 视觉、音频和 文档处理指南。
在提示中使用媒体文件
能够在问题中使用各种类型的数据 。对于 例如,你可以向模型发送美味佳肴的照片, 一个关于该餐点的简短博客
| 提示 | 答案 |
|
根据这张图片撰写一篇富有吸引力的简短博文。它应该 在照片中添加对餐点的说明并谈论我的旅程 例如做饭准备。 
|
备餐是节省时间和金钱的好方法,而且还可以 帮助您更健康地饮食。这道餐食是有益健康的 以及可轻松提前准备好的美味佳肴。 这道餐点包括荞麦米、烤蔬菜和鸡肉照烧。 红米是一种健康、复杂的碳水化合物,可让您 和持续的能量烤蔬菜是每天 多吃一些维生素和矿物质,而鸡肉的照烧鸡肉 富含蛋白质的食物 这道餐食也很容易准备。只将糙米烤好 和蔬菜烹制照烧鸡肉。等所有菜都准备好后 分装成备餐容器并存放在冰箱中。 然后,您就可以带上容器来度过忙碌的早上了! 如果您想要轻松吃到健康美味的餐点 因为这道餐点已提前准备好了,是个不错的选择。它装满了 营养和口味,这必定能让您获得饱腹感和满足感。 准备健康美味的膳食! |
使用媒体进行提示的策略
如果您无法从使用 有一些策略,可以帮助您获得 。以下部分介绍了设计方法和问题排查方法 改进使用多模态输入的提示。
您可以按照以下最佳实践来改进多模态提示:
-
提示设计基础知识
- 指令应当明确具体:编写清晰且简洁的指令,尽量避免误解。
- 向提示中添加一些示例:使用切实可行的少样本示例来说明您要实现的目标。
- 分步细分:将复杂的任务划分为多个易于管理的子目标,引导模型完成整个过程。
- 指定输出格式:在提示中,要求输出采用所需的格式,如 Markdown、JSON、HTML 等。
- 针对单图提示,将图片放在最前面:虽然 Gemini 可以按任意顺序处理图片和文本输入,但对于包含单张图片的问题,如果将图片放在文本提示之前,可能会获得更好的效果。
-
排查多模态提示问题
- 如果模型没有从图片的相关部分提取信息:给出提示,说明您希望提示从图片的哪些方面提取信息。
- 如果模型输出过于宽泛(未针对图片进行充分定制): 在提示开头,请尝试让模型描述图片,然后再提供任务说明,或者尝试让模型参考图片中的内容。
提示设计基础知识
本部分对上一部分中列出的最佳实践进行了扩展。
注意:以下 Gemini 示例的模型结果可能因运行而异。
说明应当明确具体
提示在清晰而详细时最成功。如果您考虑获得特定输出,最好在提示中包含该要求,以确保获得所需输出。
有时,提示的意图可能对编写提示的人来说似乎很清晰,但实际上它并不足够明确。 如需自定义模型行为,请考虑对您的提示的误解,并确保您提供的说明简短具体。请尽量避免误解。
对于此机场面板图片,要求模型仅“描述此图片”可能会生成一般性说明。如果您需要模型从图片中解析时间和城市,则可以直接在提示中添加该请求。
| 提示 | 模型回答 |
|---|---|
 描述此图片。 |
此图片显示了机场到达和出发信息面板。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
将下图中显示的机场面板中的时间和城市解析为列表。 |
添加一些示例
Gemini 模型可以接受多个输入,它可以将这些输入用作示例来理解所需的输出。添加这些示例有助于模型识别模式,并将给定图片与回答之间的关系应用于新示例。这也称为少量样本学习。
在以下示例中,初始输出以句子形式编写,并且还包含国家/地区(巴西)。假设您需要不同格式或样式的输出,并且只希望输入城市而不是国家/地区。向提示中添加少样本示例可以引导模型以您所需的方式进行回答。
| 提示 | 模型回答 |
|---|---|
 确定城市以及地标。 |
地标是巴西里约热内卢的基督救世主雕像。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
确定城市以及地标。 
|
城市:罗马,地标:斗兽场。 |

|
城市:北京,地标:紫禁城 |
|
|
城市:里约热内卢,地标:基督救世主雕像 |
分步细分
对于复杂的任务(例如需要视觉理解和推理的任务),将任务拆分为更小、更直接的步骤可能会很有帮助。或者,如果您在提示中直接要求模型“分步思考”,也可能会很有效。
| 提示 | 模型回答 |
|---|---|
 我什么时候会将卫生纸用完? |
您只剩下 3 卷了。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
|
数学问题或其他类型的字词问题非常适合要求模型分步思考。
| 提示 | 答案 |
|---|---|
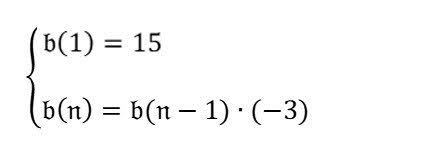
序列中的第 4 项是什么? |
-135 |
模型的回答不正确。改进这种情况的一些方法是要求模型在回答提示之前,先解析问题。
| 提示 | 答案 |
|---|---|
首先解析图片中的公式。 然后,根据公式回答“序列中的第 4 项是什么?”。 |
点击可展开结果$$ b(n) = b(n-1) * (-3) $$ $$ b(1) = 15 $$
$$ b(4) = b(4-1) * (-3) $$ $$ b(4) = b(3) * (-3) $$ $$ b(3) = b(3-1) * (-3) $$ $$ b(3) = b(2) * (-3) $$ $$ b(2) = b(2-1) * (-3) $$ $$ b(2) = b(1) * (-3) $$ $$ b(2) = 15 * (-3) $$ $$ b(2) = -45 $$ $$ b(3) = b(2) * (-3) $$ $$ b(3) = -45 * (-3) $$ $$ b(3) = 135 $$ $$ b(4) = b(3) * (-3) $$ $$ b(4) = 135 * (-3) $$ $$ b(4) = -405 $$ 因此,序列中的第 4 项是 -405。 |
此模型回答是正确的。现在,如需简化回答,您可以要求模型分步思考。
| 更新后的提示 | 改进后的回答 |
|---|---|
序列中的第 4 项是什么?请分步思考。 |
第一项是 15。 第二项是 b(1) * (-3) = 15 * (-3) = -45。 第三项是 b(2) * (-3) = -45 * (-3) = 135。 第四项是 b(3) * (-3) = 135 * (-3) = -405。 |
尝试指定输出格式
一个常见问题是模型输出需要采用特定格式(例如 Markdown、JSON、HTML),尤其是在需要由下游任务提取模型输出的情况下。您可以尝试在提示中指示模型生成采用该格式的输出。以下是两个示例:
| 提示 | 模型回答 |
|---|---|
 将此图片中的表格解析为 Markdown 格式 |
| 学科 | 状态 | 时间 | 开始日期 | 截止日期 | | ------- | ------ | ---- | --------- | ------ | | 数学 | 完成 | 1.5 小时 | 2023 年 11 月 29 日 | 2023 年 12 月 1 日 | | 地理 | 完成 | 30 分钟 | 2023 年 12 月 2 日 | 2023 年 12 月 4 日 | | 物理 | 进行中 | 2 小时 | 2023 年 12 月 3 日 | 2023 年 12 月 5 日 | | 生物 | 未开始 | 6 小时 | 2016 年 11 月 2 日 | 2023 年 12 月 6 日 | |
| 提示 | 模型回答 |
|---|---|

请提供以下所有属性的列表: 配料、菜系类型、是否为素菜,采用 JSON 格式 |
|
首先将图片放在单图片提示中
虽然 Gemini 可以在提示中以任意顺序解读图片和文字,但将单个图片置于文字提示之前可以获得更好的结果。在以下示例中,您会看到 在每个提示中的文本之前。
排查多模态提示问题
如果您未收到有用的回答,则可能需要排查提示问题。您可以尝试以下一些策略。
如果模型没有从图片的相关部分提取信息
如需获得更具体的回答,您可以指明您希望提示从图片的哪些方面提取信息以告知其回答。
| 提示 | 模型回答 |
|---|---|
 这些尿片可供一个婴儿使用多少天? |
这些尿片可以使用 198 天。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
这些尿片可以使用多长时间? 使用包装盒上显示的体重确定孩子的年龄,并使用包装盒中的尿片总数。 用总数除以孩子每天要换的尿片数量。 |
包装盒中有 198 张尿片。包装盒上注明尿片适用于体重 22-37 磅的孩子。 此体重范围内的普通孩子可能在 1 至 2 岁之间。 2 岁的孩子通常每天要换 6 片尿片,因此尿片的使用寿命约为 33 天 (198/6)。 |
模型输出过于宽泛,且未针对图片输入进行充分定制
如需帮助模型针对图片定制其回答,请尝试要求它在执行推理任务之前描述图片。
| 提示 | 模型回答 |
|---|---|



这些图片有什么共同之处? |
全部四张图片都是横向摄影的示例。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
首先,详细描述每张图片中的内容。这些图片有什么共同之处? |
第一张图片显示一个人正在收拾手提包。第二张图片显示购物中心内空无一人的走廊。第三张图片显示一卷卫生纸。第四张图片显示黑暗汹涌的大海。 这些图片之间的共同之处在于,它们都是临界空间的示例。临界空间是指处于两个其他场所或情景之间的场所或情景。它们通常以一种不确定或模糊的感觉为特征。 第一张图片显示处于居家与旅行之间的人。第二张图片显示两家商店之间的走廊。第三张图片是卫生纸,可以代表浴室。而浴室是私人领域与公共领域之间的过渡空间。它是一个让我们为进入或离开外部世界做好准备的场所。 第四张图片显示介于平静与风暴之间的大海。 临界空间可能既令人兴奋,又令人不安。它们既可以作为崭新开始的场所,也可以作为结束的场所。它们可以是反思的场所,也可以是行动的场所。 |
您也可以尝试明确要求模型参考图片中的内容。
| 更新后的提示 | 改进后的回答 |
|---|---|
|
这些图片有什么共同之处?请在回答中参考图片的内容。 |
所有图片都与旅行相关。第一张图片显示一个人正在收拾手提包,第二张图片显示购物中心空无一人的走廊,第三张图片显示一叠卫生纸,第四张图片显示黑暗汹涌的大海。 这些图片都与旅行相关,因为它们都是人们在旅行时所需要或使用的事物。第一张图片显示一个人正在收拾手提包,这是人们在旅行时要做的事情。第二张图片显示购物中心内空无一人的走廊,人们经常来到这个场所购买旅行用品。第三张图片显示一叠卫生纸,这是人们在旅行时经常使用的物品。第四张图片显示黑暗汹涌的大海,这是人们在旅行时经常遇到的景象。 |
同样的提示也适用于以图片形式输出的广告素材。在以下包含兔子的示例中,明确要求模型包含图片中的各个方面可以改进输出。
| 提示 | 模型回答 |
|---|---|

您能为我写一首关于此图片的诗歌吗? |
棕色的软软的小兔子, 你啃着又甜又绿的青草, |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
您能为我写一首关于此图片的兼具描述性和戏剧性的诗歌,并在其中包含地点吗? |
小小兔子在绿草坪, 是那在阳光下熠熠生辉的, 小兔子,告诉我吧, 也许是眼前的一切, 小兔子,当你在草地上静静地坐着, 无论是什么,小兔子, |
排查提示的哪个部分失败
很难知道提示失败是否是因为模型一开始不理解图片,或者它是否理解图片但随后没有执行正确的推理步骤。
如需区分这些原因,请要求模型描述图片中的内容。
在以下示例中,如果在与茶搭配时,模型以似乎令人惊讶的零食(例如爆米花)作为回答,则可以先进行问题排查,以确定模型是否正确识别出图片中包含茶。
| 提示 | 用于问题排查的提示 |
|---|---|
 我在 1 分钟内能拿出什么零食来与此图片中的内容搭配食用? |
描述此图片中的内容。 |
另一种策略是要求模型说明其推理。这有助于您缩小推理失败的部分(如果有)。
| 提示 | 用于问题排查的提示 |
|---|---|
我在 1 分钟内能拿出什么零食来与此图片中的内容搭配食用? |
我在 1 分钟内能拿出什么零食来与此图片中的内容搭配食用?请说明原因。 |
对采样参数调优
在每个请求中,您不仅向模型发送多模态提示,还会发送一组采样参数。对于不同的参数值,模型会生成不同的结果。因此请尝试不同的参数,以获得任务的最佳值。最常调整的参数如下:
- 温度
- Top-P
- Top-K
温度
温度用于在回答生成期间进行采样,这会在应用 top-P 和 top-K 时进行。温度可以控制词元选择的随机性。较低的温度有利于需要更具确定性、更少开放性或创造性回答的提示,而较高的温度可以带来更具多样性或创造性的结果。温度为 0 表示确定性,即始终选择概率最高的回答。
对于大多数应用场景,不妨先试着将温度设为 0.4。如果您需要更具创造性的结果,请尝试提高温度。如果您观察到明显的幻觉,请尝试降低温度。
Top-K
Top-K 可更改模型选择输出词元的方式。如果 Top-K 设为 1,表示下一个所选词元是模型词汇表的所有词元中概率最高的词元(也称为贪心解码)。如果 Top-K 设为 3,则表示系统将从 3 个概率最高的词元(通过温度确定)中选择下一个词元。
在每个词元选择步中,系统都会对概率最高的 Top-K 词元进行采样。然后,系统会根据 Top-P 进一步过滤词元,并使用温度采样选择最终的词元。
指定较低的值可获得随机程度较低的回答,指定较高的值可获得随机程度较高的回答。 top-K 的默认值为 32。
Top-P
Top-P 可更改模型选择输出词元的方式。系统会按照概率从最高(见 Top-K)到最低的顺序选择词元,直到所选词元的概率总和等于 Top-P 的值。例如,如果词元 A、B 和 C 的概率分别为 0.6、0.3 和 0.1,并且 Top-P 的值为 0.9,则模型将选择 A 或 B 作为下一个词元(通过温度确定),并会排除 C 作为候选词元。
指定较低的值可获得随机程度较低的回答,指定较高的值可获得随机程度较高的回答。 top-P 的默认值为 1.0。
后续步骤
- 尝试使用 Google AI 编写您自己的多模态提示 工作室。
- 如需了解有关提示设计的更多指导,请参阅 提示策略页面。