
 機械学習/ディープラーニングが無料で学べる、米国有名大学の「オンライン講座/講義動画」
機械学習/ディープラーニングが無料で学べる、米国有名大学の「オンライン講座/講義動画」機械学習/ディープラーニングが無料で学べる、米国有名大学の「オンライン講座/講義動画」:AI・機械学習の独学リソース アメリカのスタンフォード大学/MIT/ハーバード大学/コロンビア大学/ニューヨーク大学といった有名大学の一部では機械学習や深層学習のオンライン講座/講義動画を無料で配信している。その概要と特長をまとめる。


 最近見つけたクールなPythonライブラリ6選 - Qiita
最近見つけたクールなPythonライブラリ6選 - Qiita
機械学習のためのすごいPythonライブラリ Image by Free-Photos from Pixabay はじめに Pythonは機械学習に不可欠な要素で、ライブラリは作業をより単純にしてくれます。最近、MLのプロジェクトに取り組んでいる時に、素晴らしいライブラリを6つ見つけました。ここでは、それを紹介します。 1. clean-text clean-textは本当に素晴らしいライブラリで、スクレイピングやソーシャルメディアデータを処理する時にまず使うべきものです。最も素晴らしい点は、データをクリーンアップするために長く凝ったコードや正規表現を必要としないことです。 いくつかの例を見てみましょう。 インストール #Importing the clean text library from cleantext import clean # Sample text text = """

 How to represent part-whole hierarchies in a neural network
How to represent part-whole hierarchies in a neural network
This paper does not describe a working system. Instead, it presents a single idea about representation which allows advances made by several different groups to be combined into an imaginary system called GLOM. The advances include transformers, neural fields, contrastive representation learning, distillation and capsules. GLOM answers the question: How can a neural network with a fixed architectu
 企業の“Kaggler枠”って実際どうなの? ― データサイエンティスト協会 7th シンポジウム
企業の“Kaggler枠”って実際どうなの? ― データサイエンティスト協会 7th シンポジウム
企業の“Kaggler枠”って実際どうなの? ― データサイエンティスト協会 7th シンポジウム:Kaggleイベントレポート 最近注目を集めている“Kaggler採用枠”やKaggler社内ランク制度の実態はどのようなもので、それによってどのようなメリットがあるのか。実際にKaggler制度を運用する企業の代表者やその制度の下で働くKagglerたちの意見を聞いてみよう。

 音声を文字起こししてくれる「Amazon Transcribe」、言語の種類を自動識別する新機能。人間によるタグ付けが不要に
音声を文字起こししてくれる「Amazon Transcribe」、言語の種類を自動識別する新機能。人間によるタグ付けが不要に
音声を文字起こししてくれる「Amazon Transcribe」、言語の種類を自動識別する新機能。人間によるタグ付けが不要に Amazon Web Services(AWS)が提供する「Amazon Transcribe」は、音声をテキストに変換する、いわゆる文字起こしを機械が行ってくれるサービスです。 例えば、ボイスメールをテキストに変換して送信するサービスの構築や、電話での問い合わせなどを受け付けるコールセンターなどで顧客とのやり取りの記録をテキストで残すサービスの開発などに役立ちます。 AWSはこのAmazon Transcribeに、話されている言語が英語なのか日本語なのか中国語なのか、などの言語の種類を自動的に識別する機能を追加したと発表しました。 New #AWSLaunches! New AWS Solutions Consulting Offer - Confluence

 みにくいアヒルの子の定理(Ugly Duckling theorem)とは?
みにくいアヒルの子の定理(Ugly Duckling theorem)とは?
連載目次 用語解説 機械学習におけるみにくいアヒルの子の定理(醜いアヒルの子の定理: Ugly Duckling theorem)とは、何らかの「仮定(=事前知識や偏向、帰納バイアス)」がないと「分類(=類似性の判断)」は(理論上)不可能である、ということを主張する定理である。つまり分類やパターン認識において、あらゆる特徴量を客観的に同等に扱うことはできず、何らかの仮定に基づいて主観的に特徴量選択を行うことが本質的に必要であることを示す。 概念的にはノーフリーランチ定理に似ており、機械学習で必修の定理として一緒に学ぶことが多い。ノーフリーランチ定理は「あらゆる問題を効率よく解けるような“万能”の機械学習モデルや探索/最適化のアルゴリズムなどは存在しない」ことを主張する用語である。一方、みにくいアヒルの子の定理は「仮定/事前知識がない場合には、分類性能が高くなるような“最良”の特徴表現/特徴

 Python vs Rust for Neural Networks | Nathan Goldbaum
Python vs Rust for Neural Networks | Nathan Goldbaum
In a previous post I introduced the MNIST dataset and the problem of classifying handwritten digits. In this post I’ll be using the code I wrote in that post to port a simple neural network implementation to rust. My goal is to explore performance and ergonomics for data science workflows in rust. The Python Implementation Chapter 1 of the book describes a very simple single-layer Neural Network t
 GradType BatlleGround
GradType BatlleGround
We have trained a neural network to identify the users by their manner of typing on keyboard. The recurrent neural network learned to recognize small timing difference between keypresses to successfully identify the "typer" given 30-40 previously seen sentences. Type few sentences below to play with it or log in with GitHub to store your identifiers for extensive testing (and further improvement o
 Googleが大量の機械学習用データベースを無料公開してた - Qiita
Googleが大量の機械学習用データベースを無料公開してた - Qiita
個人用メモです。 機械学習は素材集めがとても大変です。 でもこの素材集め、実は無理してやらなくても、元から良質な無料データベースがあったようなのです。 URLはこちら YouTube8-M https://research.google.com/youtube8m/explore.html 提供されているサービスは以下の通り 800万個の動画 19億個のフレーム 4800個の分類 使い方はExploreから画像セットを探し、ダウンロードするだけ。 他の方法も見つけた open images dataset 「すごい神だな」と思ったのは これもう完成されてますよね もちろんこの認識前の画像もセットでダウンロードできます。 Youtube-8Mとは、画像数を取るか、精度で取るか、という違いでしょうか。 他にも良い素材集を教えていただきました (はてなブックマーク情報 @sek_165 さん )

 NVIDIA、大規模データ分析・機械学習向けオープンソースGPUアクセラレーションプラットフォーム「RAPIDS」発表
NVIDIA、大規模データ分析・機械学習向けオープンソースGPUアクセラレーションプラットフォーム「RAPIDS」発表
「RAPIDS」は、クレジットカード詐欺の予想や、小売り在庫の予測や顧客の購入行動を理解するなど、非常に複雑なビジネス課題に取り組むデータサイエンティストのパフォーマンスを大幅に向上するGPUアクセラレーションプラットフォーム。 「RAPIDS」の公開にあわせて、同社のエンジニアがオープンソースのコントリビュータと協力して開発した、GPUでアクセラレートした分析やマシンラーニング、およびデータ可視化のためのオープンソースライブラリが提供される。 なお、NVIDIA DGX-2システムでのトレーニング用に、XGBoostマシンラーニングアルゴリズムを使用した初期の「RAPIDS」ベンチマークでは、CPUのみのシステムと比較して50倍もスピードアップしたという。 同イベントの基調講演において「RAPIDS」を紹介した、同社の創業者/CEOのJensen Huang氏は、「データ分析およびマシン

 The University of Tokyo Online Courses | Coursera
The University of Tokyo Online Courses | Coursera
The University of TokyoThe University of Tokyo was established in 1877 as the first national university in Japan. As a leading research university, UTokyo offers courses in essentially all academic disciplines at both undergraduate and graduate levels and conducts research across the full spectrum of academic activity.

 Googleの機械学習のレッスンが無料で受けれて資格が貰える余暇。 : ひろゆき@オープンSNS
Googleの機械学習のレッスンが無料で受けれて資格が貰える余暇。 : ひろゆき@オープンSNS
【教えてくん】コミュニティーなのです。 なんかニュースとかあったらここに書こうかと思ってますよ。とりあえず、おいらのブログ Googleの機械学習のレッスンが無料で受けれて資格が貰える余暇。 : ひろゆき@オープンSNS ひろゆき@オープンSNS (ひろゆき@オープンSNS) 投稿者, @ 2018-09-19 18:46:00 Googleの機械学習のレッスンが無料で受けれて資格が貰える余暇。 こんにちは。夏休みの最終日に宿題をやる派のひろゆきです。 ネットで暇つぶしにニュースサイトを見てる人も多いと思うんですが、「新しい知識を得る」ってエンタメなんですよね。 ってことで、ネットには無料でいろいろ覚えられるサイトがあったりするんですが、マサチューセッツ工科大学とか、ハーバード大学とかがやってるedXの機械学習のコースとか試してみたんですが、20分ぐらいで飽きちゃったりして、宝箱を開けたり
 ミシガン大が「フェイクニュース検出システム」開発、言語分析アルゴリズムを利用
ミシガン大が「フェイクニュース検出システム」開発、言語分析アルゴリズムを利用
ミシガン大学の研究者が、フェイクニュース記事を人間並みに、時には人間以上に正確に見分ける言語分析アルゴリズムベースのシステムを開発した。「うその言語的特徴」を識別することで、人間よりも最大6ポイント高い検出率を実現できたという。 米ミシガン大学の研究者が、フェイクニュース記事における「うその言語的特徴」を識別するアルゴリズムベースのシステムを開発した。同システムがフェイクニュースを人間並みに、時には人間以上に正確に見分けることができることも実証した。 人間の判別成功率が70%にとどまる中、同システムは、最大76%の成功率でフェイクニュース記事を検出した。このシステムの言語分析アプローチは、最新のフェイクニュース記事が公開された直後でも有効だという。つまり、他の記事と照合して事実確認を行い、うそを暴けない場合でも、フェイクニュース記事を見分けられる可能性があるという。 ミシガン大学のコンピュ

 Netflix Prize: Home
Netflix Prize: Home
The Netflix Prize sought to substantially improve the accuracy of predictions about how much someone is going to enjoy a movie based on their movie preferences. On September 21, 2009 we awarded the $1M Grand Prize to team “BellKor’s Pragmatic Chaos”. Read about their algorithm, checkout team scores on the Leaderboard, and join the discussions on the Forum. We applaud all the contributors to this q
リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


 無料で読める「機械学習/ディープラーニング」の有名書籍! 厳選4冊
無料で読める「機械学習/ディープラーニング」の有名書籍! 厳選4冊
 RPA+AIで紙文書を自動処理する時代がすぐそこに! UiPathの「Receipt and Invoice AI」プレビュー版を試す【イニシャルB】
RPA+AIで紙文書を自動処理する時代がすぐそこに! UiPathの「Receipt and Invoice AI」プレビュー版を試す【イニシャルB】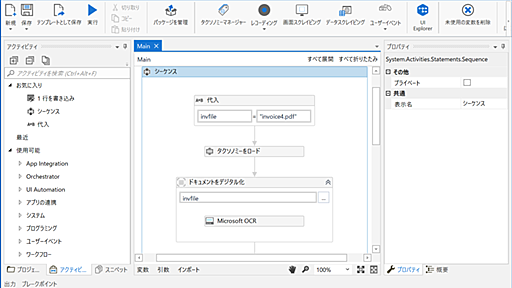
 機械学習で人気言語3位にJavaScript、6位にJulia--GitHubトップ10 - ZDNet Japan
機械学習で人気言語3位にJavaScript、6位にJulia--GitHubトップ10 - ZDNet Japan Anime Girl Face Generation Making Leaps & Bounds – Sankaku Complex
Anime Girl Face Generation Making Leaps & Bounds – Sankaku Complex グーグルの画像認識システムは、まだ「ゴリラ問題」を解決できていない──見えてきた「機械学習の課題」
グーグルの画像認識システムは、まだ「ゴリラ問題」を解決できていない──見えてきた「機械学習の課題」 koki0702 - Overview
koki0702 - Overview