Accelerate your generative AI journey with NVIDIA NeMo framework on GKE
Sujit Khasnis
Solutions Architect, Partner Engineering, Google Cloud
Suffian Khan
Software Engineer, AI+Accelerators, Google Cloud
Background
Ever since generative AI gained prominence in the AI field, organizations ranging from startups to large enterprises have moved to harness its power by making it an integral part of their applications, solutions, and platforms. While the true potential of generative AI lies in creating new content based on learning from existing content, it is becoming important that the content produced has a degree of specificity to a given area or domain.
This blog post shows how generative AI models can be adapted to your use cases by demonstrating how to train models on Google Kubernetes Engine (GKE) using NVIDIA accelerated computing and NVIDIA NeMo framework.
Building generative AI models
In the context of constructing generative AI models, high-quality data (the ‘dataset’), serves as a foundational element. Data in various formats, such as text, code, images, and others, is processed, enhanced, and analyzed to minimize direct effects on the model's output. Based on the model's modality, this data is fed into a model architecture to enable the model's training process. This might be text for Transformers or images for GANs (Generative Adversarial Networks).
During the training process, the model adjusts its internal parameters so that its output matches the patterns and structures of the data. As the model learns, its performance is monitored by observing a lowering loss on the training set, as well as improved predictions on a test set. Once the performance is no longer improving, the model is considered converged. It may then under-go further refinement, such as reinforcement-learning with human feedback (RLHF). Additional hyperparameters, such as learning rate or batch size, can be tuned to improve the rate of model learning. The process of building and customizing a model can be expedited by utilizing a framework that offers the necessary constructs and tooling, thereby simplifying adoption.
NVIDIA NeMo
NVIDIA NeMo is an open-source, end-to-end platform purpose-built for developing custom, enterprise-grade generative AI models. NeMo leverages NVIDIA’s state-of-the-art technology to facilitate a complete workflow from automated distributed data processing to training of large-scale bespoke models and finally, to deploy and serve using infrastructure in Google Cloud. NeMo is also available for enterprise-grade deployments with NVIDIA AI Enterprise software, available on Google Cloud Marketplace.
NeMo framework approaches building AI models using a modular design to encourage data scientists, ML engineers and developers to mix and match these core components:
- Data Curation: extract, deduplicate and filter information from datasets to generate high-quality training data
- Distributed Training: advanced parallelism of training models by spreading workloads across tens of thousands of compute nodes with NVIDIA graphics processing units (GPUs)
- Model Customization: adapt several foundational, pre-trained models to specific domains using techniques such as P-tuning, SFT (Supervised Fine Tuning), RLHF (Reinforcement Learning from Human Feedback)
- Deployment: seamless integration with NVIDIA Triton Inference Server to deliver high accuracy, low latency and high throughput results. NeMo framework provides guardrails to honor the safety and security requirements.
It enables organizations to foster innovation, optimize operational efficiency, and establish easy access to software frameworks to start the generative AI journey.
For those interested in deploying NeMo onto a HPC system that may include schedulers like the Slurm workload manager, we recommend using the ML Solution available through the Cloud HPC Toolkit.
Training at scale using GKE
Building and customizing models requires massive compute, quick access to memory and storage, and rapid networking. In addition, there are multiple demands across the infrastructure ranging from scaling large-sized models, efficient resource utilization, agility for faster iteration, fault tolerance and orchestrating distributed workloads.
GKE allows customers to have a more consistent and robust development process by having one platform for all their workloads. GKE as a foundation platform provides unmatched scalability, compatibility with a diverse set of hardware accelerators including NVIDIA GPUs, bringing the best of accelerator orchestration to help significantly improve performance and reduce costs.
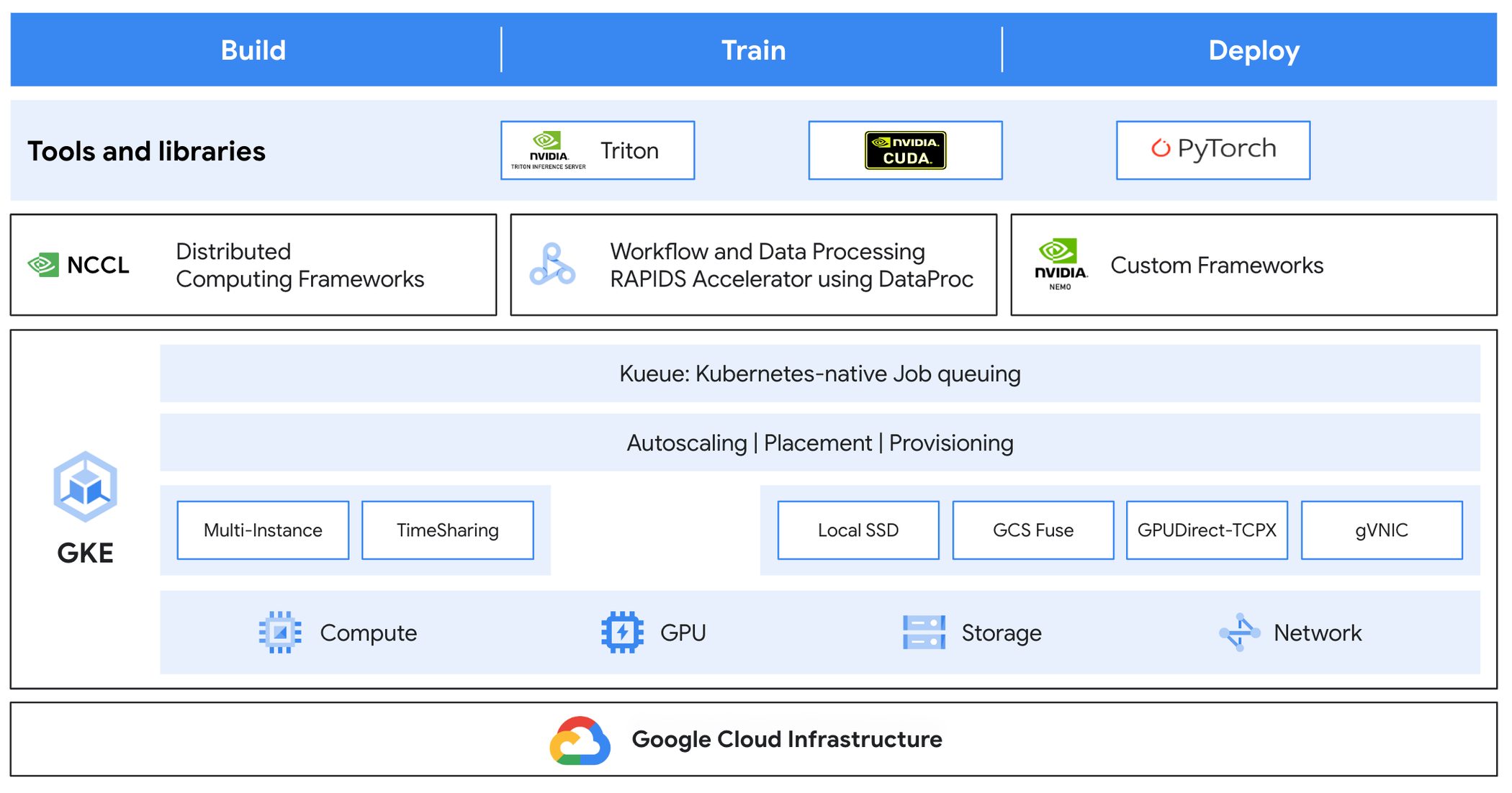
Let’s look at how GKE helps manage the underlying infrastructure with ease with the help of Figure 1:
-
Compute
-
Multi-Instance GPUs (MIG): partition a single NVIDIA H100 or A100 Tensor Core GPU into multiple instances so each has high-bandwidth memory, cache and compute cores
-
Time-sharing GPUs: single physical GPU node shared by multiple containers to efficiently use and save running costs
-
Storage
-
Local SSD: high throughput and I/O requirements
-
GCS Fuse: allow file-like operations on objects
-
Networking:
-
GPUDirect-TCPX NCCL plug-in: Transport layer plugin to enable direct GPU to NIC transfers during NCCL communication, improving network performance.
-
Google Virtual Network Interface Card (gVNIC): to increase network performance between GPU nodes
-
Queuing: Kubernetes native job queueing system to orchestrate job execution to completion in a resource-constrained environment.
GKE is widely embraced by communities including other ISVs (Independent Software Vendors) to land their tools, libraries and frameworks. GKE democratizes infrastructure by letting teams of different sizes to build, train and deploy AI models.
Solution architecture
The current industry trends in AI / ML space indicate that more computational power improves models significantly. GKE unleashes this very power of Google Cloud’s products and services along with NVIDIA GPUs to train and serve models with industry-leading scale.
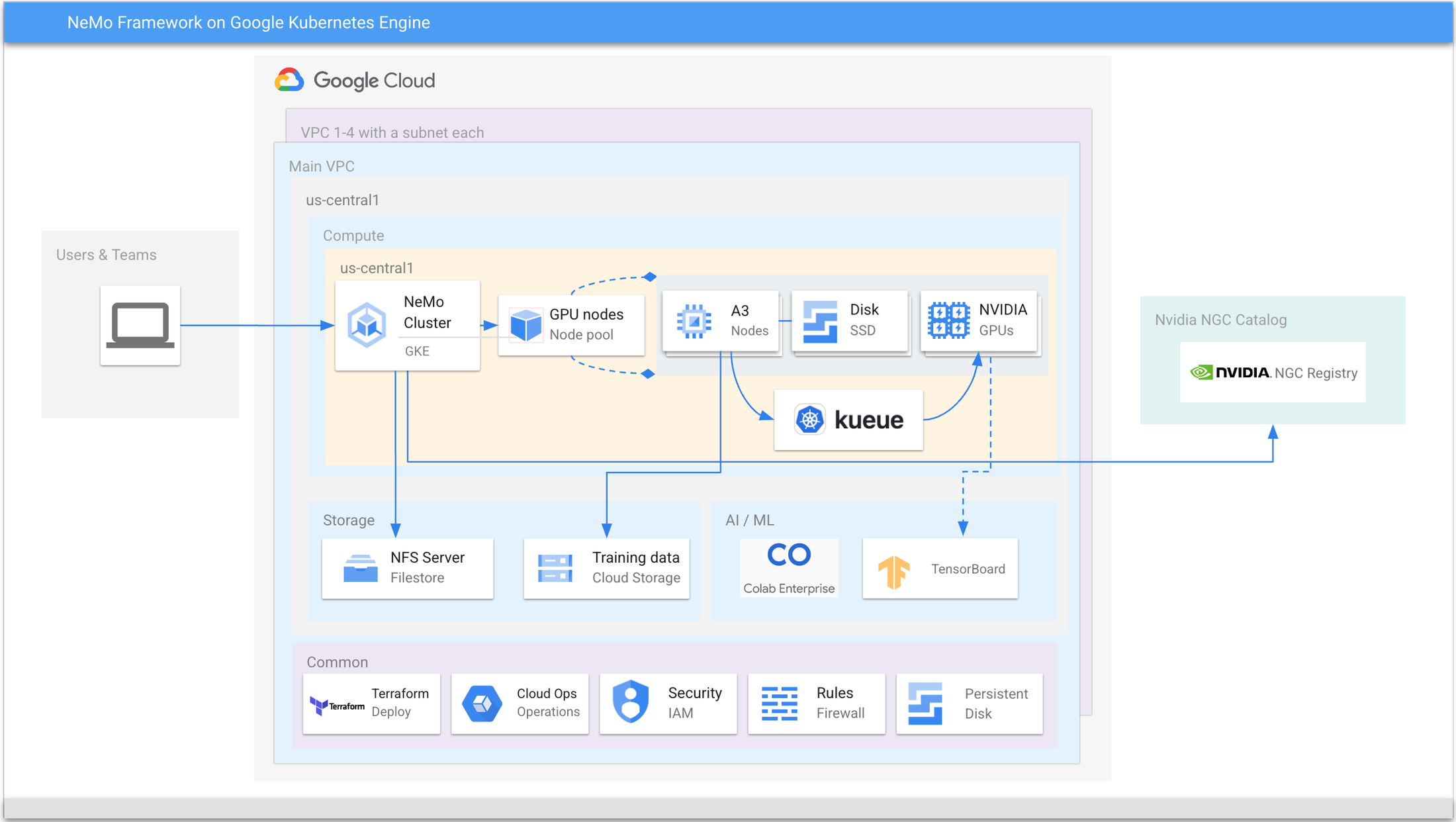
In Figure 2 above, the Reference Architecture illustrates the major components, tools and common services used to train the NeMo large language model using GKE.
-
A GKE Cluster set up as a regional or zonal location consisting of two node pools; a default node pool to manage common services such as DNS pods, custom controllers and a managed node pool with the A3 nodes to run the workloads.
-
A3 nodes, each with 16 local SSDs, 8x NVIDIA H100 Tensor Core GPUs and associated drivers. In each node, the CSI driver for Filestore CSI is enabled to access fully managed NFS storage and Cloud Storage FUSE to access Google Cloud Storage as a file system.
-
Kueue batching for workload management. This is recommended for a larger setup used by multiple teams.
-
Filestore mounted in each node to store outputs, interim, and final logs to view training performance.
-
A Cloud Storage bucket that contains the training data.
-
NVIDIA NGC hosts the NeMo framework’s training image.
-
Training logs mounted on Filestore can be viewed using TensorBoard to examine the training loss and training step times.
-
Common services such as Cloud Ops to view logs, IAM to manage security, and Terraform to deploy the entire setup.
An end-to-end walkthrough is available in a GitHub repository at https://github.com/GoogleCloudPlatform/nvidia-nemo-on-gke. The walkthrough provides detailed instructions to set up the above solution in a Google Cloud Project and pre-train NVIDIAs’ NeMo Megatron GPT using the NeMo framework.
Extend further
In scenarios where there are massive amounts of structured data, BigQuery is commonly used by enterprises as their central data warehousing platform. There are techniques to export data into Cloud Storage to train the model. If the data is not available in the intended form, Dataflow can be used to read, transform and write back the data to BigQuery.
Conclusion
By leveraging GKE, organizations can focus on developing and deploying their models to grow their business, without worrying about the underlying infrastructure. NVIDIA NeMo is highly suited to building custom generative AI models. This combination provides the scalability, reliability, and ease of use to train and serve models.
To learn more about GKE, click here. To understand more about NVIDIA NeMo, click here.
If you are coming to NVIDIA GTC, please see Google Cloud at booth #808 to see this in action.


