整合式超級運算架構
AI Hypercomputer
透過 AI 技術最佳化硬體、軟體和使用量,提高工作效率和效率。
網誌:Introducing Cloud TPUv5 and AI Hypercomputer (TPU v5p 和 AI 超級電腦隆重登場)

總覽
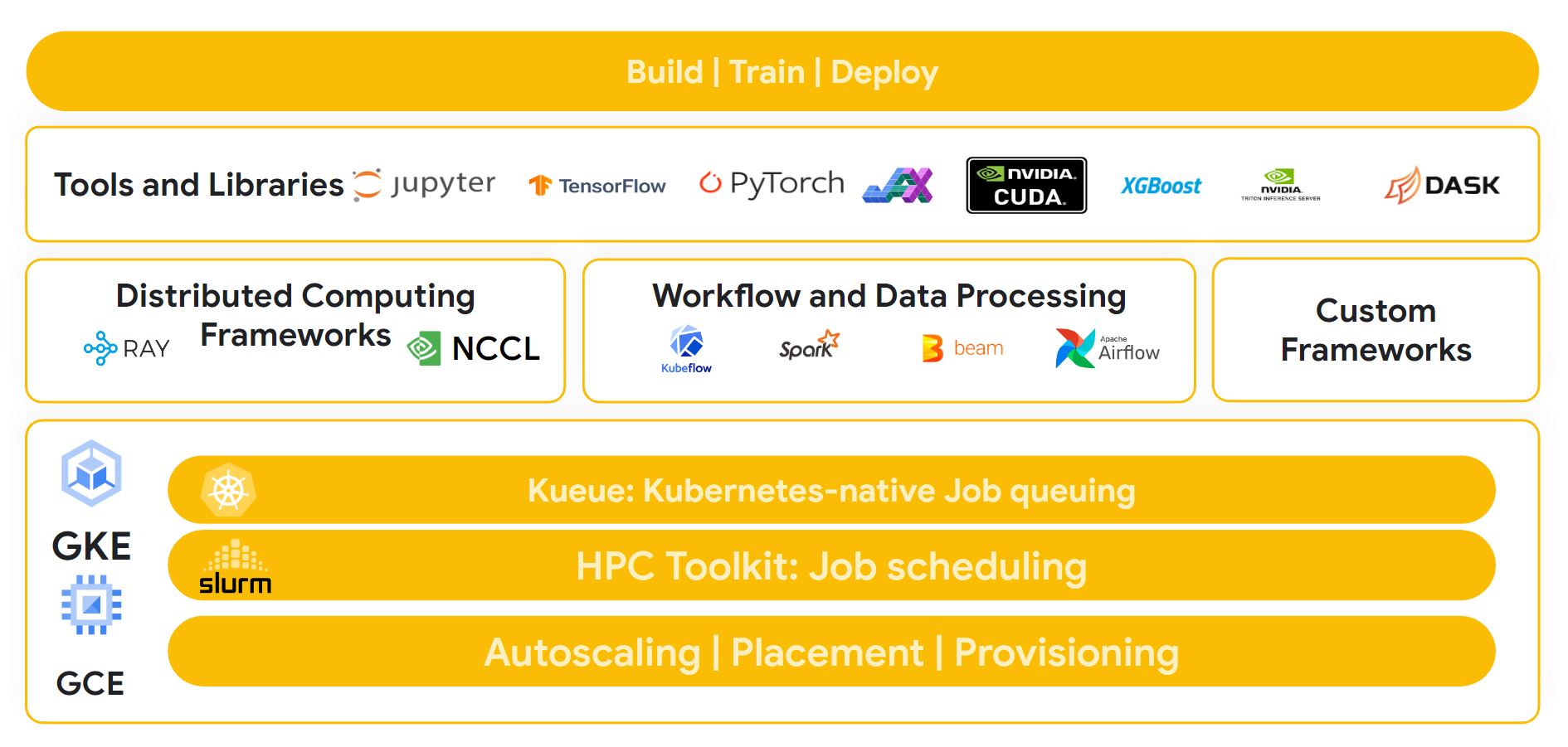
效能最佳化硬體
我們效能最佳的基礎架構包括 Google Cloud TPU、Google Cloud GPU、Google Cloud Storage 和基礎 Jupiter 網路,由於架構具備強大的擴充特性,能夠穩定地以最快時間訓練大規模的先進模型,為大型模型提供最佳成本效益。
開放軟體
我們的架構經過最佳化,支援最常見的工具和程式庫,例如 Tensorflow、Pytorch 和 JAX。此外,客戶還能使用 Cloud TPU Multislice 和 Multihost 設定等技術,以及 Google Kubernetes Engine 等代管服務。因此,客戶能為常見的工作負載提供立即可用的部署作業,例如 SLURM 自動化調度管理的 NVIDIA NeMO 架構。
靈活運用
運作方式
Google 發明 TensorFlow 等多項技術,是人工智慧領域的領導品牌。您知道嗎?您可以在自己的專案運用 Google 技術。瞭解 Google 在創新 AI 基礎架構領域的歷程,以及如何將這項技術用於工作負載。
Google 發明 TensorFlow 等多項技術,是人工智慧領域的領導品牌。您知道嗎?您可以在自己的專案運用 Google 技術。瞭解 Google 在創新 AI 基礎架構領域的歷程,以及如何將這項技術用於工作負載。

常見用途
執行大規模 AI 訓練作業
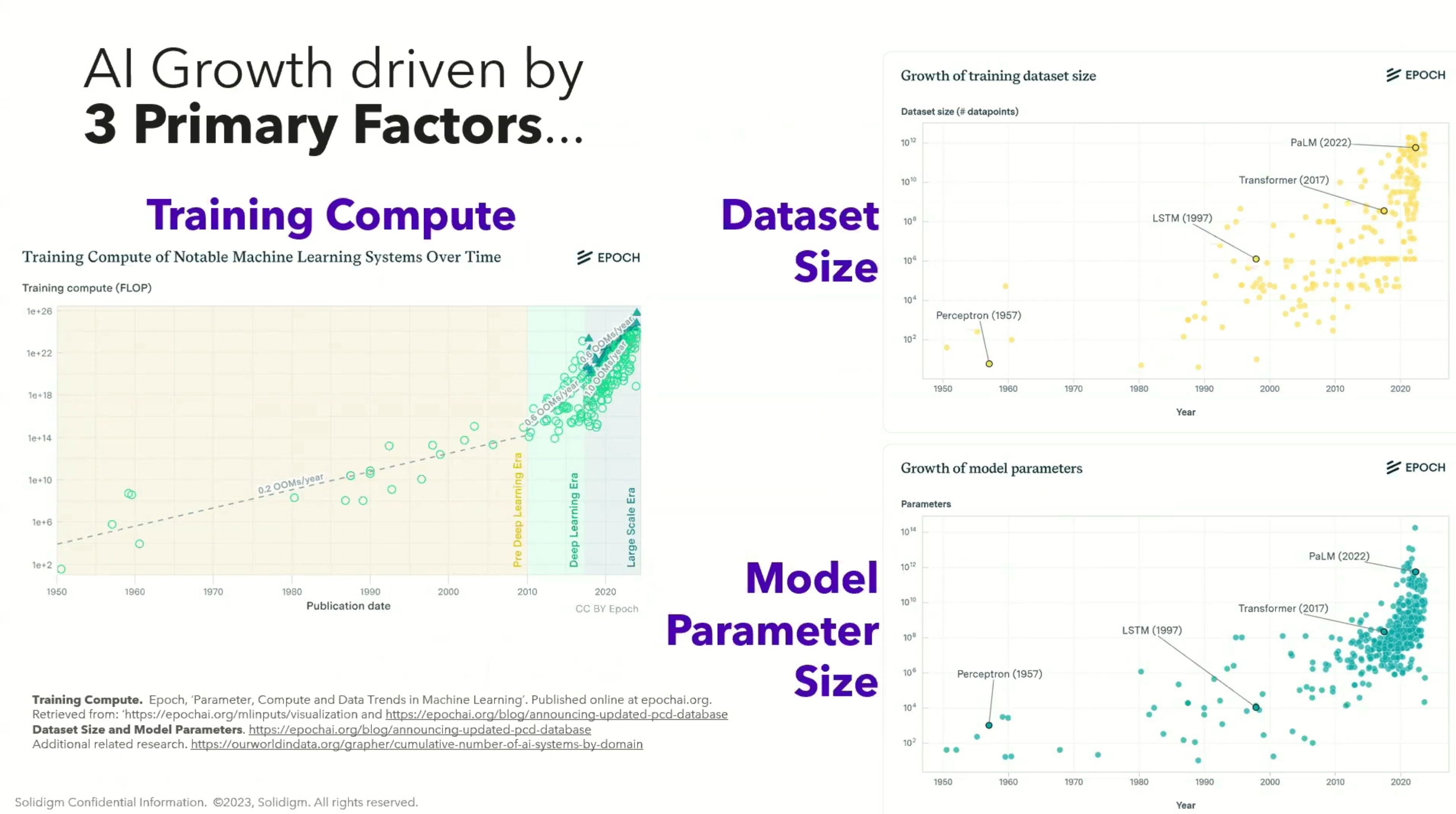
強大、可擴充且高效的 AI 訓練
運用 ML Productivity Goodput,以 Google 技術評估大規模訓練的成效。
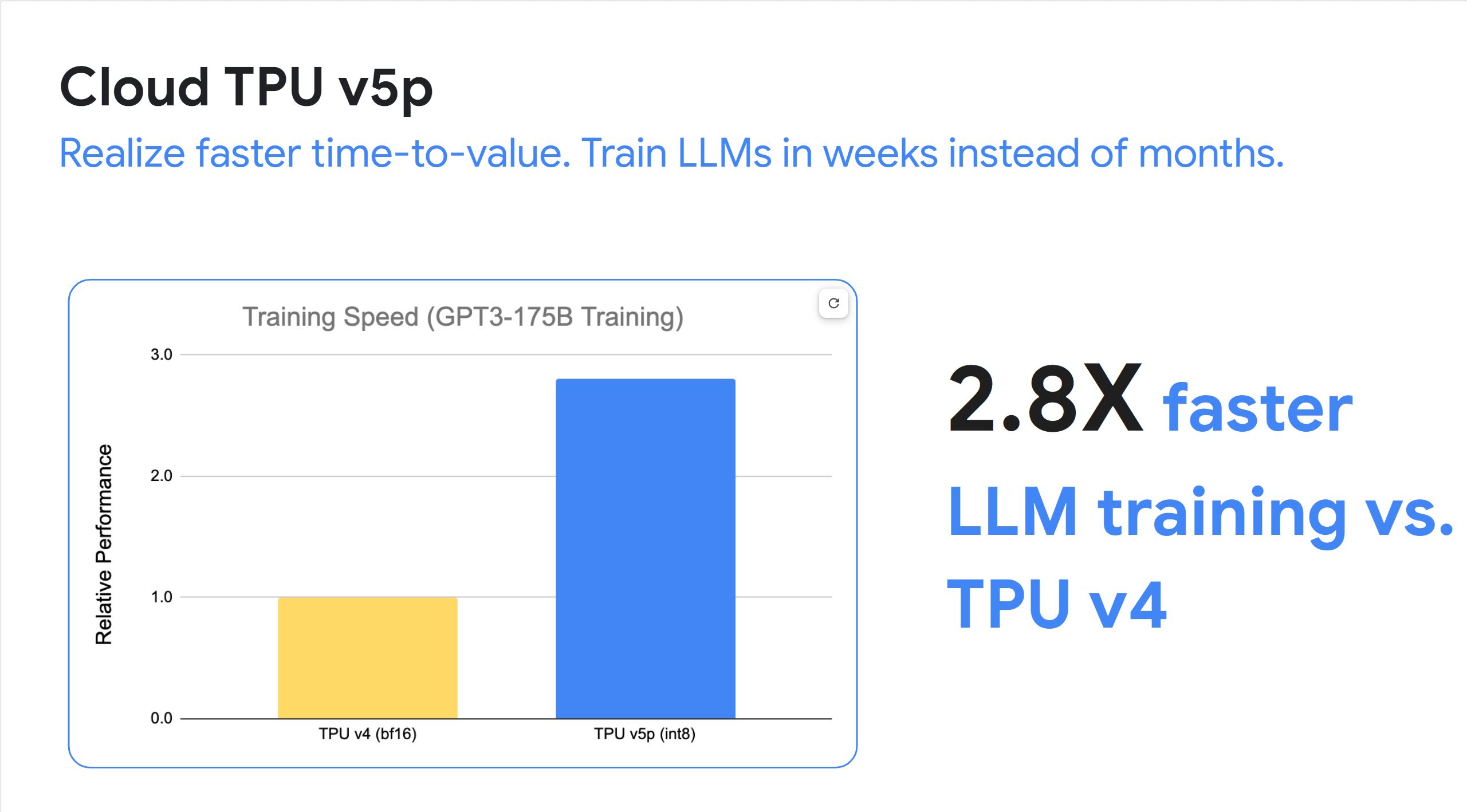
Character.AI 運用 Google Cloud 擴大規模
「我們需要 GPU 生成對使用者訊息的回應。隨著平台使用者越來越多,我們也需要更多 GPU 來提供服務。透過 Google Cloud,我們可以進行實驗並找出適合特定工作負載的平台。這些解決方案讓我們能夠更靈活地選擇最有價值的解決方案。」Character.AI 創始工程師 Myle Ott




操作說明
其他資源
強大、可擴充且高效的 AI 訓練
運用 ML Productivity Goodput,以 Google 技術評估大規模訓練的成效。
客戶實例
Character.AI 運用 Google Cloud 擴大規模
「我們需要 GPU 生成對使用者訊息的回應。隨著平台使用者越來越多,我們也需要更多 GPU 來提供服務。透過 Google Cloud,我們可以進行實驗並找出適合特定工作負載的平台。這些解決方案讓我們能夠更靈活地選擇最有價值的解決方案。」Character.AI 創始工程師 Myle Ott
提供 AI 技術輔助應用程式
運用開放架構提供有 AI 技術輔助的體驗
Google Cloud 致力確保開放架構在 AI 超級電腦架構中順利運作。
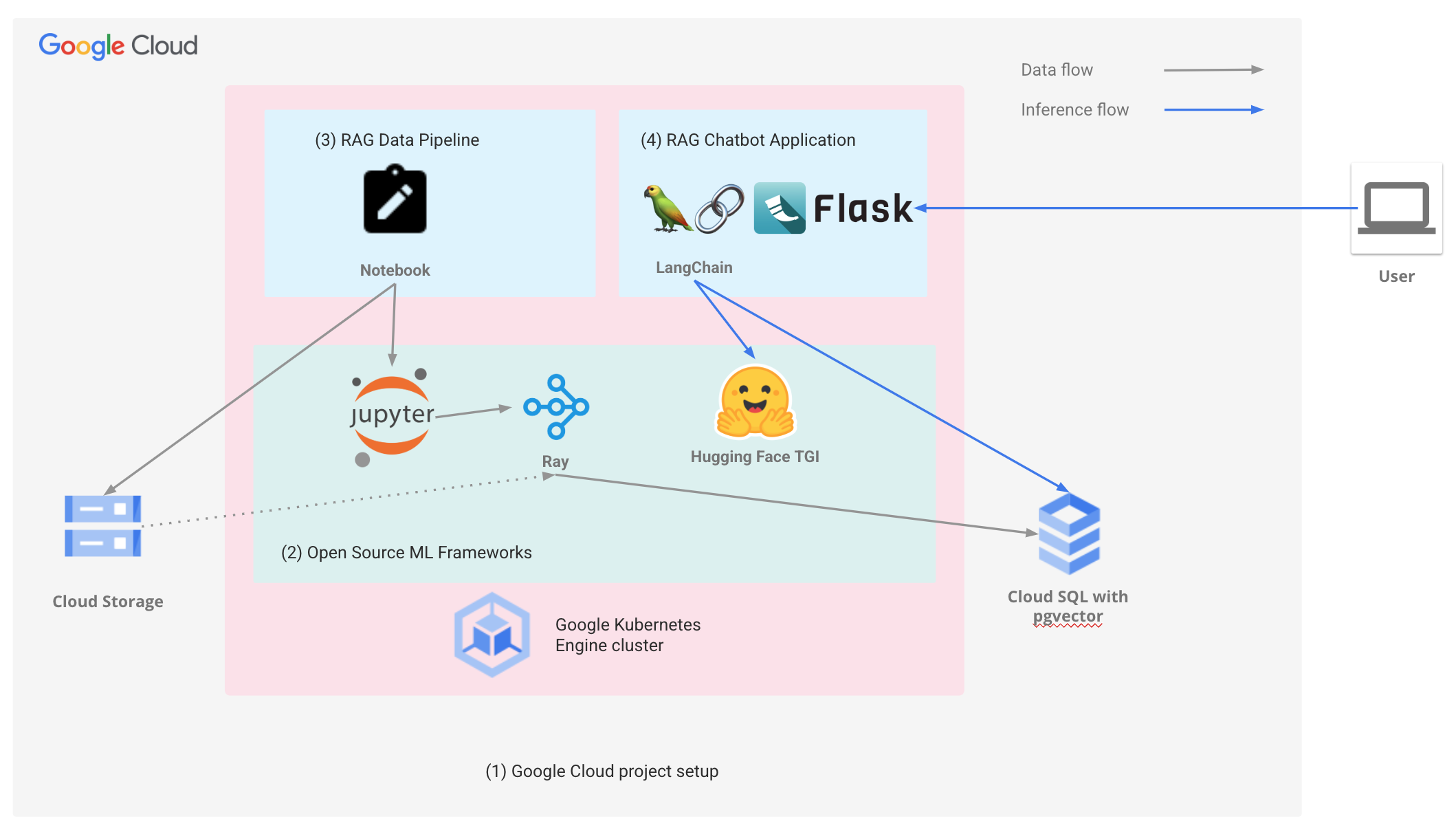
運用開放架構提供有 AI 技術輔助的體驗
藉助 Google Cloud 的開放式軟體生態系統,您可以透過最慣用的架構和工具建構應用程式,同時享有 AI 超級電腦架構的成本效益優勢。
Priceline:協助旅客收集獨特體驗
與 Google Cloud 合作導入生成式 AI 後,我們用聊天機器人就能提供個人化旅遊規劃服務。我們的目標不只是為顧客安排行程,更是協助他們打造獨一無二的旅遊體驗。」Martin Brodbeck,Priceline 技術長




操作說明
運用開放架構提供有 AI 技術輔助的體驗
Google Cloud 致力確保開放架構在 AI 超級電腦架構中順利運作。
其他資源
運用開放架構提供有 AI 技術輔助的體驗
藉助 Google Cloud 的開放式軟體生態系統,您可以透過最慣用的架構和工具建構應用程式,同時享有 AI 超級電腦架構的成本效益優勢。
客戶實例
Priceline:協助旅客收集獨特體驗
與 Google Cloud 合作導入生成式 AI 後,我們用聊天機器人就能提供個人化旅遊規劃服務。我們的目標不只是為顧客安排行程,更是協助他們打造獨一無二的旅遊體驗。」Martin Brodbeck,Priceline 技術長
以符合成本效益的方式大規模提供模型
以更具成本效益的方式大規模提供 AI
Google Cloud 提供領先業界的 AI 模型成本效益/效能,以及加速器選項,可滿足任何工作負載需求。
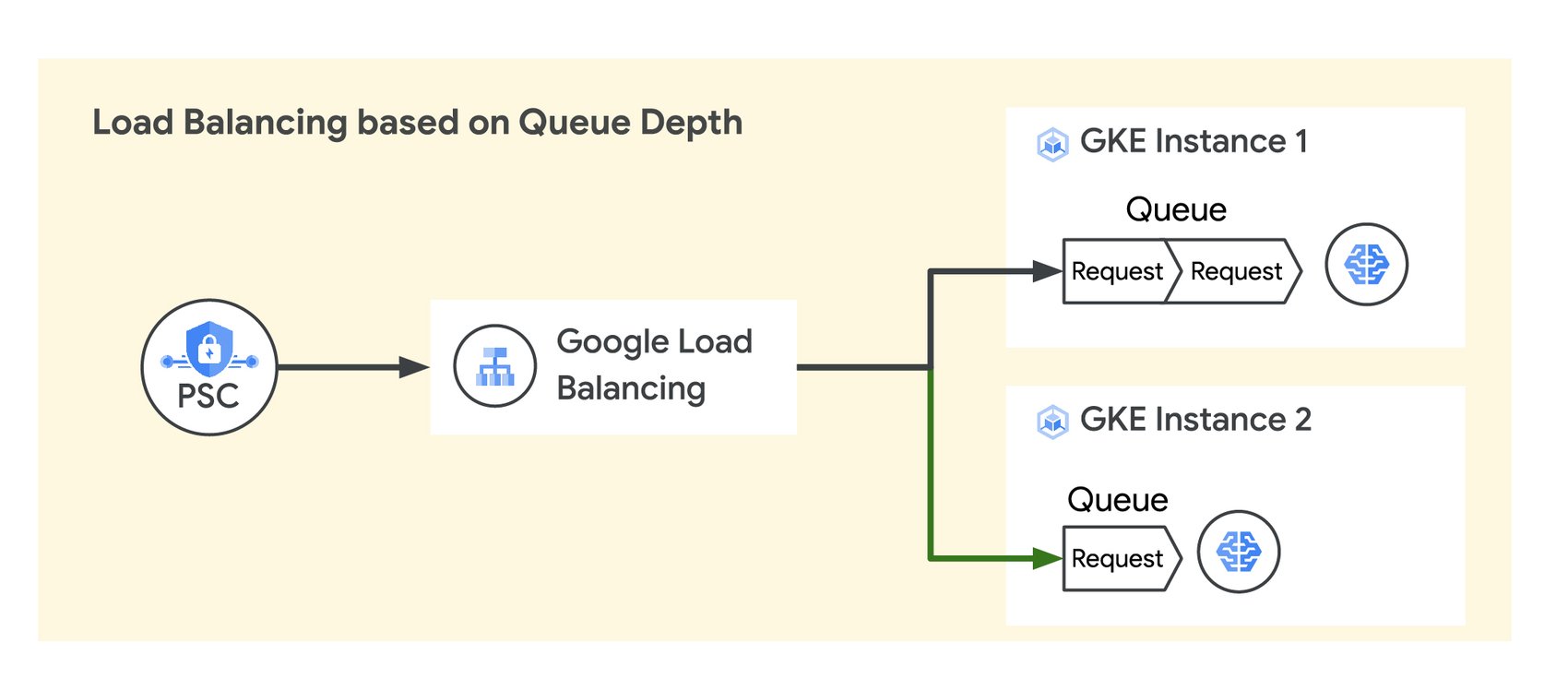
以更具成本效益的方式大規模提供 AI
搭載 NVIDIA L4 GPU 的 Cloud TPU v5e 和 G2 VM 執行個體可為多種 AI 工作負載提供高效能及符合成本效益的推論服務,包括最新的 LLM 和生成式 AI 模型。這兩項產品能大幅提高成本效益,成果遠勝於先前的模型。再加上 Google Cloud 的 AI 超級電腦架構,客戶得以擴大部署規模,成為業界領先的佼佼者。
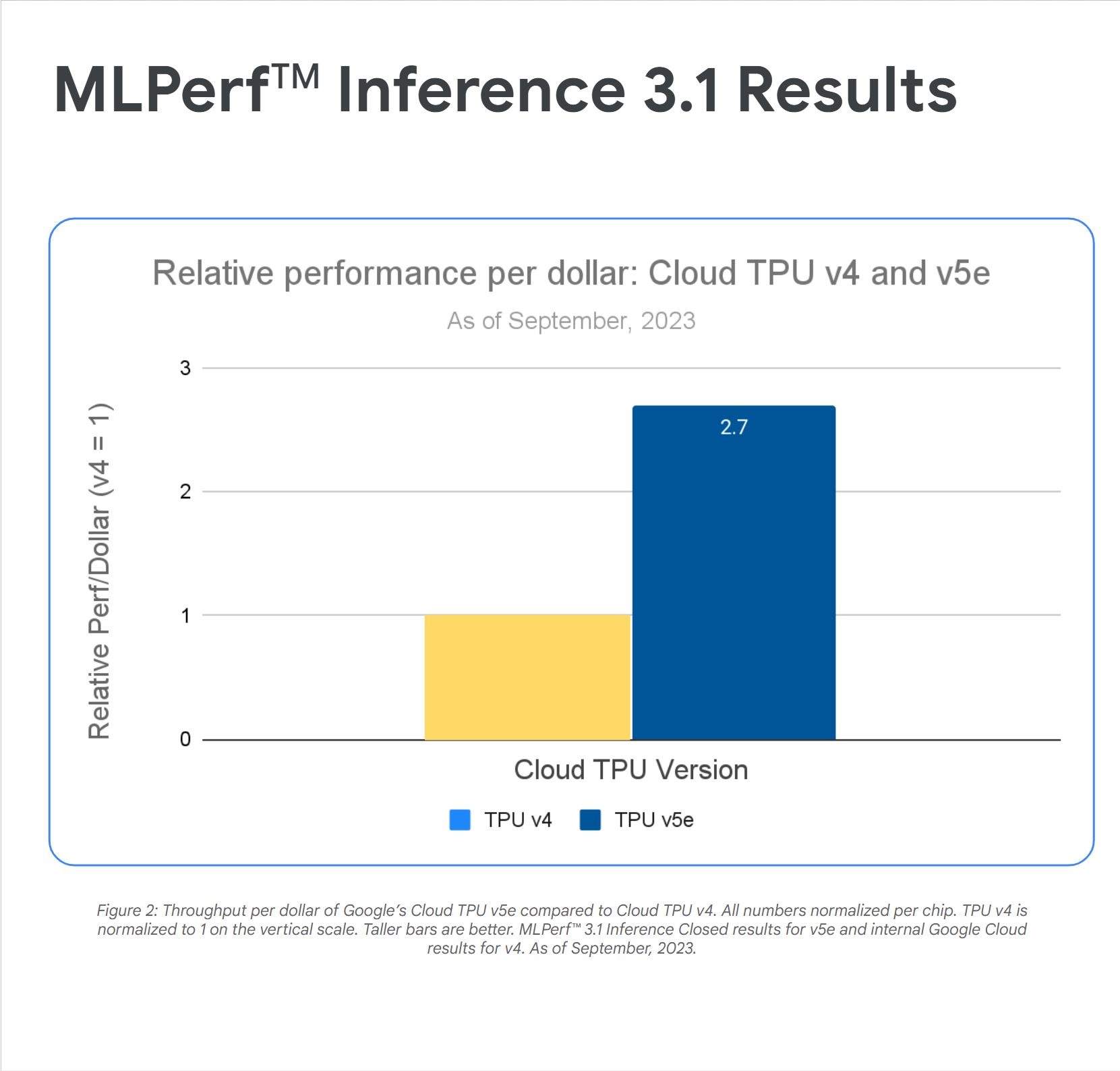

AssemblyAI 運用 Google Cloud 提高成本效益
「我們的實驗結果顯示,Cloud TPU v5e 是最符合成本效益的加速器,可針對模型執行大規模推論。每一美元的效能比 G2 高出 2.7 倍,比 A2 執行個體高出 4.2 倍。」Domenic Donato
AssemblyAI 技術副總裁


操作說明
以更具成本效益的方式大規模提供 AI
Google Cloud 提供領先業界的 AI 模型成本效益/效能,以及加速器選項,可滿足任何工作負載需求。
其他資源
以更具成本效益的方式大規模提供 AI
搭載 NVIDIA L4 GPU 的 Cloud TPU v5e 和 G2 VM 執行個體可為多種 AI 工作負載提供高效能及符合成本效益的推論服務,包括最新的 LLM 和生成式 AI 模型。這兩項產品能大幅提高成本效益,成果遠勝於先前的模型。再加上 Google Cloud 的 AI 超級電腦架構,客戶得以擴大部署規模,成為業界領先的佼佼者。
客戶實例
AssemblyAI 運用 Google Cloud 提高成本效益
「我們的實驗結果顯示,Cloud TPU v5e 是最符合成本效益的加速器,可針對模型執行大規模推論。每一美元的效能比 G2 高出 2.7 倍,比 A2 執行個體高出 4.2 倍。」Domenic Donato
AssemblyAI 技術副總裁











