
Cet article explore l'API WebGPU expérimentale à l'aide d'exemples et vous aide à commencer à effectuer des calculs parallèles de données à l'aide du GPU.

Contexte
Comme vous le savez peut-être déjà, le processeur graphique (GPU) est un sous-système électronique d'un ordinateur qui était à l'origine spécialisé dans le traitement des graphiques. Cependant, au cours des 10 dernières années, il a évolué vers une architecture plus flexible, permettant aux développeurs de mettre en œuvre de nombreux types d'algorithmes, et pas seulement de rendre des graphiques 3D, tout en tirant parti de l'architecture unique du GPU. Ces fonctionnalités sont appelées calcul GPU. L'utilisation d'un GPU en tant que coprocesseur pour le calcul scientifique à usage général s'appelle la programmation GPU à usage général (GPGPU, general-purpose GPU).
Le calcul GPU a contribué de manière significative au boom récent du machine learning, car les réseaux de neurones convolutifs et d'autres modèles peuvent tirer parti de l'architecture pour s'exécuter plus efficacement sur les GPU. La plate-forme Web actuelle ne disposant pas de capacités de calcul GPU, le groupe de la communauté "GPU for the Web" du W3C conçoit une API pour exposer les API GPU modernes disponibles sur la plupart des appareils actuels. Cette API s'appelle WebGPU.
WebGPU est une API de bas niveau, comme WebGL. Il est très puissant et assez verbeux, comme vous le verrez. Mais ce n'est pas grave. Nous recherchons des performances.
Dans cet article, je vais me concentrer sur la partie GPU Compute de WebGPU. Pour être honnête, je ne vais qu'effleurer la surface afin que vous puissiez commencer à jouer par vous-même. Je vais approfondir le sujet et traiter du rendu WebGPU (canevas, texture, etc.) dans de prochains articles.
Accéder au GPU
L'accès au GPU est facile dans WebGPU. L'appel de navigator.gpu.requestAdapter() renvoie une promesse JavaScript qui se résout de manière asynchrone avec un adaptateur GPU. Considérez cette carte comme la carte graphique. Il peut être intégré (sur le même chip que le processeur) ou distinct (généralement une carte PCIe plus performante, mais qui consomme plus d'énergie).
Une fois que vous disposez de l'adaptateur GPU, appelez adapter.requestDevice() pour obtenir une promesse qui se résout avec un appareil GPU que vous utiliserez pour effectuer des calculs GPU.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
Les deux fonctions acceptent des options qui vous permettent d'être précis sur le type d'adaptateur (préférence d'alimentation) et d'appareil (extensions, limites) que vous souhaitez. Par souci de simplicité, nous utiliserons les options par défaut dans cet article.
Écrire dans la mémoire tampon
Voyons comment utiliser JavaScript pour écrire des données dans la mémoire du GPU. Ce processus n'est pas simple en raison du modèle de bac à sable utilisé dans les navigateurs Web modernes.
L'exemple ci-dessous montre comment écrire quatre octets dans la mémoire tampon accessible depuis le GPU. Elle appelle device.createBuffer(), qui prend la taille du tampon et son utilisation. Même si l'indicateur d'utilisation GPUBufferUsage.MAP_WRITE n'est pas obligatoire pour cet appel spécifique, précisons que nous souhaitons écrire dans ce tampon. Un objet de tampon GPU est mappé lors de la création grâce à mappedAtCreation défini sur "true". Le tampon de données binaires brutes associé peut ensuite être récupéré en appelant la méthode de tampon GPU getMappedRange().
L'écriture d'octets est familière si vous avez déjà utilisé ArrayBuffer. Utilisez un TypedArray et copiez-y les valeurs.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
À ce stade, le tampon du GPU est mappé, ce qui signifie qu'il appartient au processeur et qu'il est accessible en lecture/écriture depuis JavaScript. Pour que le GPU puisse y accéder, il doit être désapprouvé, ce qui se fait aussi simplement qu'en appelant gpuBuffer.unmap().
Le concept de mappage/non-mappage est nécessaire pour éviter les conditions de concurrence où le GPU et le processeur accèdent à la mémoire en même temps.
Lire la mémoire tampon
Voyons maintenant comment copier un tampon GPU dans un autre tampon GPU et le lire.
Étant donné que nous écrivons dans le premier tampon GPU et que nous voulons le copier dans un deuxième tampon GPU, un nouveau flag d'utilisation GPUBufferUsage.COPY_SRC est requis. Le deuxième tampon de GPU est créé dans un état non mappé cette fois avec device.createBuffer(). Son indicateur d'utilisation est GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ, car il sera utilisé comme destination du premier tampon de GPU et lu en JavaScript une fois les commandes de copie GPU exécutées.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
Étant donné que le GPU est un coprocesseur indépendant, toutes les commandes GPU sont exécutées de manière asynchrone. C'est pourquoi il existe une liste de commandes GPU compilées et envoyées par lots en cas de besoin. Dans WebGPU, l'encodeur de commandes GPU renvoyé par device.createCommandEncoder() est l'objet JavaScript qui crée un lot de commandes "en mémoire tampon" qui seront envoyées au GPU à un moment donné. En revanche, les méthodes sur GPUBuffer ne sont pas mises en mémoire tampon, ce qui signifie qu'elles s'exécutent de manière atomique au moment où elles sont appelées.
Une fois que vous disposez de l'encodeur de commande GPU, appelez copyEncoder.copyBufferToBuffer() comme indiqué ci-dessous pour ajouter cette commande à la file d'attente de commandes en vue de son exécution ultérieure.
Enfin, terminez l'encodage des commandes en appelant copyEncoder.finish() et en les envoyant à la file d'attente de commandes de l'appareil GPU. La file d'attente est chargée de gérer les envois effectués via device.queue.submit() avec les commandes GPU en tant qu'arguments.
Cela exécutera de manière atomique toutes les commandes stockées dans le tableau dans l'ordre.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(
gpuWriteBuffer /* source buffer */,
0 /* source offset */,
gpuReadBuffer /* destination buffer */,
0 /* destination offset */,
4 /* size */
);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
À ce stade, les commandes de file d'attente GPU ont été envoyées, mais pas nécessairement exécutées.
Pour lire le deuxième tampon de GPU, appelez gpuReadBuffer.mapAsync() avec GPUMapMode.READ. Il renvoie une promesse qui se résout lorsque le tampon du GPU est mappé. Ensuite, obtenez la plage mappée avec gpuReadBuffer.getMappedRange() qui contient les mêmes valeurs que le premier tampon GPU une fois toutes les commandes GPU mises en file d'attente exécutées.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
Vous pouvez essayer cet exemple.
En bref, voici ce que vous devez retenir concernant les opérations de la mémoire tampon:
- Les tampons GPU doivent être désapposés pour être utilisés dans l'envoi de la file d'attente de l'appareil.
- Lorsqu'ils sont mappés, les tampons GPU peuvent être lus et écrits en JavaScript.
- Les tampons GPU sont mappés lorsque
mapAsync()etcreateBuffer()avecmappedAtCreationdéfini sur "true" sont appelés.
Programmation de nuanceurs
Les programmes exécutés sur le GPU qui n'effectuent que des calculs (et ne dessinent pas de triangles) sont appelés nuanceurs de calcul. Ils sont exécutés en parallèle par des centaines de cœurs de GPU (qui sont plus petits que les cœurs de processeur) qui fonctionnent ensemble pour traiter les données. Leur entrée et leur sortie sont des tampons dans WebGPU.
Pour illustrer l'utilisation des nuanceurs de calcul dans WebGPU, nous allons jouer avec la multiplication matricielle, un algorithme de machine learning courant ci-dessous.

En résumé, voici ce que nous allons faire:
- Créez trois tampons GPU (deux pour les matrices à multiplier et un pour la matrice de résultat).
- Décrire l'entrée et la sortie du nuanceur de calcul
- Compiler le code du nuanceur de calcul
- Configurer un pipeline de calcul
- Envoyer les commandes encodées au GPU par lot
- Lire le tampon GPU de la matrice des résultats
Création de tampons GPU
Par souci de simplicité, les matrices seront représentées sous la forme d'une liste de nombres à virgule flottante. Le premier élément correspond au nombre de lignes, le deuxième au nombre de colonnes, et le reste aux nombres réels de la matrice.

Les trois tampons GPU sont des tampons de stockage, car nous devons stocker et récupérer des données dans le nuanceur de calcul. C'est pourquoi les indicateurs d'utilisation des tampons GPU incluent GPUBufferUsage.STORAGE pour tous. L'indicateur d'utilisation de la matrice de résultats comporte également GPUBufferUsage.COPY_SRC, car il sera copié dans un autre tampon pour la lecture une fois toutes les commandes de file d'attente du GPU exécutées.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
Mise en forme du groupe de liaisons et groupe de liaisons
Les concepts de mise en page de groupe de liaison et de groupe de liaison sont spécifiques à WebGPU. Une mise en page de groupe de liaison définit l'interface d'entrée/sortie attendue par un nuanceur, tandis qu'un groupe de liaison représente les données d'entrée/sortie réelles d'un nuanceur.
Dans l'exemple ci-dessous, la mise en page du groupe de liaisons attend deux tampons de stockage en lecture seule avec les liaisons d'entrée numérotées 0 et 1, et un tampon de stockage à 2 pour le nuanceur de calcul.
En revanche, le groupe de liaison, défini pour cette mise en page de groupe de liaison, associe des tampons GPU aux entrées: gpuBufferFirstMatrix à la liaison 0, gpuBufferSecondMatrix à la liaison 1 et resultMatrixBuffer à la liaison 2.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: gpuBufferFirstMatrix
}
},
{
binding: 1,
resource: {
buffer: gpuBufferSecondMatrix
}
},
{
binding: 2,
resource: {
buffer: resultMatrixBuffer
}
}
]
});
Code du nuanceur de calcul
Le code du nuanceur de calcul pour la multiplication de matrices est écrit en WGSL, le langage de nuanceur WebGPU, qui se traduit facilement en SPIR-V. Sans entrer dans les détails, vous trouverez ci-dessous les trois tampons de stockage identifiés par var<storage>. Le programme utilisera firstMatrix et secondMatrix comme entrées et resultMatrix comme sortie.
Notez que chaque tampon de stockage utilise une décoration binding qui correspond au même indice défini dans les mises en page de groupe de liaisons et les groupes de liaisons déclarés ci-dessus.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
Configuration du pipeline
Le pipeline de calcul est l'objet qui décrit réellement l'opération de calcul que nous allons effectuer. Créez-le en appelant device.createComputePipeline().
Il prend deux arguments: la mise en page du groupe de liaison que nous avons créée précédemment et une étape de calcul définissant le point d'entrée de notre nuanceur de calcul (la fonction WGSL main) et le module de nuanceur de calcul créé avec device.createShaderModule().
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule,
entryPoint: "main"
}
});
Envoi de commandes
Après avoir instancié un groupe de liaisons avec nos trois tampons GPU et un pipeline de calcul avec une structure de groupe de liaisons, il est temps de les utiliser.
Commençons par un encodeur pour une carte de calcul programmable avec commandEncoder.beginComputePass(). Nous l'utiliserons pour encoder les commandes GPU qui effectueront la multiplication matricielle. Définissez son pipeline avec passEncoder.setPipeline(computePipeline) et son groupe de liaison à l'indice 0 avec passEncoder.setBindGroup(0, bindGroup). L'index 0 correspond à la décoration group(0) dans le code WGSL.
Voyons maintenant comment ce nuanceur de calcul s'exécute sur le GPU. Notre objectif est d'exécuter ce programme en parallèle pour chaque cellule de la matrice de résultats, étape par étape. Par exemple, pour une matrice de résultats de taille 16 x 32, pour encoder la commande d'exécution sur un @workgroup_size(8, 8), nous appellerions passEncoder.dispatchWorkgroups(2, 4) ou passEncoder.dispatchWorkgroups(16 / 8, 32 / 8).
Le premier argument "x" correspond à la première dimension, le deuxième "y" à la deuxième dimension et le dernier "z" à la troisième dimension, qui est définie par défaut sur 1, car nous n'en avons pas besoin ici.
Dans le monde du calcul GPU, l'encodage d'une commande pour exécuter une fonction de noyau sur un ensemble de données s'appelle le dispatching.
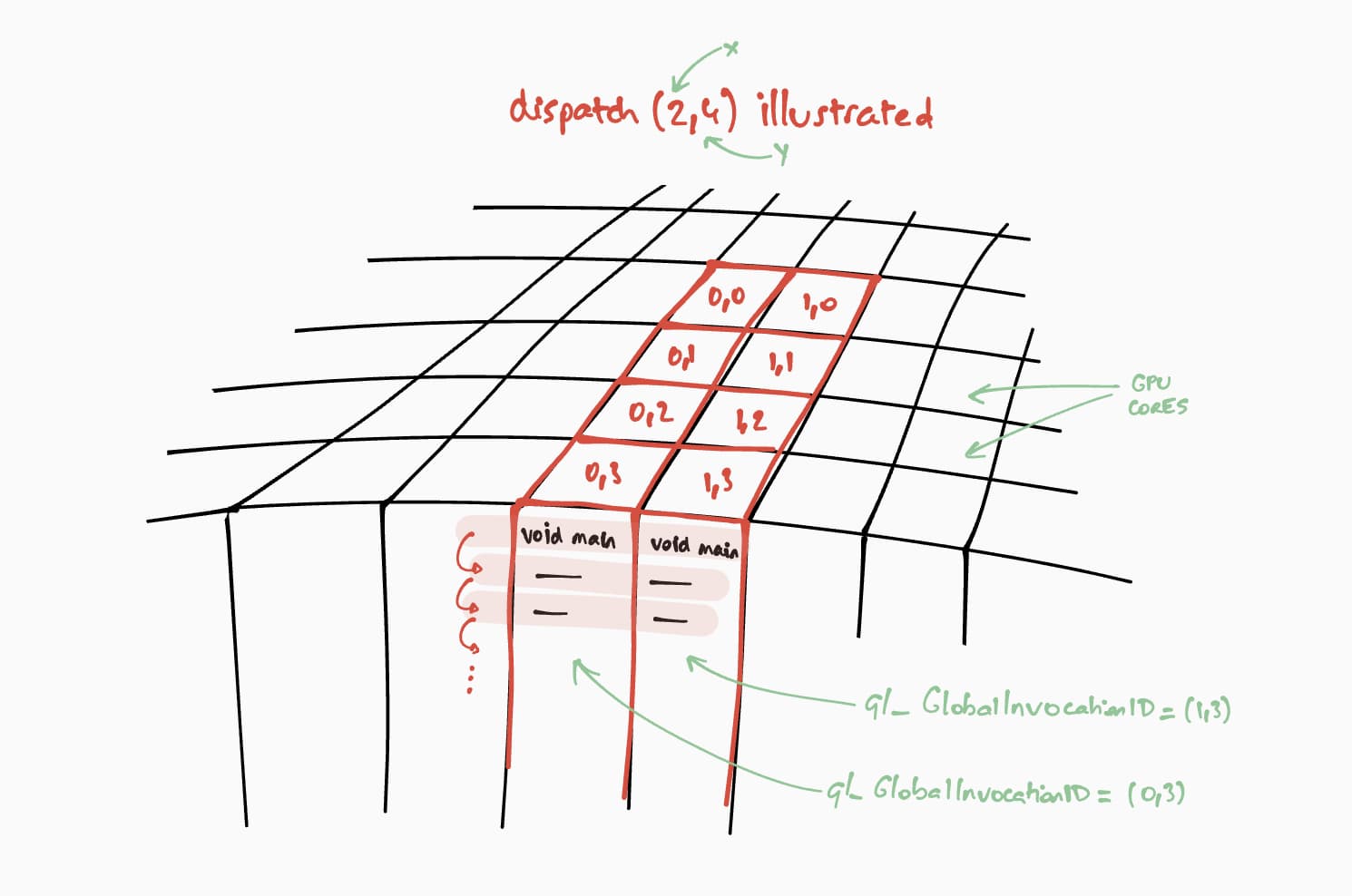
La taille de la grille du groupe de travail pour notre nuanceur de calcul est (8, 8) dans notre code WGSL. Par conséquent, "x" et "y", qui correspondent respectivement au nombre de lignes de la première matrice et au nombre de colonnes de la deuxième matrice, seront divisés par 8. Nous pouvons maintenant distribuer un appel de calcul avec passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8). Le nombre de grilles de groupe de travail à exécuter correspond aux arguments dispatchWorkgroups().
Comme indiqué dans le dessin ci-dessus, chaque nuanceur aura accès à un objet builtin(global_invocation_id) unique qui permettra de savoir quelle cellule de la matrice de résultats calculer.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
Pour arrêter l'encodeur de carte de calcul, appelez passEncoder.end(). Créez ensuite un tampon GPU à utiliser comme destination pour copier le tampon de matrice de résultats avec copyBufferToBuffer. Enfin, terminez l'encodage des commandes avec copyEncoder.finish() et envoyez-les à la file d'attente de l'appareil GPU en appelant device.queue.submit() avec les commandes GPU.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(
resultMatrixBuffer /* source buffer */,
0 /* source offset */,
gpuReadBuffer /* destination buffer */,
0 /* destination offset */,
resultMatrixBufferSize /* size */
);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
Lire la matrice de résultats
Lire la matrice de résultats est aussi simple que d'appeler gpuReadBuffer.mapAsync() avec GPUMapMode.READ et d'attendre la résolution de la promesse renvoyée, ce qui indique que le tampon GPU est maintenant mappé. À ce stade, il est possible d'obtenir la plage mappée avec gpuReadBuffer.getMappedRange().

Dans notre code, le résultat enregistré dans la console JavaScript DevTools est "2, 2, 50, 60, 114, 140".
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
Félicitations ! C'est fait ! Vous pouvez jouer avec le Sample.
Une dernière astuce
Pour faciliter la lecture de votre code, vous pouvez utiliser la méthode pratique getBindGroupLayout du pipeline de calcul pour déduire la mise en page du groupe de liaisons à partir du module de nuanceur. Cette astuce vous évite de créer une mise en forme de groupe de liaisons personnalisée et de spécifier une mise en forme de pipeline dans votre pipeline de calcul, comme vous pouvez le voir ci-dessous.
Une illustration de getBindGroupLayout pour l'exemple précédent est disponible.
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
Résultats sur les performances
Quelle est la différence entre l'exécution de la multiplication matricielle sur un GPU et sur un CPU ? Pour le savoir, j'ai écrit le programme que je viens de décrire pour un processeur. Comme vous pouvez le voir dans le graphique ci-dessous, utiliser toute la puissance du GPU semble être un choix évident lorsque la taille des matrices est supérieure à 256 x 256.

Cet article n'est que le début de mon exploration de WebGPU. D'autres articles seront bientôt publiés sur le calcul GPU et sur le fonctionnement du rendu (canevas, texture, échantillonneur) dans WebGPU.