
W tym artykule za pomocą przykładów omawiamy eksperymentalny interfejs WebGPU API i pomagamy Ci zacząć wykonywać obliczenia równoległe danych za pomocą karty graficznej.

Tło
Jak już pewnie wiesz, Graphic Processing Unit (GPU) to elektroniczny podsystem komputera, który pierwotnie wyspecjalizował się w przetwarzaniu grafiki. Jednak w ciągu ostatnich 10 lat ewoluowała w kierunku bardziej elastycznej architektury, która pozwala deweloperom wdrażać wiele typów algorytmów, a nie tylko renderować grafikę 3D, korzystając przy tym z wyjątkowej architektury GPU. Te możliwości są określane jako obliczanie na GPU, a korzystanie z GPU jako procesora pomocniczego do ogólnego przetwarzania naukowego nazywa się programowaniem GPU ogólnego przeznaczenia (GPGPU).
Procesory GPU przyczyniły się do ostatniego boomu w dziedzinie uczenia maszynowego, ponieważ konwolucyjne sieci neuronowe i inne modele mogą korzystać z architektury, aby działać wydajniej na procesorach GPU. Obecna platforma internetowa nie ma możliwości obliczeń GPU, dlatego grupa społeczności „GPU for the Web” w W3C opracowuje interfejs API, który udostępnia nowoczesne interfejsy API GPU dostępne na większości obecnych urządzeń. Ten interfejs API nazywa się WebGPU.
WebGPU to niskopoziomowy interfejs API, podobnie jak WebGL. Jak widać, jest ono bardzo skuteczne i dokładne. To nie problem. Interesuje nas skuteczność reklam.
W tym artykule skupię się na części WebGPU dotyczącej przetwarzania przez GPU. Szczerze mówiąc, tylko troszeczkę zagłębię się w tą tematykę, abyś mógł/mogła zacząć samodzielnie eksperymentować. W przyszłych artykułach zajmę się bardziej szczegółowo tematem renderowania WebGPU (płótna, tekstur itp.).
Dostęp do GPU
W WebGPU dostęp do GPU jest łatwy. Wywołanie funkcji navigator.gpu.requestAdapter() zwraca obietnicę JavaScript, która zostanie rozwiązana asynchronicznie za pomocą adaptera GPU. Możesz traktować ten adapter jak kartę graficzną. Może być zintegrowana (na tym samym układzie scalonym co procesor) lub dedykowana (zazwyczaj karta PCIe, która jest wydajniejsza, ale zużywa więcej energii).
Gdy będziesz już mieć adapter GPU, wywołaj funkcję adapter.requestDevice(), aby uzyskać obietnicę, która zostanie zrealizowana na urządzeniu GPU, którego będziesz używać do obliczeń GPU.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
Obie funkcje mają opcje, które umożliwiają określenie rodzaju adaptera (preferencje dotyczące mocy) i urządzenia (rozszerzenia, limity). Ze względu na prostotę w tym artykule użyjemy opcji domyślnych.
Bufor pamięci zapisu
Zobaczmy, jak użyć JavaScriptu do zapisywania danych w pamięci przez GPU. Ten proces nie jest prosty ze względu na model piaskownicy używany w nowoczesnych przeglądarkach internetowych.
Przykład poniżej pokazuje, jak zapisać 4 bajty w celu buforowania pamięci dostępnej przez GPU. Wywołuje on funkcję device.createBuffer(), która pobiera rozmiar bufora i jego użycie. Mimo że w przypadku tego konkretnego wywołania flaga użycia GPUBufferUsage.MAP_WRITE nie jest wymagana, wyraźnie określmy, że chcemy zapisać dane w tym buforze. W efekcie obiekt bufora procesora GPU jest mapowany podczas tworzenia dzięki ustawieniu parametru mappedAtCreation na wartość true. Następnie powiązany bufor danych binarnych w postaci binarnej można pobrać, wywołując metodę bufora GPU getMappedRange().
Jeśli znasz już funkcję ArrayBuffer, zapisywanie bajtów jest znajome. Użyj polecenia TypedArray i skopiuj do niego wartości.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE
});
const arrayBuffer = gpuBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
W tym momencie bufor GPU jest mapowany, co oznacza, że jest on własnością procesora i dostępny do odczytu/zapisu z JavaScript. Aby GPU mógł uzyskać do niego dostęp, musi być odmapowany. Można to zrobić, wywołując funkcję gpuBuffer.unmap().
Pojęcie mapowania/niemapowania jest potrzebne, aby zapobiec warunkom wyścigu, w których GPU i procesor uzyskują dostęp do pamięci w tym samym czasie.
Odczyt pamięci buforowej
Teraz zobaczmy, jak skopiować bufor GPU do innego bufora GPU i odczytać go.
Ponieważ zapisujemy dane w pierwszym buforze GPU i chcemy je skopiować do drugiego bufora GPU, potrzebna jest nowa flaga użycia GPUBufferUsage.COPY_SRC. Drugi bufor GPU jest tym razem tworzony w stanie niezamapowanym za pomocą funkcji device.createBuffer(). Jego flaga użycia to GPUBufferUsage.COPY_DST |
GPUBufferUsage.MAP_READ, ponieważ będzie on używany jako miejsce docelowe pierwszego bufora GPU i czytany w JavaScript po wykonaniu poleceń kopiowania przez GPU.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing.
const gpuWriteBuffer = device.createBuffer({
mappedAtCreation: true,
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});
const arrayBuffer = gpuWriteBuffer.getMappedRange();
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
Ponieważ GPU jest niezależnym koprocesorem, wszystkie polecenia GPU są wykonywane asynchronicznie. Dlatego w razie potrzeby jest tworzona i wysyłana w partiach lista poleceń GPU. W WebGPU koder poleceń GPU zwracany przez device.createCommandEncoder()to obiekt JavaScript, który tworzy partię „buforowanych” poleceń, które w danym momencie zostaną wysłane do GPU. Z drugiej strony metody w GPUBuffer są „niebuforowane”, co oznacza, że są wykonywane w czasie wywołania.
Gdy masz już koder poleceń GPU, wywołaj copyEncoder.copyBufferToBuffer()
jak pokazano poniżej, aby dodać to polecenie do kolejki poleceń do późniejszego wykonania.
Na koniec dokończ polecenia kodowania, wywołując copyEncoder.finish() i przesyłając je do kolejki poleceń urządzenia GPU. Kolejka odpowiada za obsługę przesyłania za pomocą polecenia device.queue.submit() z poleceniami GPU jako argumentami.
Spowoduje to wykonanie w kolejności wszystkich poleceń zapisanych w tablicy.
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(
gpuWriteBuffer /* source buffer */,
0 /* source offset */,
gpuReadBuffer /* destination buffer */,
0 /* destination offset */,
4 /* size */
);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.queue.submit([copyCommands]);
W tym momencie polecenia kolejki GPU zostały wysłane, ale niekoniecznie zostały wykonane.
Aby odczytać drugi bufor GPU, wywołaj gpuReadBuffer.mapAsync() za pomocą GPUMapMode.READ. Zwraca obietnicę, która zostanie spełniona, gdy bufor GPU zostanie zamapowany. Następnie pobierz zakres mapowany za pomocą parametru gpuReadBuffer.getMappedRange(), który zawiera te same wartości co pierwszy bufor GPU po wykonaniu wszystkich poleceń GPU w kolejce.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const copyArrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Uint8Array(copyArrayBuffer));
Możesz wypróbować ten przykład.
W skrócie musisz pamiętać o operacjach buforowania pamięci:
- Aby można było używać ich podczas przesyłania kolejki urządzenia, bufory GPU muszą być niezmapowane.
- Po zmapowaniu bufory GPU można odczytywać i zapisywać w JavaScripcie.
- Bufory procesora graficznego są mapowane, gdy wywołane są funkcje
mapAsync()icreateBuffer()z wartością true w polumappedAtCreation.
Programowanie oparte na cieniowaniu
Programy działające na procesorze graficznym, które wykonują tylko obliczenia (i nie rysują trójkątów), nazywane są shaderami obliczeniowymi. Są one wykonywane równolegle przez setki rdzeni GPU (które są mniejsze niż rdzenie procesora) i działają razem, aby przetwarzać dane. Ich dane wejściowe i wyjściowe są buforami w WebGPU.
Aby zilustrować zastosowanie cieniowania obliczeniowego w WebGPU, zajmiemy się mnożeniem macierzy, co jest często spotykanym algorytmem uczącym się opisanym poniżej.

Krótko mówiąc, zrobimy to w ten sposób:
- Utwórz 3 bufory GPU (2 dla macierzy do mnożenia i 1 dla macierzy wynikowej).
- Opisz dane wejściowe i wyjściowe dla cieniowania obliczeniowego
- Kompilowanie kodu cieniowania Compute
- Konfigurowanie potoku obliczeniowego
- Zbiorcze przesyłanie zakodowanych poleceń do GPU
- Odczytywanie zasobu bufora GPU macierzy wyników
Tworzenie buforów GPU
Dla uproszczenia macierze będą przedstawione w postaci listy liczb zmiennoprzecinkowych. Pierwszy element to liczba wierszy, drugi element to liczba kolumn, a reszta to rzeczywiste liczby macierzy.

Trzy bufory GPU to bufory pamięci, ponieważ musimy przechowywać i pobierać dane w shaderze obliczeniowym. Z tego powodu flagi wykorzystania bufora GPU zawierają flagę GPUBufferUsage.STORAGE dla wszystkich. Flaga użycia macierzy wyników ma też wartość GPUBufferUsage.COPY_SRC, ponieważ zostanie skopiowana do innego bufora do odczytu po wykonaniu wszystkich poleceń kolejki GPU.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) { return; }
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2 /* rows */, 4 /* columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);
const gpuBufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows */, 2 /* columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);
const gpuBufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();
// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
Bind group layout i bind group
Koncepcje układu grupy powiązań i grupy powiązań są specyficzne dla WebGPU. Układ grup powiązań definiuje interfejs wejścia/wyjścia oczekiwany przez program do cieniowania, a grupa powiązań reprezentuje rzeczywiste dane wejściowe/wyjściowe dla cieniowania.
W przykładzie poniżej układ grupy bind oczekuje 2 buforów pamięci tylko do odczytu w numerowanych elementach bindowania 0 i 1 oraz bufora pamięci w miejscu 2 dla shadera obliczeniowego.
Zdefiniowana w tym układzie grupa wiązania skojarzy bufory GPU z tymi wpisami: gpuBufferFirstMatrix z wiązaniem 0, gpuBufferSecondMatrix z wiązaniem 1 oraz resultMatrixBuffer z wiązaniem 2.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "read-only-storage"
}
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage"
}
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: gpuBufferFirstMatrix
}
},
{
binding: 1,
resource: {
buffer: gpuBufferSecondMatrix
}
},
{
binding: 2,
resource: {
buffer: resultMatrixBuffer
}
}
]
});
Kod shadera obliczeniowego
Kod programu do cieniowania obliczeń służących do mnożenia macierzy jest napisany w języku WGSL (WebGPU Shader Language), który można łatwo przetłumaczyć za pomocą wyrażenia SPIR-V. Bez wnikania w szczegóły znajdziesz pod 3 buforami pamięci masowej oznaczonymi przez var<storage>. Program użyje firstMatrix i secondMatrix jako danych wejściowych
i resultMatrix jako danych wyjściowych.
Pamiętaj, że każdy bufor pamięci ma ozdobę binding, która odpowiada temu samemu indeksowi zdefiniowanemu w deklarowanych powyżej grupach bind i ich układach.
const shaderModule = device.createShaderModule({
code: `
struct Matrix {
size : vec2f,
numbers: array<f32>,
}
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) global_id : vec3u) {
// Guard against out-of-bounds work group sizes
if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2(global_id.x, global_id.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`
});
Konfiguracja potoku
Potok obliczeniowy to obiekt, który faktycznie opisuje operację obliczeniową, którą zamierzamy wykonać. Utwórz je, dzwoniąc pod numer device.createComputePipeline().
Przyjmuje 2 argumenty: wcześniej utworzony układ grupy wiązania oraz etap przetwarzania definiujący punkt wejścia naszego shadera obliczeniowego (funkcja WGSL main) i sam moduł shadera obliczeniowego utworzony za pomocą funkcji device.createShaderModule().
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
compute: {
module: shaderModule,
entryPoint: "main"
}
});
Przesyłanie poleceń
Po utworzeniu instancji grupy powiązań z naszymi 3 buforami GPU i potokiem obliczeniowym z układem grupy powiązań przyszedł czas na ich użycie.
Uruchom koder z przesyłką obliczeniową programowalną za pomocą commandEncoder.beginComputePass(). Użyjemy go do zakodowania poleceń GPU, które wykonają mnożenie macierzy. Ustaw potok passEncoder.setPipeline(computePipeline) i jego grupę powiązań na poziomie 0 za pomocą parametru passEncoder.setBindGroup(0, bindGroup). Indeks 0 odpowiada dekoracji group(0) w kodzie WGSL.
Porozmawiajmy teraz o tym, jak ten shader obliczeniowy będzie działać na karcie graficznej. Naszym celem jest równoległe wykonywanie tego programu w przypadku każdej komórki macierzy wyników, krok po kroku. Na przykład w przypadku macierzy wyników o wymiarach 16 x 32, aby zakodować polecenie wykonania na @workgroup_size(8, 8), użyjemy funkcji passEncoder.dispatchWorkgroups(2, 4) lub passEncoder.dispatchWorkgroups(16 / 8, 32 / 8).
Pierwszy argument „x” to pierwszy wymiar, drugi „y” to drugi, a ostatni „z” to trzeci wymiar, który domyślnie ma wartość 1, ponieważ nie jest on tutaj potrzebny.
W świecie obliczeń na procesorach graficznych kodowanie polecenia do wykonania funkcji jądra na zbiorze danych nazywa się wysyłaniem.

Rozmiar siatki grup roboczych dla naszego shadera obliczeniowego to (8, 8) w kodzie WGSL. W związku z tym wartości „x” i „y”, czyli odpowiednio liczba wierszy pierwszej macierzy i liczba kolumn drugiej macierzy, zostaną podzielone przez 8. Teraz możemy wysłać do Ciebie zapytanie o pomoc dotyczące passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8). Liczba siatek grup roboczych do uruchomienia to argumenty dispatchWorkgroups().
Jak widać na rysunku powyżej, każdy cieniowanie ma dostęp do unikalnego obiektu builtin(global_invocation_id), który jest używany do określania, którą komórkę macierzy wyników należy obliczyć.
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const workgroupCountX = Math.ceil(firstMatrix[0] / 8);
const workgroupCountY = Math.ceil(secondMatrix[1] / 8);
passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY);
passEncoder.end();
Aby zakończyć koder Compute Pass, wywołaj passEncoder.end(). Następnie utwórz bufor GPU, który będzie używany jako miejsce docelowe do skopiowania bufora macierzy wyników za pomocą polecenia copyBufferToBuffer. Na koniec zakończ kodowanie poleceń za pomocą copyEncoder.finish() i prześlij je do kolejki urządzenia GPU, wywołując device.queue.submit() z poleceniami GPU.
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(
resultMatrixBuffer /* source buffer */,
0 /* source offset */,
gpuReadBuffer /* destination buffer */,
0 /* destination offset */,
resultMatrixBufferSize /* size */
);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
Czytanie macierzy wyników
Odczytywanie macierzy wyników jest tak proste, jak wywołanie metody gpuReadBuffer.mapAsync() za pomocą GPUMapMode.READ i oczekiwanie na rozwiązanie obietnicy zwracającej, która wskazuje, że bufor GPU jest teraz zmapowany. W tym momencie można pobrać zmapowany zakres za pomocą funkcji gpuReadBuffer.getMappedRange().

W naszym kodzie wynik zapisany w konsoli JavaScriptu DevTools to „2, 2, 50, 60, 114, 140”.
// Read buffer.
await gpuReadBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = gpuReadBuffer.getMappedRange();
console.log(new Float32Array(arrayBuffer));
Gratulacje! Gotowe! Możesz wykorzystać sampel.
Ostatni trik
Jednym ze sposobów ułatwienia odczytania kodu jest użycie przydatnej metody getBindGroupLayout w pipeline’ie obliczeniowym, aby wywnioskować układ grupy bindowania z modułu shadera. Dzięki temu nie musisz tworzyć niestandardowego układu grupy wiązania ani określać układu potoku w potoku obliczeniowym, jak widać poniżej.
getBindGroupLayout w przypadku poprzedniego przykładu jest dostępna.
const computePipeline = device.createComputePipeline({
- layout: device.createPipelineLayout({
- bindGroupLayouts: [bindGroupLayout]
- }),
compute: {
-// Bind group layout and bind group
- const bindGroupLayout = device.createBindGroupLayout({
- entries: [
- {
- binding: 0,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 1,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "read-only-storage"
- }
- },
- {
- binding: 2,
- visibility: GPUShaderStage.COMPUTE,
- buffer: {
- type: "storage"
- }
- }
- ]
- });
+// Bind group
const bindGroup = device.createBindGroup({
- layout: bindGroupLayout,
+ layout: computePipeline.getBindGroupLayout(0 /* index */),
entries: [
Wyniki
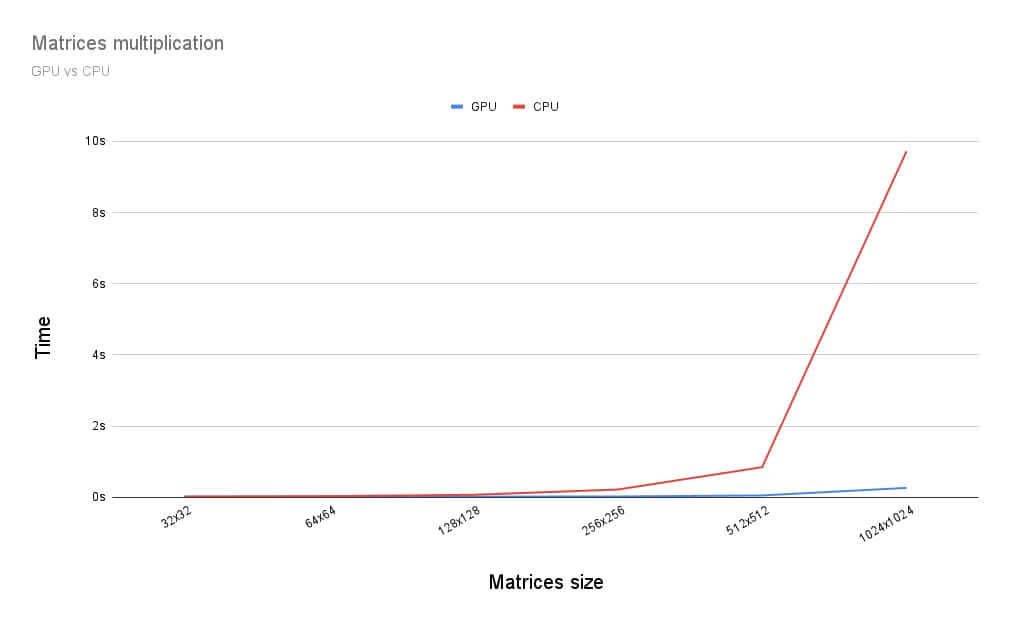
Jakie są różnice między mnożeniem macierzy na procesorze graficznym a na procesorze CPU? Aby to sprawdzić, napisałem program, o którym właśnie mówiłem, na procesor CPU. Jak widać na wykresie poniżej, wykorzystanie pełnej mocy GPU wydaje się oczywistym wyborem, gdy rozmiar macierzy jest większy niż 256 x 256.
Ten artykuł to tylko początek mojej przygody z poznawaniem WebGPU. Wkrótce opublikujemy więcej artykułów, w których znajdziesz więcej informacji o obliczeniach na procesorze graficznym oraz o tym, jak działa renderowanie (płótno, tekstura, próbnik) w WebGPU.