
While generative AI (gen AI) is rapidly growing in adoption, there’s a still largely-untapped potential to build products by applying gen AI to data that has higher requirements to ensure it remains private and confidential.
For example, this could mean applying gen AI to:
In certain applications such as these, there may be heightened requirements with respect to privacy/confidentiality, transparency, and external verifiability of data processing.
Google has developed a number of technologies that you can use to start experimenting with and exploring the potential of gen AI to process data that needs to stay more private. In this post, we’ll explain how you can use the recently released GenC open-source project to combine Confidential Computing, the Gemma open-source models, and mobile platforms together to begin experimenting with building your own gen AI-powered apps that can handle data with heightened requirements with respect to privacy/confidentiality, transparency, and external verifiability.
The scenario we’ll focus on in this post, illustrated below, involves a mobile app that has access to data on device, and wants to perform gen AI processing on this data using an LLM.
For example, imagine a personal assistant app that’s being asked to summarize or answer a question about notes, a document, or a recording stored on the device. The content might contain private information such as messages with another person, so we want to ensure it stays private.
In our example, we picked the Gemma family of open-source models. Note that whereas we focus here on a mobile app, the same principles apply to businesses hosting their own data on-premises.
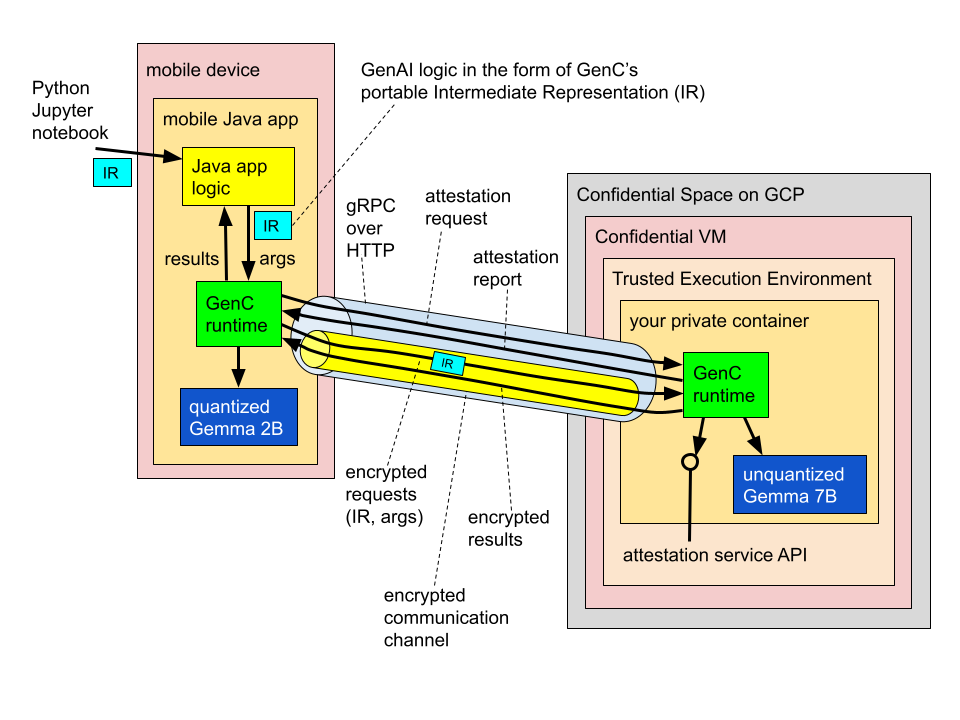
This example shows a “hybrid” setup that involves two LLMs, one running locally on the user’s device, and another hosted in a Google Cloud's Confidential Space Trusted Execution Environments (TEE) powered by Confidential Computing. This hybrid architecture enables the mobile app to take advantage of both on-device as well as cloud resources to benefit from the unique advantages of both:
In our example, the two models work together, connected into a model cascade in which the smaller, cheaper, and faster Gemma 2B serves as the first tier, and handles simpler queries, whereas the larger Gemma 7B serves as a backup for queries that the former can’t handle on its own. For example, in the code snippet further below, we setup Gemma 2B to act as an on-device router that first analyzes each input query to decide which of the two models is most appropriate, and then based on the outcome of that, either proceeds to handle the query locally on-device, or relays it to the Gemma 7B that resides in a cloud-based TEE.
You can think of the TEE in cloud in this architecture as effectively a logical extension of the user’s mobile device, powered by transparency, cryptographic guarantees, and trusted hardware:
At a glance this setup might seem complex, and indeed it would be such if one had to set it all up completely from scratch. We’ve developed GenC precisely to make the process easier.
Here’s the example of code you would actually have to write to set up a scenario like the above in GenC. We default here to Python as a popular choice, albeit we offer Java and C++ authoring APIs as well. In this example, we use the presence of a more sensitive subject as a signal that the query should be handled by a more powerful model (that is capable of crafting a more careful response). Keep in mind this example is simplified for illustration purposes. In practice, routing logic could be more elaborate and application-specific, and careful prompt engineering is essential to achieving good performance, especially with smaller models.
@genc.authoring.traced_computation
def cascade(x):
gemma_2b_on_device = genc.interop.llamacpp.model_inference(
'/device/llamacpp', '/gemma-2b-it.gguf', num_threads=16, max_tokens=64)
gemma_7b_in_a_tee = genc.authoring.confidential_computation[
genc.interop.llamacpp.model_inference(
'/device/llamacpp', '/gemma-7b-it.gguf', num_threads=64, max_tokens=64),
{'server_address': /* server address */, 'image_digest': /* image digest */ }]
router = genc.authoring.serial_chain[
genc.authoring.prompt_template[
"""Read the following input carefully: "{x}".
Does it touch on political topics?"""],
gemma_2b_on_device,
genc.authoring.regex_partial_match['does touch|touches']]
return genc.authoring.conditional[
gemma_2b_on_device(x), gemma_7b_in_a_tee(x)](router(x))
You can see detailed step-by-step breakdown of how to build and run such examples in our tutorials on GitHub. As you can see, the level of abstraction matches what you can find in popular SDKs such as LangChain. Model inference calls to Gemma 2B and 7B are interspersed here with prompt templates and output parsers, and combined into chains. (By the way, we do offer limited LangChain interop that we hope to expand.)
Note that whereas the Gemma 2B model inference call is used directly within a chain that runs on-device, the Gemma 7B call is explicitly embedded within a confidential_computation statement.
The point is that there are no surprises here - the programmer is always in full control of the decision of what processing to perform on-device, and what to delegate from device to a TEE in the cloud. This decision is explicitly reflected in the code structure. (please note whereas in this example, we only delegate the Gemma 7B calls to a single trusted backend, the mechanism we provide is generic, and one can use it to delegate larger chunks of processing, e.g., an entire agent loop, to an arbitrary number of backends.)
Whereas the code shown above is expressed using a familiar Python syntax, under the hood it’s being transformed into what we call a portable platform- and language-independent form that we refer to as the Intermediate Representation (or “IR” for short).
This approach offers a number of advantages; to name a few:
In realistic deployments, performance is often a critical factor. Our published examples at the moment are limited to CPU-only, and GenC currently only offers llama.cpp as the driver for models in a TEE. However, the Confidential Computing team is extending support to Intel TDX with Intel AMX built-in accelerator along with the upcoming preview of Nvidia H100 GPUs running in confidential mode, and we are actively working to expand the range of the available software and hardware options to unlock the best performance and support for a broader range of models - stay tuned for the future updates!
We hope that you’re intrigued, and that this post will encourage you to experiment with building your own gen AI applications using some of the technologies we’ve introduced. And on that note, please do keep in mind that GenC is an experimental framework, developed for experimental and research purposes - we’ve built it to demonstrate what’s possible, and to inspire you to explore this exciting space together with us. If you’d like to contribute - please reach out to the authors, or simply engage with us on GitHub. We love to collaborate!

Save the date for Firebase Demo Day 2024!

Supercharging AI Coding Assistants with Gemini Models' Long Context

People of AI: Season 3 Takeaways and Season 4 Previews

Gemini is now accessible from the OpenAI Library
Towards Global Understanding – Advancing Multilingual AI with Gemma 2 and a $150K Challenge

Introducing Keras Hub: Your one-stop shop for pretrained models