

Gemma es una familia de modelos abiertos ligeros y de última generación, creados sobre la base de la misma investigación y tecnología que se utilizan para crear los modelos de Gemini.
Hay diferentes variaciones de Gemma diseñadas para diferentes casos de uso y modalidades, como los siguientes:
Debido a que todos estos modelos comparten un ADN similar, la familia Gemma presenta una forma única de conocer las arquitecturas y las opciones de diseño que están disponibles en los sistemas de LLM modernos. Esperamos que todo esto contribuya a generar un rico ecosistema de modelos abiertos y promueva una mayor comprensión de cómo funcionan los sistemas de LLM.
En esta serie, se cubrirán los siguientes modelos:
En esta serie, nos ocuparemos de lo siguiente:
Para proporcionar información sobre el modelo, usamos el módulo de impresión Hugging Face Transformers, como el código simple que se muestra a continuación.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b")
print(model)
También puedes explorar el interior del modelo con torchinfo o summary() en la API de clases del modelo de Keras.
Esta guía no es una introducción a la IA. Se asume que quien la lea tiene conocimientos prácticos sobre redes neuronales, transformadores y términos asociados, como tokens. Si necesitas repasar estos conceptos, aquí tienes algunos recursos para empezar:
Una herramienta práctica de aprendizaje de redes neuronales que funciona en el navegador
Una introducción a los transformadores
Gemma es un LLM de peso abierto. Incluye variantes ajustadas según instrucciones y preentrenadas sin procesar, con parámetros de varios tamaños. Se basa en la arquitectura de LLM introducida por Google Research en el documento Attention Is All You Need. Su función principal es generar tokenword de texto por tokenword, sobre la base de una solicitud proporcionada por un usuario. En tareas como la traducción, Gemma toma una oración de un idioma como entrada y emite su equivalente en otro idioma.
Como pronto verás, Gemma es un gran modelo en sí mismo, pero también se puede ampliar y personalizar para satisfacer las diferentes necesidades de los usuarios.
Primero, veamos el decodificador del transformador en el que se basan los modelos de Gemma.
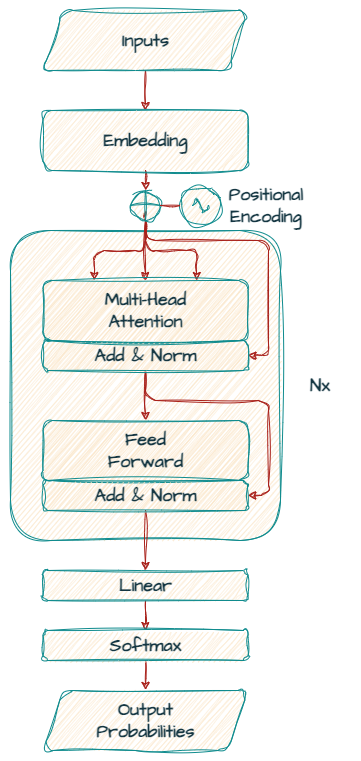
A diferencia de la arquitectura original del modelo de transformador codificador-decodificador presentada en “Attention Is All You Need”, Gemma es únicamente un modelo de “solo decodificador”.
Los parámetros principales de la arquitectura se resumen en la siguiente tabla.

Los modelos se entrenan en una longitud de contexto de 8192 tokens. Esto significa que pueden procesar hasta aproximadamente 6144 palabras (usando la regla general de 100 tokens ~= 75 palabras) por vez.
Vale la pena señalar que el límite de entrada práctico puede variar según la tarea y el uso. Esto se debe a que la generación de texto consume tokens dentro de la ventana de contexto, lo que reduce en efecto el espacio para nuevas entradas. Aunque el límite de entrada técnica se mantiene constante, la salida generada se convierte en parte de la entrada subsiguiente, lo que influye en las generaciones posteriores.
d_model representa el tamaño de las incrustaciones (representaciones vectoriales de palabras o subpalabras, también conocidas como tokens) utilizadas como entrada en el decodificador. También determina el tamaño de la representación interna dentro de las capas del decodificador.
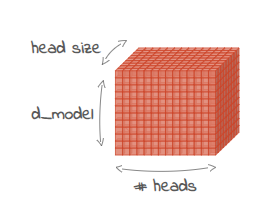
Un valor de d_model más grande indica que el modelo tiene más “espacio” para representar los matices de diferentes palabras y sus relaciones. Esto puede generar un mejor rendimiento, especialmente en tareas lingüísticas complejas. Sin embargo, el aumento de d_model también hace que el modelo sea más grande y computacionalmente más costoso de entrenar y usar.
Los transformadores constan de múltiples capas apiladas. Los modelos más profundos tienen más capas y, por lo tanto, más parámetros, y pueden aprender patrones más intrincados. Sin embargo, esta mayor cantidad de parámetros indica que también son más propensos al sobreajuste y requieren más recursos computacionales.
Esta capacidad de representación aumentada podría hacer que el modelo adquiera fluctuaciones o patrones de datos de entrenamiento específicos que no cuentan con la capacidad de generalizar según ejemplos novedosos.
Además, los modelos más profundos suelen necesitar más datos de entrenamiento para evitar el sobreajuste. En los casos en que los datos disponibles son limitados, el modelo puede carecer de ejemplos suficientes para aprender una representación generalizable, lo que lleva a la memorización de los datos de entrenamiento.
Cada capa del transformador incluye una red de prealimentación después del mecanismo de atención. Esta red tiene su propia dimensionalidad, que suele tener un mayor tamaño que el de d_model a fin de aumentar el poder expresivo del modelo.
Se implementa como un perceptrón multicapa (MLP), una especie de red neuronal, para transformar aún más las incrustaciones y extraer patrones más intrincados.
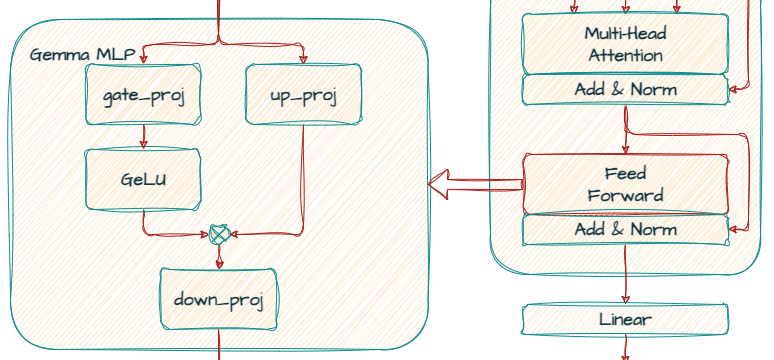
En Gemma, la no linealidad estándar de ReLU se reemplaza por la función de activación de GeGLU, una variación de GLU (Gate Linear Unit). GeGLU divide la activación en dos partes: una parte sigmoidal y una proyección lineal. La salida de la parte sigmoidal se multiplica por elementos con la proyección lineal, lo que da como resultado una función de activación no lineal.
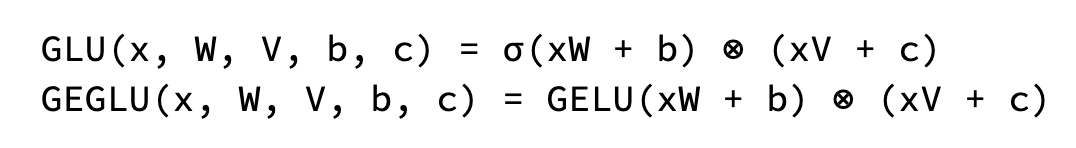
Cada capa del transformador contiene múltiples mecanismos de atención que trabajan en paralelo. Estos “hilos de ejecución” permiten que el modelo se centre en diferentes aspectos de la secuencia de entrada simultáneamente. Aumentar el número de hilos de ejecución puede mejorar la capacidad del modelo para capturar diversas relaciones en los datos.
El modelo 7B utiliza la atención de hilos de ejecución múltiples (MHA), mientras que el modelo 2B utiliza la atención de consultas múltiples (MQA). La MQA comparte las mismas proyecciones de clave y valor, lo que significa que cada hilo de ejecución se centra en la misma representación subyacente, pero con diferentes proyecciones de consulta.
La MHA original ofrece un aprendizaje de representación más rico, pero tiene costos computacionales más altos. La MQA proporciona una alternativa eficiente que demostró ser eficaz.
Se refiere a la dimensionalidad de cada hilo de ejecución de atención dentro del mecanismo de atención de múltiples hilos de ejecución. Se calcula dividiendo la dimensión de incrustación por el número de hilos de ejecución. Por ejemplo, si la dimensión de incrustación es 2048 y hay 8 hilos de ejecución, cada hilo de ejecución tendría un tamaño de 256.
Define el número de tokens únicos (palabras, subpalabras o caracteres) que el modelo entiende y puede procesar. El tokenizador de Gemma se basa en SentencePiece. El tamaño de vocabulario está predeterminado antes del entrenamiento. Luego, SentencePiece aprende la segmentación óptima de subpalabras en función del tamaño de vocabulario elegido y los datos de entrenamiento. El amplio vocabulario de 256,000 palabras de Gemma le permite procesar diversas entradas de texto y mejorar potencialmente el rendimiento en diversas tareas, como procesar entradas de texto multilingües.
GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(256000, 3072, padding_idx=0)
(layers): ModuleList(
(0-27): 28 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=3072, out_features=4096, bias=False)
(k_proj): Linear(in_features=3072, out_features=4096, bias=False)
(v_proj): Linear(in_features=3072, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=3072, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=3072, out_features=24576, bias=False)
(up_proj): Linear(in_features=3072, out_features=24576, bias=False)
(down_proj): Linear(in_features=24576, out_features=3072, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=3072, out_features=256000, bias=False)
)
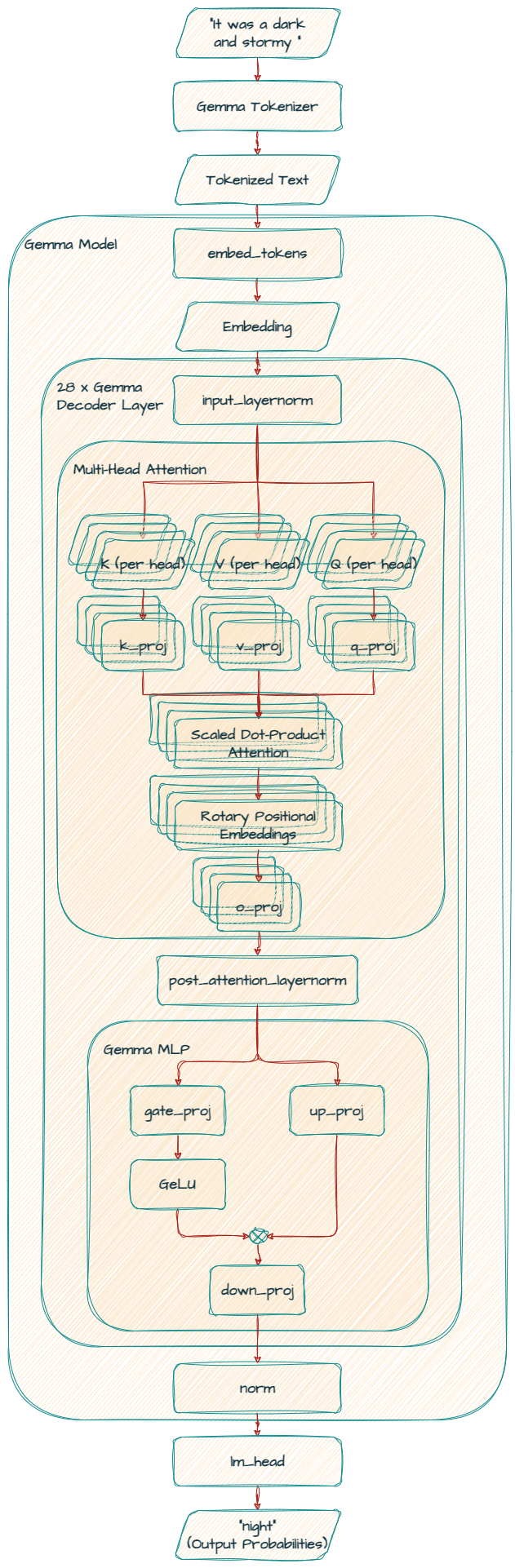
Esta capa convierte los tokens de entrada (palabras o subpalabras) en representaciones numéricas densas (incrustaciones) que el modelo puede procesar. Tiene un tamaño de vocabulario de 256,000 y crea incrustaciones de dimensión 3072.
Se trata de la parte más importante del modelo, que consta de 28 bloques GemmaDecoderLayer apilados. Cada una de estas capas refina las incrustaciones de tokens para capturar relaciones complejas entre las palabras y su contexto.
En el mecanismo de autoatención, el modelo asigna diferentes pesos a las palabras de la entrada cuando crea la palabra siguiente. Gracias a que aprovecha un mecanismo de atención de producto escalar, el modelo utiliza proyecciones lineales (q_proj, k_proj, v_proj y o_proj) para generar representaciones de consulta, clave, valor y salida.
Todos los valores de out_features son los mismos 4096 para q_proj, k_proj y v_proj, ya que este modelo utiliza la atención de hilos de ejecución múltiples (MHA). Tienen 16 hilos de ejecución con un tamaño de 256 en paralelo, con un total de 4096 (256 x 16).
Además, el modelo aprovecha la información posicional de manera más efectiva, ya que utiliza rotary_emb (GemmaRotaryEmbedding) para la codificación posicional (también conocida como RoPE).
Finalmente, la capa o_proj proyecta la salida de atención de nuevo a la dimensión original (3072).
Ten en cuenta que el modelo Gemma 2B utiliza la atención de consultas múltiples (MQA).
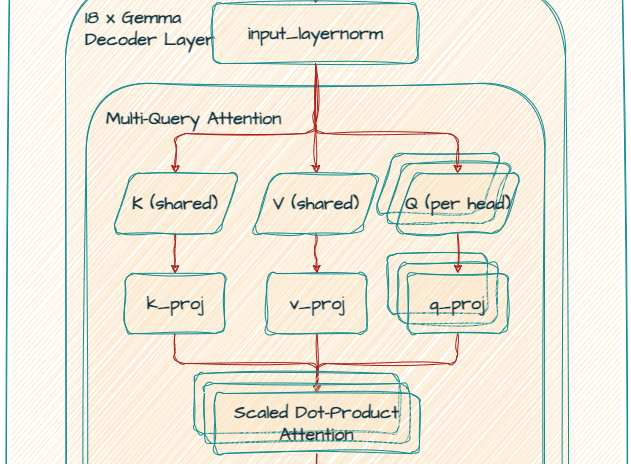
k_proj y v_proj comparten el mismo hilo de ejecución con un tamaño de 256, por lo que out_features es de 256. Por el contrario, q_proj y o_proj tienen 8 hilos de ejecución (256 x 8 = 2048) en paralelo.
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
Utiliza gate_proj y up_proj para un mecanismo de compuerta, seguido de down_proj para reducir la dimensión de nuevo a 3072.
Estas capas de normalización estabilizan el entrenamiento y mejoran la capacidad del modelo para aprender de manera eficaz.
Esta capa final asigna las incrustaciones refinadas (3072) a una distribución de probabilidad para el siguiente token en el espacio de vocabulario (256000).
Los modelos CodeGemma son modelos de Gemma ajustados que están optimizados para completar el código y codificar la asistencia en chats. Los modelos CodeGemma están entrenados con más de 500,000 millones de tokens de código, principalmente. Además, CodeGemma agrega la capacidad de rellenar el medio, lo que permite las terminaciones que se producen entre dos partes del texto existente.
CodeGemma destaca la capacidad de realizar ajustes de los puntos de control de Gemma. A través de un entrenamiento adicional, los modelos se especializan en una tarea determinada, y aprenden una finalización más compleja que la finalización de sufijos puros.
Puedes usar 4 tokens definidos por el usuario: 3 para FIM y un token "<|file_separator|>" para compatibilidad con contextos de múltiples archivos.
BEFORE_CURSOR = "<|fim_prefix|>"
AFTER_CURSOR = "<|fim_suffix|>"
AT_CURSOR = "<|fim_middle|>"
FILE_SEPARATOR = "<|file_separator|>"
Imagina que estás tratando de completar el código, como en la pantalla que se muestra abajo.
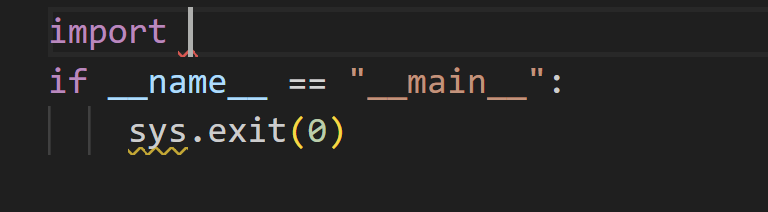
Y la indicación de entrada debe ser como la siguiente
<|fim_prefix|>import <|fim_suffix|>if __name__ == "__main__":\n sys.exit(0)<|fim_middle|>
El modelo proporcionará "sys" como la finalización de código sugerida.
Puedes explorar más sobre CodeGemma en CodeGemma / Quickstart.
En este artículo, se analizó la arquitectura de Gemma.
En nuestra próxima serie de entradas de blog, explorarás el último modelo, Gemma 2. Este modelo, que incluye mejoras sustanciales en las medidas de seguridad, supera a su predecesor en términos de rendimiento y eficiencia durante la inferencia.
¡No te pierdas las próximas entradas y gracias por leer!
Gemma
CodeGemma

Presentamos KerasHub: la tienda de modelos preentrenados

Hacia una comprensión global: avances de la IA multilingüe con Gemma 2 y un desafío por USD 150,000

Todo sobre Gemma: arquitectura PaliGemma

Supercharging AI Coding Assistants with Gemini Models' Long Context

Gemini is now accessible from the OpenAI Library