

Kami sangat senang dapat membantu developer menghadirkan model AI generatif baru di perangkat dengan lancar ke perangkat edge. Untuk memenuhi kebutuhan tersebut, kami mengumumkan AI Edge Torch Generative API, yang memungkinkan developer membuat LLM berkinerja tinggi di PyTorch untuk penerapan menggunakan runtime TensorFlow Lite (TFLite). Ini adalah bagian kedua dari seri postingan blog yang membahas rilis developer Google AI Edge. Postingan pertama dalam seri ini memperkenalkan Google AI Edge Torch, yang memungkinkan inferensi model PyTorch berperforma tinggi di perangkat seluler menggunakan runtime TFLite.
AI Edge Torch Generative API memungkinkan developer menghadirkan kemampuan baru yang kuat di perangkat, seperti perangkuman, pembuatan konten, dan lainnya. Kami telah memfasilitasi developer untuk menghadirkan beberapa LLM terpopuler ke perangkat menggunakan MediaPipe LLM Inference API. Kami sangat senang bisa membantu developer menghadirkan setiap model yang didukung ke perangkat dengan performa luar biasa. Versi awal AI Edge Torch Generative API menawarkan hal-hal berikut:
Dalam postingan blog ini, kita akan mendalami performa, portabilitas, pengalaman developer saat penulisan, pipeline inferensi menyeluruh, dan debug toolchain. Dokumentasi dan contoh selengkapnya tersedia di sini.
Sebagai bagian dari upaya kami untuk membuat beberapa LLM terpopuler bekerja dengan lancar melalui MediaPipe LLM Inference API, tim kami menulis beberapa transformer yang sepenuhnya ditulis tangan dengan performa perangkat tercanggih (blog MediaPipe LLM Inference API). Beberapa tema muncul dari pekerjaan ini: bagaimana cara merepresentasikan perhatian secara efektif, penggunaan kuantisasi, dan pentingnya representasi Cache KV yang baik. Generative API membuat semuanya ini mudah diekspresikan (seperti yang akan kita lihat di bagian berikutnya), sembari tetap mencapai performa >90% dari versi tulisan tangan kami dengan kecepatan developer yang jauh lebih tinggi.
Tabel berikut ini menunjukkan tolok ukur utama pada 3 contoh model:
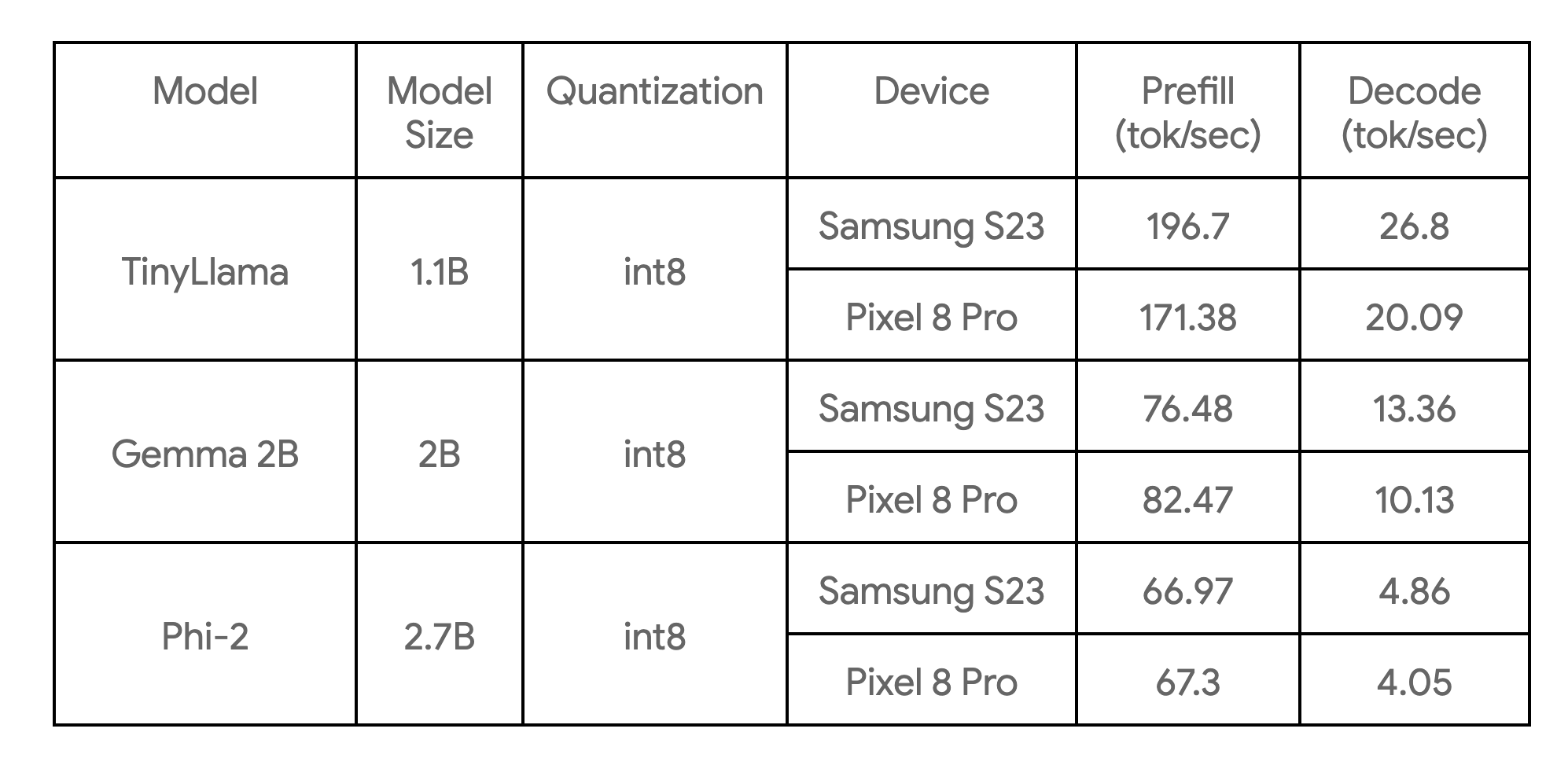
Ini merupakan tolok ukur pada inti besar, dengan 4 thread CPU, dan merupakan implementasi CPU tercepat dari model ini yang saat ini kami ketahui pada perangkat yang terdaftar.
Library penulisan inti menyediakan elemen penyusun dasar untuk model transformer umum (enkoder-saja, dekoder-saja, atau model enkoder-dekoder, dll). Ini memungkinkan Anda menulis model dari awal, atau menulis ulang model yang sudah ada untuk meningkatkan performa. Kami merekomendasikan sebagian besar pengguna untuk menulis ulang, karena tidak memerlukan langkah pelatihan/penyesuaian. Manfaat utama dari penulisan Generative API meliputi:
Sebagai contoh, di sini kami menampilkan cara menulis ulang fungsi inti TinyLLama(1.1B) dengan sekitar 50 baris Python menggunakan Generative API yang baru.
Langkah 1: Tentukan struktur model
import torch
import torch.nn as nn
from ai_edge_torch.generative.layers.attention import TransformerBlock
import ai_edge_torch.generative.layers.attention_utils as attn_utils
import ai_edge_torch.generative.layers.builder as builder
import ai_edge_torch.generative.layers.model_config as cfg
class TinyLLamma(nn.Module):
def __init__(self, config: cfg.ModelConfig):
super().__init__()
self.config = config
# Construct model layers.
self.lm_head = nn.Linear(
config.embedding_dim, config.vocab_size, bias=config.lm_head_use_bias
)
self.tok_embedding = nn.Embedding(
config.vocab_size, config.embedding_dim, padding_idx=0
)
self.transformer_blocks = nn.ModuleList(
TransformerBlock(config) for _ in range(config.num_layers)
)
self.final_norm = builder.build_norm(
config.embedding_dim,
config.final_norm_config,
)
self.rope_cache = attn_utils.build_rope_cache(
size=config.kv_cache_max,
dim=int(config.attn_config.rotary_percentage * config.head_dim),
base=10_000,
condense_ratio=1,
dtype=torch.float32,
device=torch.device("cpu"),
)
self.mask_cache = attn_utils.build_causal_mask_cache(
size=config.kv_cache_max, dtype=torch.float32, device=torch.device("cpu")
)
self.config = config
Langkah 2: Tentukan fungsi teruskan model
@torch.inference_mode
def forward(self, idx: torch.Tensor, input_pos: torch.Tensor) -> torch.Tensor:
B, T = idx.size()
cos, sin = self.rope_cache
cos = cos.index_select(0, input_pos)
sin = sin.index_select(0, input_pos)
mask = self.mask_cache.index_select(2, input_pos)
mask = mask[:, :, :, : self.config.kv_cache_max]
# forward the model itself
x = self.tok_embedding(idx) # token embeddings of shape (b, t, n_embd)
for i, block in enumerate(self.transformer_blocks):
x = block(x, (cos, sin), mask, input_pos)
x = self.final_norm(x)
res = self.lm_head(x) # (b, t, vocab_size)
return res
Langkah 3: Memetakan bobot model lama
Library ini memungkinkan Anda untuk memetakan bobot secara mudah dengan ModelLoader API, misalnya:
import ai_edge_torch.generative.utilities.loader as loading_utils
# This map will associate old tensor names with the new model.
TENSOR_NAMES = loading_utils.ModelLoader.TensorNames(
ff_up_proj="model.layers.{}.mlp.up_proj",
ff_down_proj="model.layers.{}.mlp.down_proj",
ff_gate_proj="model.layers.{}.mlp.gate_proj",
attn_query_proj="model.layers.{}.self_attn.q_proj",
attn_key_proj="model.layers.{}.self_attn.k_proj",
attn_value_proj="model.layers.{}.self_attn.v_proj",
attn_output_proj="model.layers.{}.self_attn.o_proj",
pre_attn_norm="model.layers.{}.input_layernorm",
pre_ff_norm="model.layers.{}.post_attention_layernorm",
embedding="model.embed_tokens",
final_norm="model.norm",
lm_head="lm_head",
)
Setelah langkah-langkah tersebut selesai, Anda bisa menjalankan beberapa input contoh untuk memverifikasi kebenaran numerik (lihat link) dari model yang telah ditulis ulang. Jika pemeriksaan numerik lulus, Anda dapat melanjutkan ke langkah konversi & kuantisasi.
Dengan API konversi yang disediakan ai_edge_torch, Anda bisa memanfaatkan API yang sama untuk mengonversi model transformer (yang telah ditulis ulang) menjadi model TensorFlow Lite yang sangat dioptimalkan. Proses konversi mencakup langkah-langkah penting berikut ini:
1) Ekspor ke StableHLO. Model PyTorch dilacak dan dikompilasi ke FX Graph dengan Aten ops oleh compiler torch dynamo, kemudian diturunkan ke grafik StableHLO dengan ai_edge_torch.
2) ai_edge_torch menjalankan proses compiler lanjutan pada StableHLO, termasuk penggabungan operasi/pelipatan, dll, dan menghasilkan flatbuffer TFLite yang berperforma tinggi (dengan operasi penggabungan untuk SDPA, KVCache).
Library Generative API inti juga menyediakan rangkaian API kuantisasi yang mencakup urutan langkah kuantisasi LLM umum. Urutan langkah tersebut meneruskan parameter tambahan ke API konverter ai_edge_torch, yang secara otomatis mencakup kuantisasi. Dalam rilis mendatang, kami berharap bisa memperluas rangkaian mode kuantisasi yang tersedia.
Kami mengidentifikasi bahwa dalam skenario inferensi yang sebenarnya, model LLM perlu memiliki fungsi inferensi (prefill, dekode) yang terpisah (disagregasi) dengan jelas untuk mencapai performa penyajian terbaik. Hal ini berdasarkan pengamatan bahwa prefill/dekode dapat mengambil bentuk Tensor yang berbeda, prefill terikat pada komputasi sedangkan dekode terikat pada memori. Untuk LLM yang besar, sangatlah penting untuk menghindari duplikasi bobot model antara prefill/dekode. Kami mencapai hal ini dengan menggunakan fitur multi-signature yang ada di TFLite dan ai_edge_torch yang memungkinkan Anda dengan mudah menentukan beberapa titik masuk untuk model seperti yang ditunjukkan di bawah ini.
def convert_tiny_llama_to_tflite(
prefill_seq_len: int = 512,
kv_cache_max_len: int = 1024,
quantize: bool = True,
):
pytorch_model = tiny_llama.build_model(kv_cache_max_len=kv_cache_max_len)
# Tensors used to trace the model graph during conversion.
prefill_tokens = torch.full((1, prefill_seq_len), 0, dtype=torch.long)
prefill_input_pos = torch.arange(0, prefill_seq_len)
decode_token = torch.tensor([[0]], dtype=torch.long)
decode_input_pos = torch.tensor([0], dtype=torch.int64)
# Set up Quantization for model.
quant_config = quant_recipes.full_linear_int8_dynamic_recipe() if quantize else None
edge_model = (
ai_edge_torch.signature(
'prefill', pytorch_model, (prefill_tokens, prefill_input_pos)
)
.signature('decode', pytorch_model, (decode_token, decode_input_pos))
.convert(quant_config=quant_config)
)
edge_model.export(f'/tmp/tiny_llama_seq{prefill_seq_len}_kv{kv_cache_max_len}.tflite')
Selama tahap investigasi performa, kami menemukan beberapa aspek penting untuk meningkatkan performa LLM:
1) SDPA dan KVCache berperforma tinggi: kami menemukan bahwa tanpa pengoptimalan / penggabungan compiler yang cukup, model TFLite yang dikonversi tidak akan memiliki performa yang baik, karena adanya operasi granular pada fungsi ini. Untuk mengatasi hal ini, kami memperkenalkan batas fungsi tingkat tinggi dan operasi komposit StableHLO
2) Memanfaatkan delegasi XNNPack TFLite untuk semakin mempercepat SDPA: sangatlah penting memastikan komputasi vektor MatMul/Matrix yang berat dapat dioptimalkan dengan baik. Library XNNPack memiliki performa yang sangat baik untuk primitif ini di berbagai macam CPU seluler.
3) Menghindari komputasi yang tidak perlu: model bentuk statis bisa menyebabkan lebih banyak komputasi daripada yang diperlukan secara minimal jika model memiliki ukuran pesan input tetap yang panjang pada tahap prefill atau panjang urutan tetap yang besar pada tahap dekode.
4) Konsumsi memori runtime. Kami memperkenalkan mekanisme caching/pre-packing bobot dalam delegasi XNNPack TFLite untuk secara signifikan menurunkan penggunaan memori puncak.
Inferensi LLM biasanya melibatkan banyak langkah pra/pasca-pemrosesan dan orkestrasi canggih, mis. Tokenisasi, pengambilan sampel, dan logika decoding autoregresif. Untuk itu, kami menyediakan solusi berbasis MediaPipe dan contoh inferensi C++ murni.
MediaPipe LLM Inference API adalah API tingkat tinggi yang mendukung Inferensi LLM menggunakan antarmuka prompt-in/prompt-out. API ini menangani semua kompleksitas implementasi pipeline LLM di balik prosesnya, dan membuat penerapan menjadi lebih mudah dan lancar. Untuk menerapkan menggunakan MP LLM Inference API, pastikan Anda mengonversi model menggunakan tanda tangan prefill dan dekode yang diperlukan, dan membuat paket seperti yang ditunjukkan pada kode di bawah ini:
def bundle_tinyllama_q8():
output_file = "PATH/tinyllama_q8_seq1024_kv1280.task"
tflite_model = "PATH/tinyllama_prefill_decode_hlfb_quant.tflite"
tokenizer_model = "PATH/tokenizer.model"
config = llm_bundler.BundleConfig(
tflite_model=tflite_model,
tokenizer_model=tokenizer_model,
start_token="<s>",
stop_tokens=["</s>"],
output_filename=output_file,
enable_bytes_to_unicode_mapping=False,
)
llm_bundler.create_bundle(config)
Kami juga menyediakan contoh C++ yang mudah digunakan (tanpa dependensi MediaPipe) untuk menunjukkan cara menjalankan contoh pembuatan teks secara menyeluruh. Developer bisa menggunakan contoh ini sebagai titik awal untuk mengintegrasikan model yang diekspor dengan persyaratan dan pipeline produksi mereka yang unik, yang memungkinkan penyesuaian dan fleksibilitas yang lebih baik.
Karena runtime inferensi inti ada di TFLite, seluruh pipeline bisa diintegrasikan dengan mudah ke dalam aplikasi Android (termasuk di Google Play) atau aplikasi iOS Anda tanpa modifikasi apa pun. Hal ini akan memastikan model yang dikonversi dari Generative API baru akan langsung dapat diterapkan hanya dengan menambahkan beberapa dependensi operasi khusus. Pada rilis mendatang, kami akan menghadirkan dukungan GPU untuk Android & iOS, serta menargetkan akselerator ML (TPU, NPU).
Model Explorer yang baru saja diumumkan adalah alat yang berguna untuk memvisualisasikan model besar seperti Gemma 2B. Tampilan hierarkis dan perbandingan berdampingan memudahkan Anda memvisualisasikan versi model asli / ditulis ulang / dikonversi. Untuk detail selengkapnya mengenai hal ini dan bagaimana Anda bisa memvisualisasikan info tolok ukur untuk penyetelan performa, lihat postingan blog ini.
Di bawah ini adalah contoh bagaimana kami menggunakannya ketika menulis model PyTorch TinyLlama – menunjukkan model PyTorch export() bersama dengan model TFLite. Menggunakan Model Explorer, kita bisa dengan mudah membandingkan bagaimana setiap lapisan (mis. RMSNorms, SelfAttention) diekspresikan.
AI Edge Torch Generative API adalah pendukung yang kuat untuk model yang telah dioptimalkan sebelumnya dan tersedia di Mediapipe LLM inference API untuk developer yang ingin mengaktifkan model AI generatif mereka di perangkat. Dalam beberapa bulan mendatang, kami akan menghadirkan update baru, termasuk dukungan web, kuantisasi yang ditingkatkan, dan dukungan komputasi yang lebih luas di luar CPU. Kami juga tertarik untuk mengeksplorasi integrasi framework yang lebih baik lagi.
Ini adalah pratinjau awal library, yang sedang dalam tahap eksperimental dengan tujuan untuk melibatkan komunitas developer. Perlu diingat bahwa API dapat berubah, masih belum sempurna, dan dukungan terbatas untuk kuantisasi dan model. Namun, ada banyak hal yang bisa dimulai dalam repo GitHub kami - silakan bergabung dan jangan ragu untuk membagikan PR, masalah, dan permintaan fitur.
Pada bagian 3 seri ini, kita akan melihat lebih mendalam mengenai alat visualisasi Model Explorer yang memungkinkan developer untuk memvisualisasikan, mendebug, dan mengeksplorasi model.
Proyek ini merupakan kolaborasi dari beberapa tim fungsional di Google. Kami ingin mengucapkan terima kasih kepada semua anggota tim yang telah berkontribusi dalam pekerjaan ini: Aaron Karp, Advait Jain, Akshat Sharma, Alan Kelly, Andrei Kulik, Arian Afaian, Chun-nien Chan, Chuo-Ling Chang, Cormac Brick, Eric Yang, Frank Barchard, Gunhyun Park, Han Qi, Haoliang Zhang, Ho Ko, Jing Jin, Joe Zoe, Juhyun Lee, Kevin Gleason, Khanh LeViet, Kris Tonthat, Kristen Wright, Lin Chen, Linkun Chen, Lu Wang, Majid Dadashi, Manfei Bai, Mark Sherwood, Matthew Soulanille, Matthias Grundmann, Maxime Brénon, Michael Levesque-Dion, Mig Gerard, Milen Ferev, Mohammadreza Heydary, Na Li, Paul Ruiz, Pauline Sho, Pei Zhang, Ping Yu, Pulkit Bhuwalka, Quentin Khan, Ram Iyengar, Renjie Wu, Rocky Rhodes, Sachin Kotwani, Sandeep Dasgupta, Sebastian Schmidt, Siyuan Liu, Steven Toribio, Suleman Shahid, Tenghui Zhu, T.J. Alumbaugh, Tyler Mullen, Weiyi Wang, Wonjoo Lee, Yi-Chun Kuo, Yishuang Pang, Yu-hui Chen, Zoe Wang, Zichuan Wei.

Gemma untuk Streaming ML dengan Dataflow

TensorFlow Lite sekarang menjadi LiteRT

Model Explorer: Menyederhanakan model ML untuk perangkat Edge

Membangun game petualangan berbasis teks dengan Gemma 2

Indie Games Fund: Google Play’s $2m fund in Latin America is back
Update untuk API Google Foto: Peluncuran Picker API dan perubahan Library API