

Pada postingan sebelumnya dari seri penjelasan Gemma, kami telah membahas arsitektur Gemma 2 terbaru. Dalam postingan ini, Anda akan menjelajahi arsitektur RecurrentGemma. Mari kita mulai!
RecurrentGemma berbasis pada Griffin, model hibrida yang memadukan gated linear recurrences dengan local sliding window attention. Perubahan ini meningkatkan komputasi dan memori sehingga lebih cocok untuk prompt konteks panjang.
Namun, pendekatan ini memiliki kelemahan, yaitu berkurangnya performa jarum pada tumpukan jerami karena ukuran arsitektur Griffin yang tetap. Meskipun Anda bisa menyediakan seluruh teks dari buku sebagai input, pendekatan ini mungkin tidak optimal. Recurrent Neural Networks (RNN) dapat mengalami kesulitan saat mempelajari dependensi jarak jauh dalam urutan yang sangat panjang, dan model ini memiliki jendela konteks yang terbatas. Artinya, model ini hanya bisa secara efektif mempertimbangkan beberapa token sebelumnya ketika membuat prediksi.
Selain itu, model recurrent belum mendapat banyak perhatian dalam hal pengoptimalan waktu inferensi dibandingkan model transformer. Dan penelitian serta dukungan komunitas model ini lebih sedikit dibandingkan dengan arsitektur transformer yang sudah mapan.
Jadi, model ini akan sangat berharga dalam skenario ketika Anda khawatir akan kehabisan jendela konteks LLM. Dengan memprioritaskan informasi terbaru dan secara strategis menghapus data lama, RecurrentGemma memastikan bahwa performa LLM tetap kuat seiring dengan bertambah luasnya konteks.
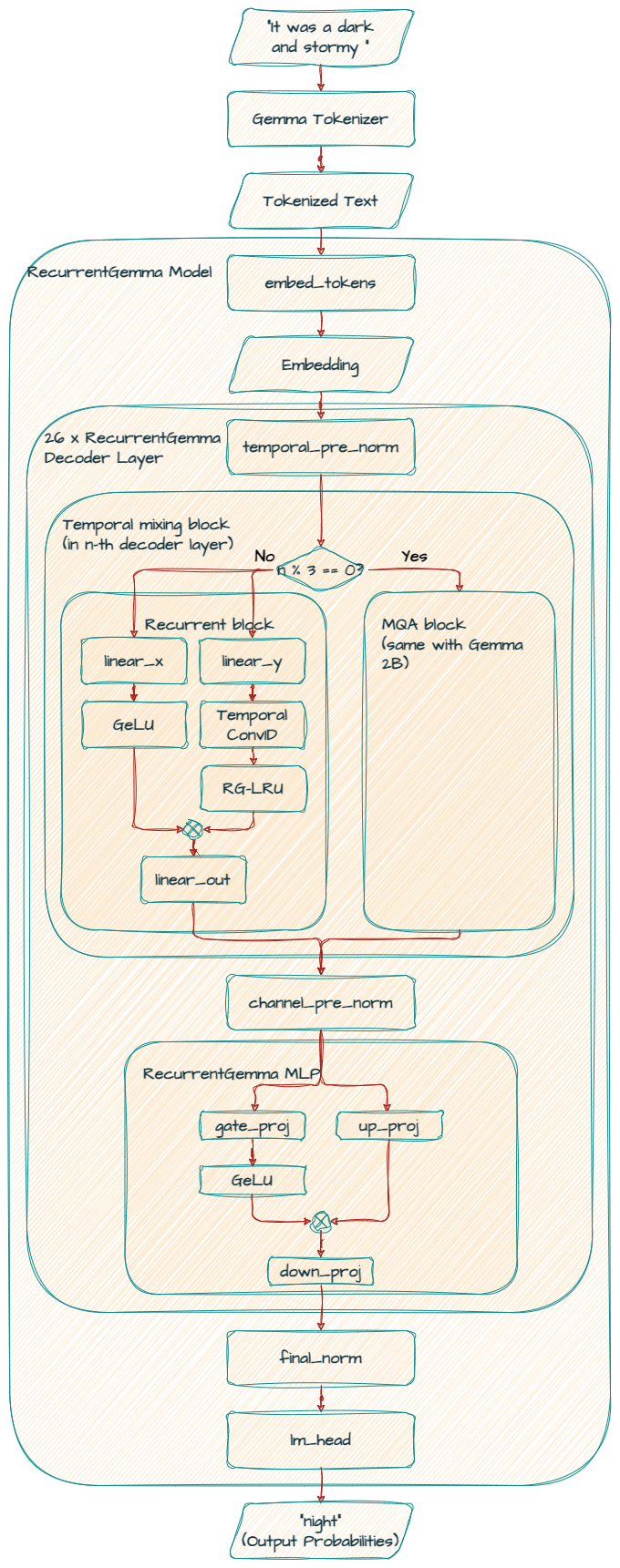
Di bawah ini adalah diagram arsitektur untuk model Recurrent Gemma 2B.
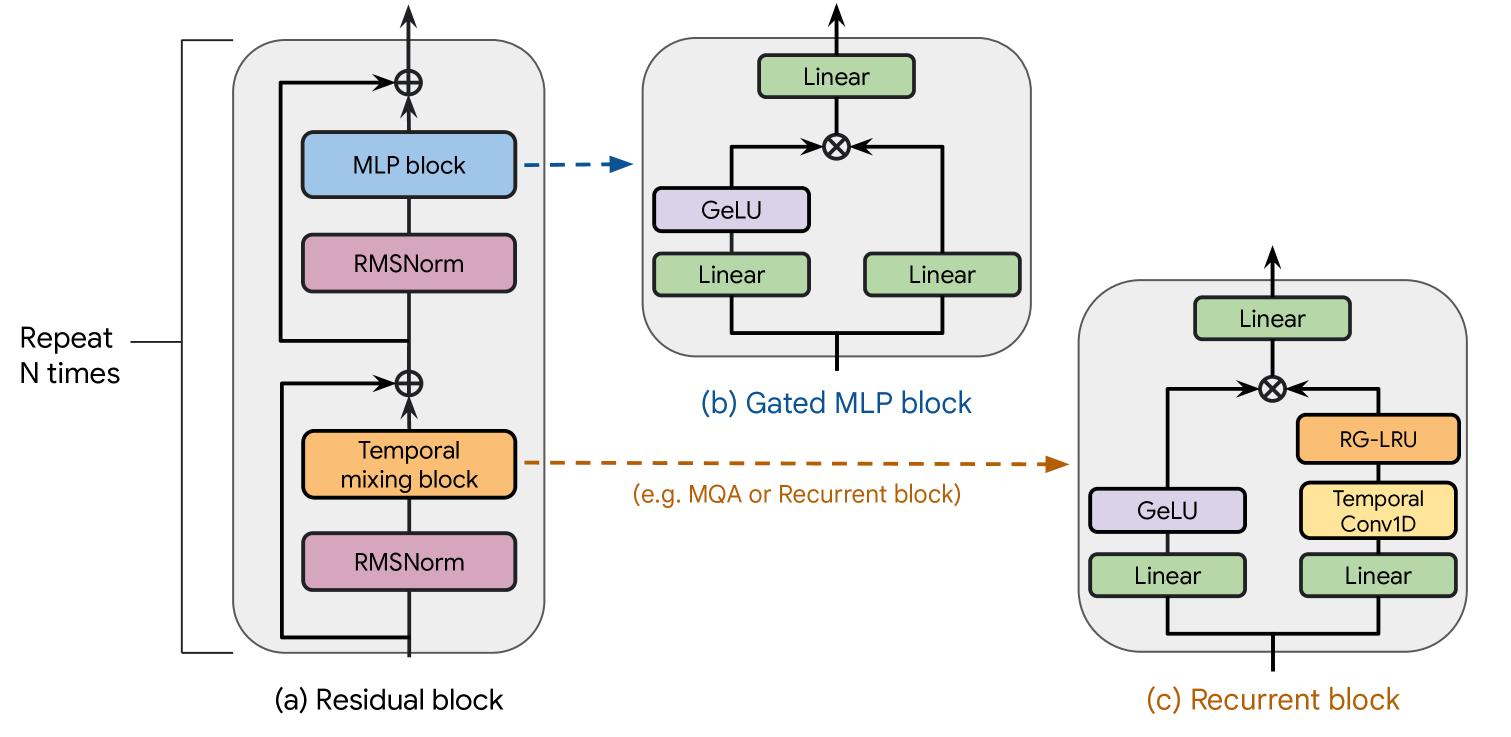
Griffin mengikuti pola residual dan blok MLP yang sama dengan baseline Transformer lainnya. Namun, tidak seperti baseline MQA Transformer dan model Hawk, Griffin menggunakan penggabungan antara blok recurrent dan MQA.
Griffin menggunakan struktur berlapis dengan menggabungkan dua blok residual dengan sebuah blok recurrent secara bergantian, diikuti dengan blok residual yang menggabungkan blok perhatian MQA lokal.
Parameter inti arsitektur diringkas dalam tabel di bawah ini.

Parameter non-sematan didistribusikan ke seluruh lapisan tersembunyi model, dalam komponen seperti mekanisme perhatian dan jaringan feedforward.
Catatan: Penamaan model “2B” berasal dari parameter ini
Parameter Sematan biasanya ditemukan di lapisan khusus yang disebut lapisan sematan. Lapisan ini bertanggung jawab untuk memetakan token terpisah (seperti kata atau karakter) ke dalam representasi vektor berkelanjutan (sematan).
Catatan: 0.7B dapat dihitung sebagai 256 ribu (ukuran kosakata) x 2560 (lebar model)
Lebar model mengacu pada ukuran lapisan tersembunyi di dalam model, yang menentukan kapasitas model untuk merepresentasikan pola-pola yang kompleks, seperti halnya Model Gemma dasar.
Lebar recurrent neural network (RNN) adalah ukuran keadaan tersembunyi yang dipertahankan oleh Real-Gated Linear Recurrent Unit (RG-LRU). Tidak seperti Transformer tradisional, blok recurrent mempertahankan keadaan internal dengan ukuran tetap, terlepas dari panjang inputnya. Ini memungkinkan RecurrentGemma untuk memproses urutan yang lebih panjang dengan lebih sedikit memori, membuatnya lebih efisien untuk tugas-tugas seperti pembuatan kode atau artikel yang panjang.
Ini sama dengan dimensi tersembunyi feedforward dalam model Gemma dasar. Untuk mempermudah, kami menerapkan faktor ekspansi sebesar 3 pada model Recurrent Gemma, yang menghasilkan dimensi MLP sebesar 7680 (dihitung menggunakan 2560 x 3).
Keadaan yang dijaga oleh RecurrentGemma memiliki ukuran yang terbatas dan tidak bertambah dengan urutan yang lebih panjang dari jendela perhatian lokal 2 ribu token. Ini berarti bahwa meskipun panjang maksimum contoh yang dihasilkan secara autoregresif oleh Gemma dibatasi oleh kapasitas memori sistem host, RecurrentGemma bisa menghasilkan urutan dengan panjang yang berubah-ubah untuk mengatasi kendala ini.
RecurrentGemmaForCausalLM(
(model): RecurrentGemmaModel(
(embed_tokens): Embedding(256000, 2560, padding_idx=0)
(layers): ModuleList(
(0-1): 2 x RecurrentGemmaDecoderLayer(
(temporal_pre_norm): RecurrentGemmaRMSNorm()
(temporal_block): RecurrentGemmaRecurrentBlock(
(linear_y): Linear(in_features=2560, out_features=2560, bias=True)
(linear_x): Linear(in_features=2560, out_features=2560, bias=True)
(linear_out): Linear(in_features=2560, out_features=2560, bias=True)
(conv_1d): Conv1d(2560, 2560, kernel_size=(4,), stride=(1,), padding=(3,), groups=2560)
(rg_lru): RecurrentGemmaRglru()
(act_fn): PytorchGELUTanh()
)
(channel_pre_norm): RecurrentGemmaRMSNorm()
(mlp_block): RecurrentGemmaMlp(
(gate_proj): Linear(in_features=2560, out_features=7680, bias=True)
(up_proj): Linear(in_features=2560, out_features=7680, bias=True)
(down_proj): Linear(in_features=7680, out_features=2560, bias=True)
(act_fn): PytorchGELUTanh()
)
)
(2): RecurrentGemmaDecoderLayer(
(temporal_pre_norm): RecurrentGemmaRMSNorm()
(temporal_block): RecurrentGemmaSdpaAttention(
(q_proj): Linear(in_features=2560, out_features=2560, bias=False)
(k_proj): Linear(in_features=2560, out_features=256, bias=False)
(v_proj): Linear(in_features=2560, out_features=256, bias=False)
(o_proj): Linear(in_features=2560, out_features=2560, bias=True)
(rotary_emb): RecurrentGemmaRotaryEmbedding()
)
(channel_pre_norm): RecurrentGemmaRMSNorm()
(mlp_block): RecurrentGemmaMlp(
(gate_proj): Linear(in_features=2560, out_features=7680, bias=True)
(up_proj): Linear(in_features=2560, out_features=7680, bias=True)
(down_proj): Linear(in_features=7680, out_features=2560, bias=True)
(act_fn): PytorchGELUTanh()
)
)
:
(23): RecurrentGemmaDecoderLayer(
(temporal_pre_norm): RecurrentGemmaRMSNorm()
(temporal_block): RecurrentGemmaSdpaAttention(
(q_proj): Linear(in_features=2560, out_features=2560, bias=False)
(k_proj): Linear(in_features=2560, out_features=256, bias=False)
(v_proj): Linear(in_features=2560, out_features=256, bias=False)
(o_proj): Linear(in_features=2560, out_features=2560, bias=True)
(rotary_emb): RecurrentGemmaRotaryEmbedding()
)
(channel_pre_norm): RecurrentGemmaRMSNorm()
(mlp_block): RecurrentGemmaMlp(
(gate_proj): Linear(in_features=2560, out_features=7680, bias=True)
(up_proj): Linear(in_features=2560, out_features=7680, bias=True)
(down_proj): Linear(in_features=7680, out_features=2560, bias=True)
(act_fn): PytorchGELUTanh()
)
)
(24-25): 2 x RecurrentGemmaDecoderLayer(
(temporal_pre_norm): RecurrentGemmaRMSNorm()
(temporal_block): RecurrentGemmaRecurrentBlock(
(linear_y): Linear(in_features=2560, out_features=2560, bias=True)
(linear_x): Linear(in_features=2560, out_features=2560, bias=True)
(linear_out): Linear(in_features=2560, out_features=2560, bias=True)
(conv_1d): Conv1d(2560, 2560, kernel_size=(4,), stride=(1,), padding=(3,), groups=2560)
(rg_lru): RecurrentGemmaRglru()
(act_fn): PytorchGELUTanh()
)
(channel_pre_norm): RecurrentGemmaRMSNorm()
(mlp_block): RecurrentGemmaMlp(
(gate_proj): Linear(in_features=2560, out_features=7680, bias=True)
(up_proj): Linear(in_features=2560, out_features=7680, bias=True)
(down_proj): Linear(in_features=7680, out_features=2560, bias=True)
(act_fn): PytorchGELUTanh()
)
)
)
(final_norm): RecurrentGemmaRMSNorm()
)
(lm_head): Linear(in_features=2560, out_features=256000, bias=False)
)
Mengambil teks input sebagai urutan token dan memetakan setiap token ke representasi vektor berkelanjutan dengan ukuran 2560. Ia memiliki ukuran kosakata 256000 yang sama dengan model Gemma dasar.
Secara keseluruhan terdapat 26 lapisan dekoder, yang dikelompokkan ke dalam pola yang berulang.
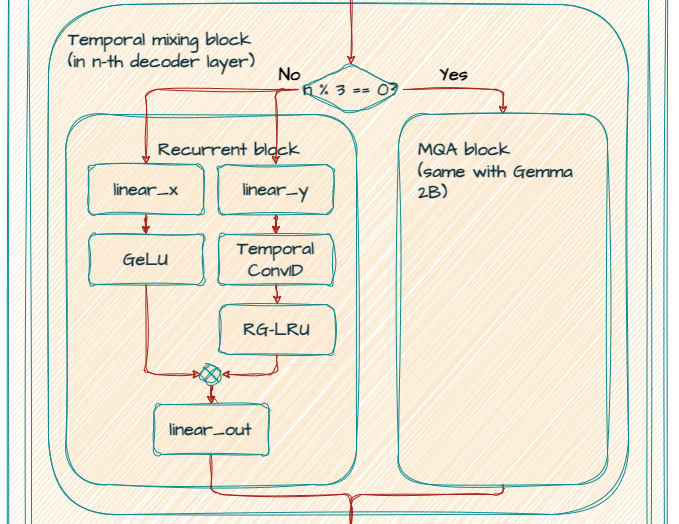
Model ini dimulai dengan dua blok residual dengan blok recurrent (0-1). Urutan ini kemudian diikuti oleh blok residual (2) dan rangkaian blok berkelanjutan secara bergantian hingga akhir lapisan (25).

Pada blok recurrent (Temporal mixing block), model mengambil input dengan dimensi (Lebar model) 2560 dan menerapkan dua lapisan linear dengan dimensi output (lebar RNN) 2560 secara paralel, menciptakan dua cabang.
Pada cabang pertama (sisi kanan), ia menerapkan lapisan Conv1D kecil yang dapat dipisahkan dengan dimensi filter temporal 4. Dan lapisan RG-LRU (Real-Gated Linear Recurrent Unit) mengikuti.
Pada cabang kedua (sisi kiri), ia menerapkan nonlinearitas GeLU.
Dan kemudian menggabungkan cabang dengan multiplikasi menurut elemen, menerapkan lapisan linear akhir dengan dimensi output (Lebar model) 2560.
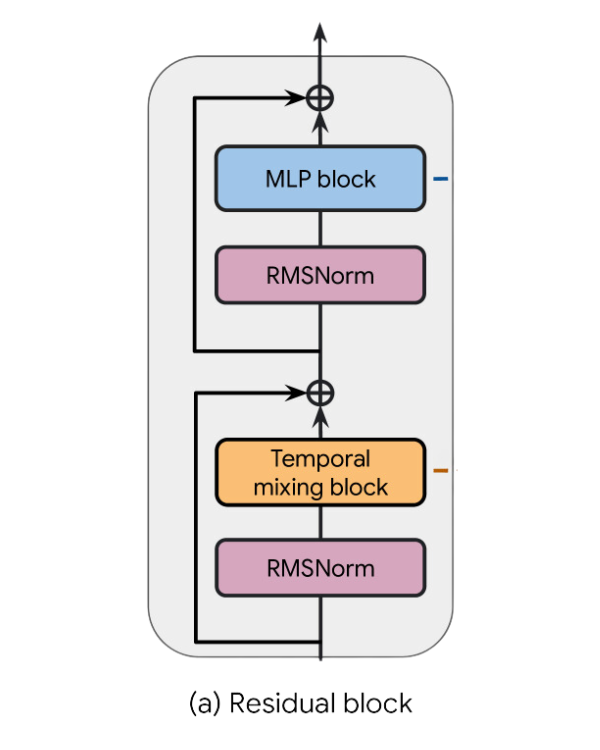
Setelah menerapkan RMSNorm, blok MLP akan mengikuti.
Setelah memiliki dua blok residual dengan blok recurrent (0-1), sebuah blok residual dengan MQA lokal (2) mengikuti. Salah satu kelemahan utama dari penggunaan perhatian global adalah kompleksitas komputasinya meningkat secara kuadratik seiring dengan panjangnya urutan. Untuk mengatasi hal ini, RecurrentGemma menggunakan local sliding window attention. Ini memungkinkan setiap posisi agar hanya memperhatikan beberapa token di masa lalu.
Pada blok MQA lokal (Temporal mixing block), model mengambil input dimensi (Lebar model) 2560. Model ini menggunakan proyeksi linear (q_proj, k_proj, v_proj, o_proj) untuk membuat kueri, kunci, nilai, dan representasi output. Perhatikan bahwa out_features untuk k_proj dan v_proj adalah 256 karena mereka berbagi head yang sama dengan ukuran 256, sementara q_proj dan o_proj memiliki 10 head (256 x 10 = 2560) secara paralel.
Ini menggabungkan rotary_emb (RecurrentGemmaRotaryEmbedding) untuk rotary positional embeddings (RoPE) seperti halnya model Gemma dasar.
Mengaplikasikan RMSNorm dan blok MLP sama dengan blok residual sebelumnya.
Dalam artikel ini, Anda telah mempelajari tentang RecurrentGemma.
Pada postingan berikutnya, Anda akan menjelajahi PaliGemma yang merupakan model bahasa visi (VLM) terbuka yang ringan.
Nantikan informasi selanjutnya dan terima kasih telah membaca!

Penjelasan Gemma: Arsitektur PaliGemma

Memperkenalkan Keras Hub: Pusat library terpadu untuk model yang sudah terlatih

Gemini is now accessible from the OpenAI Library
Menuju Pemahaman Global – Memajukan AI Multibahasa dengan Gemma 2 dan Tantangan $150.000

Supercharging AI Coding Assistants with Gemini Models' Long Context