


Abstract
Allostery is considered important in regulating protein's activity. Drug development depends on the understanding of allosteric mechanisms, especially the identification of allosteric sites, which is a prerequisite in drug discovery and design. Many computational methods have been developed for allosteric site prediction using pocket features and protein dynamics. Here, we present an ensemble learning method, consisting of eXtreme gradient boosting and graph convolutional neural network, to predict allosteric sites. Our model can learn physical properties and topology without any prior information, and shows good performance under multiple indicators. Prediction results showed that 84.9% of allosteric pockets in the test set appeared in the top 3 positions. The PASSer: Protein Allosteric Sites Server (https://passer.smu.edu), along with a command line interface (https://github.com/smutaogroup/passerCLI) provide insights for further analysis in drug discovery.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Allostery is the process in which proteins transmit the perturbation caused by the effect of binding at one site to a distal functional site [1]. The allosteric process is fundamental in the regulation of activity. Compared with non-allosteric drugs, allosteric drugs have many advantages: they are conserved and highly specific [2]; they can either activate or inhibit proteins; they can be used in conjunction with orthosteric (non-allosteric) drugs. Although allosteric drugs are important in the pharmaceutical industry [3], they are still poorly understood [4]. Most allosteric mechanisms remain elusive because of the difficulty of identifying potential allosteric sites [5].
Many allosteric site prediction methods have been developed based on molecular dynamics (MD) simulations [6], normal mode analysis [7], two-state G models [8] and machine learning (ML) models [9–11]. Among the existing methods, AllositePro [12], AlloPred [13], SPACER [14] and PARS [15] are available as web servers or open-source packages. These previous studies have shown that it is promising to identify allosteric sites by combining static pocket features with protein dynamics. In these studies, static features are calculated by site descriptors describing physical properties of protein pockets, while the protein dynamics are extracted by MD simulation or perturbation.
models [8] and machine learning (ML) models [9–11]. Among the existing methods, AllositePro [12], AlloPred [13], SPACER [14] and PARS [15] are available as web servers or open-source packages. These previous studies have shown that it is promising to identify allosteric sites by combining static pocket features with protein dynamics. In these studies, static features are calculated by site descriptors describing physical properties of protein pockets, while the protein dynamics are extracted by MD simulation or perturbation.
ML methods have been shown to be superior in the classification of protein pockets. For example, Allosite [11] and AlloPred [13] used support vector machine (SVM) [16] with optimized features. Chen et al [17] used random forest (RF) [18] to construct a three-way predictive model. With the development of ML, more advanced models have been developed and can contribute to the allosteric site classification. eXtreme gradient boosting (XGBoost) [19] is one of the most powerful ML techniques in classification. It is an implementation of the gradient boosting algorithm with regularized terms to reduce overfitting. Compared with SVM and RF, XGBoost achieved superior predictive performance in the protein–protein interactions [20] and hot spots [21].
Though physical properties are largely contained in many methods, topological information is largely ignored and is considered important in classifying pockets. In order to explore the geometry features, an atomic graph is constructed for each pocket. Atoms are treated as nodes and the pairwise bond distances are calculated as edges [9]. Graph convolutional neural networks (GCNNs) [22], a popular concept in deep learning, have been applied in biological-related predictions, ranging from chemical reactions [23], molecular properties [24], to drug-target interactions [25].
In this study, protein pockets are predicted using an ensemble learning method, which combines the results of XGBoost and GCNN. This model can learn both physical properties and topology information of allosteric pockets and has been proven to be superior to the single XGBoost and GCNN models. Various performance indicators validated the success of this ensemble learning method compared with previous methods.
2. Methods
2.1. Protein database
The data used in the current work was collected from the Allosteric Database (ASD) [26]. There are a total of 1946 entries information of allosteric sites with different proteins and modulators. To ensure data quality, 90 proteins were selected using previous rules [11]: protein structures with either resolution below 3Å or missing residues in the allosteric sites were removed; redundant proteins in the rest of the data that have more than 30% sequence identity were filtered out. The names and IDs of the 90 proteins extracted from the PDB [27, 28] are listed in table S1 (is available online at stacks.iop.org/MLST/2/035015/mmedia).
2.2. Site descriptors
FPocket algorithm [29] is used to detect pockets from the surface of the selected proteins. A pocket is labeled as either 1 (positive) if it contains at least one residue identified as binding to allosteric modulators or 0 (negative) if it does not contain such residues. Therefore, a single protein structure may have more than one positive label. A total of 2246 pockets were detected with 119 pockets being labeled as allosteric sites. There are 19 features calculated by the FPocket as shown in table S2.
2.3. Pearson correlation coefficient
Pearson correlation coefficient (PCC) measures the linear correlation of two variables. Given a pair of variables X and Y as  , PCC (rX,Y
) is calculated as
, PCC (rX,Y
) is calculated as

where n is the sample size and  are sample means. PCC has a value between −1 and +1. Positive value represents a positive correlation, and negative value represents a negative correlation. The absolute value indicates the degree of correlation. The larger the absolute value, the stronger the correlation.
are sample means. PCC has a value between −1 and +1. Positive value represents a positive correlation, and negative value represents a negative correlation. The absolute value indicates the degree of correlation. The larger the absolute value, the stronger the correlation.
2.4. eXtreme gradient boosting
XGBoost is an ensemble learning method that combines several decision trees in sequence.
Let  represents a dataset with m features and n labels. The jth decision tree in XGBoost predicts a sample
represents a dataset with m features and n labels. The jth decision tree in XGBoost predicts a sample  by
by

where wq is the leaf weights of this decision tree. The final prediction of XGBoost is given by the summation of predictions from each decision tree:

where M is the total number of decision trees. To overcome overfitting introduced by decision trees, the objective function in XGBoost is composed of a loss function l and a regularization term Ω:

where  with T represents the number of leaves and γ, λ are regularization parameters.
with T represents the number of leaves and γ, λ are regularization parameters.
During training, XGBoost iteratively adds new decision trees. The prediction of the tth iteration is expressed as

Correspondingly, the objective function of the tth iteration is

XGBoost introduces both first derivative and second derivative of the loss function. By applying Taylor expansion on the objective function at second order, the objective function of the tth iteration can be expressed as

XGBoost can predict the labels of sample data with corresponding probabilities. For one pocket, XGBoost outputs the probability of this pocket being an allosteric pocket. This pocket is labeled as positive (allosteric) if the predicted probability is over 50% or negative otherwise.
There are only 5.3% of positive labels in this binary classification job, which means that the input data is highly imbalanced. To focus more on the limited positive labels, XGBoost uses 'scale_pos_weight', a parameter for controlling the balance of positive and negative weights. A typical value of this weight equals to the number of negative samples versus the number of positive samples.
In the current study, the maximum tree depth for base learners and the weights for positive labels were fine-tuned while keeping other parameters as default values. The XGBoost algorithm is implemented using Scikit-learn package [30] version 0.23.2.
2.5. Graph convolutional neural network
The GCNN in this work follows this formula [22]:

where H(l) and H(l + 1) represents the lth and l + 1th layer, respectively.  , where N is the number of nodes and D is the number of features. Rectified linear unit (ReLU(x) = max(0, x)) is used as the activation function. W(l) denotes the weight matrix in the lth layer. D and A represent degree matrix and adjacent matrix, respectively, with
, where N is the number of nodes and D is the number of features. Rectified linear unit (ReLU(x) = max(0, x)) is used as the activation function. W(l) denotes the weight matrix in the lth layer. D and A represent degree matrix and adjacent matrix, respectively, with  . Renormalization (indicated by the ∼ symbol) is applied for the undirected graph G where each node is added with a self-connection. Therefore,
. Renormalization (indicated by the ∼ symbol) is applied for the undirected graph G where each node is added with a self-connection. Therefore,  where IN
is the identity matrix.
where IN
is the identity matrix.
A graph readout is calculated through the average of node features for each graph:

where hg
is the readout result of graph g and hv
is the node feature in node v.  represents the nodes in graph g.
represents the nodes in graph g.
An example of 1-layer GCNN model is shown in figure 1. A graph is first fed into a convolution layer. The in-degree and out-degree of a node refer to the number of edges coming into and going out from that node, respectively. In-degree of each node was calculated as the node feature. Graph feature is calculated as the average of node features in the readout layer with ReLU activation function. The output was further fed into a linear classification layer g, which predicts the probability of being an allosteric pocket. Previous research [31] has shown the limitations of 1-layer GCNN. In the current study, atomic graphs of each protein pocket are constructed and fed into a 2-layer GCNN model. This model consists of two graph convolution layers, each with 256 dimensions of a hidden node feature vector, followed by a readout layer and a linear classification layer. The node degree is used as the initial node feature. The in-degree is the same as the out-degree in an undirected atomic graph. Graph representation is calculated as the average of node representations. The linear classification layer outputs the probabilities of pockets being allosteric sites.

Figure 1. Architecture of 1-layer GCNN model. 1-layer GCNN is composed of a graph convolution layer, a readout layer and a linear classification layer. Rectified linear unit is used as the activation function. An atomic graph is constructed for a given pocket and GCNN predicts the probability of this pocket being an allosteric site.
Download figure:
Standard image High-resolution imageTo overcome the potential limitation in training GCNN with an imbalanced dataset, the ratio between negative labels and positive labels was fine-tuned. Specifically, in each protein, allosteric pockets (positive samples) were fully used, while non-allosteric pockets (negative samples) were partially used. Each negative sample was randomly selected, and the total number of non-allosteric pockets equals the number of allosteric pockets times the ratio value.
In constructing atomic graphs, the threshold of bond distance was also fine-tuned. Each atom was considered as a node in the atomic graph and the pairwise distances between atoms were calculated. If the distance is below a specified threshold, an edge is constructed connecting the two related nodes. Thus, the distance threshold controls the degree of local connectivity.
The GCNN model is implemented using deep graph library package [32] version 0.4.3.
2.6. Performance indicators
For binary classification, the results can be classified as table 1. Various indicators were used to quantify model performance: precision (TP / (TP + FP)) measures how well the model can predict real positive labels; accuracy ((TP + TN) / (TP + FP + FN + TN)) measures the overall classification accuracy; recall (or sensitivity, TP / (TP + FN)) and specificity (TN / (TN + FP)) together measure the ability to classify TP and TN; F1 score (2 * precision * recall / (precision + recall)) is the weighted average of precision and recall. The higher the values of these indicators, the better the model's performance.
Table 1. Binary classification results. Confusion matrix can visualize and evaluate the performance of classification models. Rows represent the instances in predicted classes while columns represent the instances in real classes. True positive and true negative refer to the results where the model correctly predicts the positive and negative classes, respectively. Similarly, false positive and false negative refer to the results where the model incorrectly predicts the positive and negative classes, respectively.
| Real positive | Real negative | |
|---|---|---|
| Predicted positive | True positive (TP) | False negative (FN) |
| Predicted negative | False positive (FP) | True negative (TN) |
A receiver operating characteristic (ROC) curve was applied as another indicator to test model performance in binary classification. ROC curve is plotted as TP rate against FP rate with different threshold settings. The area under curve (AUC) is calculated for quantification. The upper limit for AUC value is 1.0. A dummy model should have an AUC value of 0.5.
The ranking information based on the predicted probabilities of protein pockets was also considered as an important indicator. Specifically, for each allosteric pocket, the ranking (predicted probability of being an allosteric site in descending order) was recorded and categorized as the first, second, third or other positions. The ranking result indicates how likely the allosteric pockets can appear in the top positions among all detected pockets in the same protein. A model with good performance should rank an allosteric pocket in the top positions.
3. Results
3.1. Feature exploration
The distribution of 19 features is shown in figure S1. While some exhibited long-tail distributions such as features 1 (Score) and 2 (Druggability score), data normalization is unnecessary since XGBoost does not require normal distribution. Instead, XGBoost, like other tree-based models, only focuses on the order, and whether features are normalized or not does not affect the prediction results. Violin plots are shown in figure S2 to better distinguish the feature distribution of allosteric sites and non-allosteric sites.
The correlation matrix between these features is shown in figure S3. Several features exhibited high correlations. For example, features 3 (Number of alpha spheres), 4 (Total SASA), 5 (Polar SASA), 6 (Apolar SASA), and 7 (Volume) are highly correlated with each other. Features 17 (Alpha sphere density) and 18 (Center of mass) are also strongly correlated with these five features.
For each feature value in a pocket, the inner ranking refers to the ranking position of this feature among values of other pockets in the same protein. Similar to the definition of inner ranking, the overall ranking refers to the ranking position of this feature value among values of other pockets in the overall dataset. Both sets of ranking features were normalized. The correlations between the original features and these two ranking feature sets were calculated and shown in figure S3. The high negative values indicate strongly negative correlations between the original features and the ranking features. While feature rankings were calculated and applied as additional features in a previous study [13], in the current dataset, the high correlation indicated that the ranking features provided little additional information and thus were discarded.
3.2. Prediction performance of XGBoost
XGBoost model can overcome the limitation of data imbalance by controlling the weight difference between negative labels and positive labels. This parameter was fine-tuned along with the maximum depth of trees. The results are plotted in figure 2. Two sets of parameters reached high F1 scores, and both were selected in the final model. The final XGBoost model is composed of two models, each with one set of parameters. The results in any given pocket are the averaged results predicted by these two models.

Figure 2. Fine-tuned results of weight and depth parameters in XGBoost model. Two sets of parameters, depth 5 weight 40 and depth 8 weight 40, exhibited exceptional high F1 score and were selected for further prediction.
Download figure:
Standard image High-resolution imageThe results of the fine-tuned XGBoost model are listed in table 2. Compared with the reference results, XGBoost model exhibited higher accuracy, precision, specificity, and ROC AUC values with comparable results in recall and F1 scores. Therefore, XGBoost model performs well in allosteric site prediction.
Table 2. Evaluation and performance comparison of different models. The average values and standard errors of 6 indicators are calculated in 10 independent runs. The ensemble learning method can achieve better performance compared to single XGBoost and GCNN models.
| Accuracy | Recall | Precision | Specificity | F1 score | ROC AUC | |
|---|---|---|---|---|---|---|
| XGBoost | 0.969 | 0.799 | 0.732 | 0.982 | 0.764 | 0.897 |
| ± 0.002a | ± 0.023 | ± 0.030 | ± 0.003 | ± 0.016 | ± 0.016 | |
| GCNN | 0.923 | 0.604 | 0.427 | 0.943 | 0.500 | 0.832 |
| ± 0.006 | ± 0.023 | ± 0.046 | ± 0.007 | ± 0.031 | ± 0.015 | |
| Model ensembling | 0.974 | 0.847 | 0.726 | 0.980 | 0.782 | 0.914 |
| ± 0.010 | ± 0.095 | ± 0.085 | ± 0.013 | ± 0.072 | ± 0.018 | |
| Allosite [11] | 0.962 | 0.852 | 0.688 | 0.970 | 0.761 | 0.911 |

3.3. Prediction performance of GCNN
Unlike XGBoost, GCNN models suffer from imbalanced dataset. To address this problem, the ratio between negative labels and positive labels was evaluated first. The results are plotted in figure 3(A). A ratio of 2 (number of negative labels: number of positive labels = 2:1) was selected. The distance threshold was further fine-tuned, and the results are plotted in figure 3(B).  was selected as the distance cutoff when constructing atomic graphs.
was selected as the distance cutoff when constructing atomic graphs.

Figure 3. Fine-tuned results of ratio and distance threshold parameters in GCNN model. (A) The ratio between number of negative labels and number of positive labels was fine-tuned. Ratio of 2 is considered reaching a balance between recall and precision. (B) The atomic distance threshold was fine-tuned from 7 to 11  . There is no significant increase in F1 score after
. There is no significant increase in F1 score after  , which is selected as the distance cutoff. For each parameter value, GCNN was run 10 times independently.
, which is selected as the distance cutoff. For each parameter value, GCNN was run 10 times independently.
Download figure:
Standard image High-resolution imageThe results of the fine-tuned GCNN model with 10 independent runs are listed in table 2. Compared with XGBoost, GCNNs are less effective in classifying allosteric sites. However, it is expected that combining XGBoost and GCNN will result in better performance than either model.
3.4. Prediction performance of model ensembling
The ensemble learning model is composed of both XGBoost model and GCNN model. For a given pocket, physical properties are calculated and fed into the XGBoost model; a representative atomic graph is fed into the GCNN model. The final result is calculated as the averaged probability of these two models. This final model contains both the physical properties and topological features of protein pockets. The combined results are listed in table 2. Compared with the XGBoost model, model ensembling leads to a 6.00% increase in recall, a 0.82% decrease in precision, and a 2.89% increase in F1 score. The AUC ROC value also had a 1.89% increase.
For each protein, the identified pockets are ranked based on the predicted probabilities. Overall, 60.7% of allosteric pockets are predicted as the first position, while 81.6% among the top 2 and 84.9% among the top 3. In other words, if a pocket is an allosteric pocket, there is a probability of 84.9% that it can be predicted in the top 3 among all detected pockets in the same protein. The prediction results, together with values reported in other studies, are listed in table 3. It should be noted that the types and amounts of proteins in the test set are different from each other.
Table 3. Probabilities of predicting allosteric sites in the top 3 positions. Ensemble learning method can rank an allosteric site in the top 3 positions with a probability of 84.9%, which is higher than previous results.
| Top 1 | Top 2 | Top 3 | |
|---|---|---|---|
| PARS [15] | 44% | 62% | 73% |
| AlloPred [13] | 57.5% | 70.0% | NAa |
| Ensemble learning | 60.7% | 81.6% | 84.9% |
3.5. Novel allosteric sites prediction
To test this ensemble learning method, two proteins not in the dataset (table S1) were used. The predicted allosteric pockets of these two proteins are illustrated in figure 4. These two proteins represent two different types of allosteric proteins. The second PDZ domain (PDZ2) is a dynamics-driven protein in human PTP1E protein which undergoes allosteric process upon binding with peptides [33]. The light-oxygen-voltage domain of Phaeodactylum tricornutum Aureochrome 1a (AuLOV) is a conformational-driven allosteric protein [34]. AuLOV is a monomer in the dark state and undergoes dimerization upon blue light perturbation [35]. In both cases, our prediction model ranks the allosteric sites as the top 1 with probabilities of 45.14% and 89.46%, respectively. This indicates that this model is capable of predicting both dynamics-driven and conformational-driven allosteric proteins. Apparently, the probability for the dynamics-driven allosteric protein is much smaller than the one of the conformational-driven allosteric protein, which is not unexpected.

Figure 4. Prediction results of two examples not included in the training set: (A) Dynamics-driven PDZ2 protein in bound states (PDB ID 3LNY); (B) the LOV domain of conformational-driven Phaeodactylum tricornutum Aureochrome 1a in dark state (PDB ID: 5DKK). Red regions are the most probable pockets in the predicted results with probabilities of (A) 45.14% and (B) 89.46% and are also the true allosteric sites.
Download figure:
Standard image High-resolution image3.6. Web and CLI usage
A web server based on the allosteric prediction method developed in this study is implemented using a Python web framework, Django. JSmol [36] is a JavaScript implementation of the Jmol package and is embedded in the web page for protein and pocket visualization. Web pages are rendered using Bootstrap. This server is named as Protein Allosteric Sites Server (PASSer). A workflow of PASSer is outlined in figure 5.
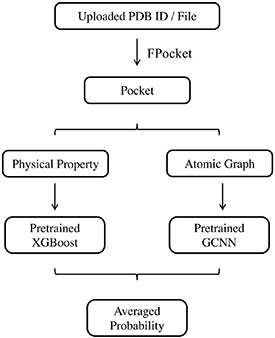
Figure 5. Web server workflow. User can upload either a PDB ID or a PDB file in the web server. FPocket is used to detect pockets. For each pocket, physical properties are calculated and predicted using a pretrained XGBoost model; while an atomic graph is constructed and fed into a pretrained GCNN model. The final probability is given by averaging results from both models.
Download figure:
Standard image High-resolution imageAn example of input and output of PASSer is displayed in figure 6. Users can submit a PDB ID if available or upload a custom PDB file as shown in figure 6(A). By default, all chains in the protein are analyzed. Prediction results are displayed as two parts: top 3 pockets with the highest probability rendered with the protein structure (figure 6(C)) and their probabilities (figure 6(B)). For each pocket, the corresponding residues can be retrieved by clicking the 'Show Residues' texts. Protein structure is visualized using JSmol. Each pocket is either displayed upon clicking its 'Load pocket' icon or hidden by clicking its 'Hide pocket' or overall 'Reset' icons.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 6. PASSer web server pages. (A) Users can either submit a PDB ID or a PDB file in the home page. (B) Predicted top 3 pockets are summarized in a table with corresponding probabilities and pocket residues. (C) Protein structures and pocket sites are displayed in an interactive window.
Download figure:
Standard image High-resolution image{kind=link}
A command line interface (CLI) is provided to facilitate potential developments. Similar with the web usage, this CLI can take either a PDB ID or a local PDB file for predictions.
4. Discussion
The quality of the dataset used for training is critical. Classification models often fail in prediction performance, and lack the generalization with poorly-collected datasets, such as insufficient training data or high similarity between structures. ASD is an online database that provides allosteric proteins and sites with high resolution, bringing opportunities for allosteric site prediction. There are other databases, such as ASBench [37] and sc-PDB [38], which can also be used to improve data quality and model performance.
In order to predict allosteric sites, proper pockets need to be identified on the surface of proteins. Several open-source pocket detection software has been developed. Previous results [29] have shown that, the geometry-based algorithm FPocket is superior to other methods, such as PASS [39] and LIGSITEcsc [40], and can cover known allosteric sites. In addition, FPocket is under active development and can be integrated with other methods to build a complete pipeline for site prediction.
Several computational methods have been developed for allosteric site prediction over the past few years. Due to the fast development of ML methods, many models integrate ML methods, such as SVM and RF, for accurate predictions [11, 17]. One critical issue is that, many ML models fail when dealing with imbalanced datasets [41]: in the allosteric site database, negative samples account for a majority of the dataset with a limited proportion of positive samples. Undersampling is one way to rebalance the dataset. For example, Allosite discarded some negative labels and used a ratio of 1:4 between positive and negative labels. However, undersampling leads to insufficient usage of the overall dataset. XGBoost, as a gradient boosting method, overcomes this data imbalance by controlling the relative weights between classes so that the dataset can be fully used. Various performance indicators, as listed in table 2, validated the effectiveness of XGBoost for the identification of allosteric sites.
It is worth noting that some features are highly correlated, as shown in figure S3. This collinearity should be addressed in regression models, which reduces the model precision and thus weakens prediction results. In contrast, XGBoost is free from this problem. When several features are found to be highly correlated to each other, XGBoost will choose one of these features. Therefore, collinearity does not affect the prediction results. Nevertheless, collinearity influences model interpretation, such as feature importance, which should be considered with caution.
Physical properties have been widely used to describe the characteristics of pockets. These features are normally calculated using static protein structures. To probe the dynamical behavior of pockets, normal mode analysis and MD simulations are normally conducted [7, 42]. Results from these methods have shown that models can achieve satisfactory performance through the combination of both static features and protein dynamics. However, pocket geometry is often ignored, which could play an important role in prediction. Therefore, a GCNN is applied to retain the topological information. Specifically, pockets are represented as undirected graphs at atomic level, and GCNN is designed to learn the local connectivity among atoms. While a previous study [9] included energy-weighted covalent and weak bonds in the prediction of allosteric sites, it should be noted here that: (1) it is assumed that the physical properties are explicitly retained in the site descriptors and GCNN only studies the node degree; (2) GCNN does not require any a prior information about the location of active sites. The ensemble learning method, consisting of GCNN and XGBoost, exhibited higher performance compared with single models.
5. Conclusion
The proposed ensemble learning method involves XGBoost and GCNN, which can learn both the physical properties and topology of protein pockets. The results are comparable with previous studies and have a higher percentage of ranking allosteric sites at top positions. The web server provides a user-friendly interface. Protein structures and top pockets are visualized in an interactive window on the result page. This ensemble learning method, embedded in the PASSer and CLI, can help exploration on protein allostery and drug development.
Code availability
The PASSer server is available at https://passer.smu.edu. The command line interface is available on GitHub at https://github.com/smutaogroup/passerCLI.
Acknowledgment
Computational time was generously provided by Southern Methodist University's Center for Research Computing. Research reported in this paper was supported by the National Institute of General Medical Sciences of the National Institutes of Health under Award No. R15GM122013. The authors would like to thank Kurt Pifer for his help in website development.
Data availability statement
The data that support the findings of this study are available upon reasonable request from the authors.
Conflict of interests
The authors declare no competing interests.