Workaround for discordant GWAS results between Glow, Hail, and statsmodel #391
Conversation
Codecov Report
@@ Coverage Diff @@
## master #391 +/- ##
==========================================
+ Coverage 93.64% 93.69% +0.05%
==========================================
Files 95 95
Lines 4814 4824 +10
Branches 472 466 -6
==========================================
+ Hits 4508 4520 +12
+ Misses 306 304 -2
Continue to review full report at Codecov.
|

|
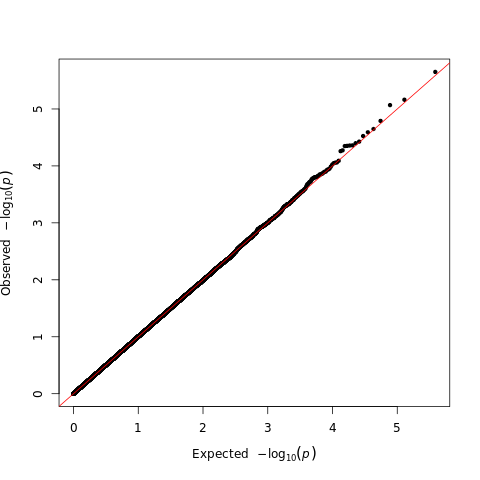
Hey @bcajes thanks for this! I replicated the inflation of P values with 30% missingness and 10k simulated samples
@henrydavidge what do you think? |

|
Firth regression seems fine:
|
|
@williambrandler can you share your code? |
|
hey @henrydavidge it's a series of notebooks, |
|
hey @henrydavidge I reran the analysis and updated the notebooks using just 100 samples and 1000 variants. You see the inflation for linear regression even at that level (and not in hail). So this scale of data can be used for unit testing |
|
hey @bcajes to fix DCO, #download the gh cli
|
* initial work Signed-off-by: Henry D <[email protected]> * add file Signed-off-by: Henry D <[email protected]> * workign score test Signed-off-by: Henry D <[email protected]> * seems to work Signed-off-by: Henry D <[email protected]> * continue Signed-off-by: Henry D <[email protected]> * offset support; more tests Signed-off-by: Henry D <[email protected]> * delete lin_reg.py Signed-off-by: Henry D <[email protected]> * add docs, few more tests Signed-off-by: Henry D <[email protected]> * add test file Signed-off-by: Henry D <[email protected]> * fix last test Signed-off-by: Henry D <[email protected]> * Fix docs, tests Signed-off-by: Henry D <[email protected]> * memory limit Signed-off-by: Henry D <[email protected]> * try explicitly broadcasting Signed-off-by: Henry D <[email protected]> * update environment Signed-off-by: Henry D <[email protected]> * undo explicit broadcast Signed-off-by: Henry D <[email protected]> * fix typo Signed-off-by: Henry D <[email protected]> * f97b0a5aee82445baa8bb4770a4a7ed0437dc6b13ormatting; karen's comment Signed-off-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
* fit null model with spark Signed-off-by: Henry D <[email protected]> * faster reshape Signed-off-by: Henry D <[email protected]> * add comments Signed-off-by: Henry D <[email protected]> * fix doc test Signed-off-by: Henry D <[email protected]> * fix test for spark 2 Signed-off-by: Henry D <[email protected]> * address comments Signed-off-by: Henry D <[email protected]> * karen comments Signed-off-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
* Include license file in source archive Signed-off-by: Henry D <[email protected]> * undo setup.py change Signed-off-by: Henry D <[email protected]> * Also include version.py Signed-off-by: Henry D <[email protected]> * remove unnecessary scikit-learn import Signed-off-by: Henry Davidge <[email protected]> Co-authored-by: Henry Davidge <[email protected]> Signed-off-by: brian cajes <[email protected]>
* initial work Signed-off-by: Henry D <[email protected]> * add file Signed-off-by: Henry D <[email protected]> * workign score test Signed-off-by: Henry D <[email protected]> * seems to work Signed-off-by: Henry D <[email protected]> * continue Signed-off-by: Henry D <[email protected]> * offset support; more tests Signed-off-by: Henry D <[email protected]> * delete lin_reg.py Signed-off-by: Henry D <[email protected]> * add docs, few more tests Signed-off-by: Henry D <[email protected]> * add test file Signed-off-by: Henry D <[email protected]> * fix last test Signed-off-by: Henry D <[email protected]> * WIP Signed-off-by: Karen Feng <[email protected]> * More work Signed-off-by: Karen Feng <[email protected]> * Fix docs, tests Signed-off-by: Henry D <[email protected]> * memory limit Signed-off-by: Henry D <[email protected]> * Correct param names Signed-off-by: Karen Feng <[email protected]> * try explicitly broadcasting Signed-off-by: Henry D <[email protected]> * Get it running Signed-off-by: Karen Feng <[email protected]> * Some clean up Signed-off-by: Karen Feng <[email protected]> * update environment Signed-off-by: Henry D <[email protected]> * undo explicit broadcast Signed-off-by: Henry D <[email protected]> * fix typo Signed-off-by: Henry D <[email protected]> * Clean up Signed-off-by: Karen Feng <[email protected]> * Replace penalized LL with deviance Signed-off-by: Karen Feng <[email protected]> * log likelihood is a single num Signed-off-by: Karen Feng <[email protected]> * Fix stderr Signed-off-by: Karen Feng <[email protected]> * Do not correct vanilla score test Signed-off-by: Karen Feng <[email protected]> * WIP Signed-off-by: Karen Feng <[email protected]> * Only binary level of residualization Signed-off-by: Karen Feng <[email protected]> * Values don't match Signed-off-by: Karen Feng <[email protected]> * Add y_mask Signed-off-by: Karen Feng <[email protected]> * Clean up Signed-off-by: Karen Feng <[email protected]> * Results from approx Firth don't match Signed-off-by: Karen Feng <[email protected]> * Tests match Signed-off-by: Karen Feng <[email protected]> * Clean up Signed-off-by: Karen Feng <[email protected]> * Clear warnings Signed-off-by: Karen Feng <[email protected]> * Working to match missing results Signed-off-by: Karen Feng <[email protected]> * Remove extra test Signed-off-by: Karen Feng <[email protected]> * yapf Signed-off-by: Karen Feng <[email protected]> * Some cleanup Signed-off-by: Karen Feng <[email protected]> * Add test case where half of SNPs are corrected Signed-off-by: Karen Feng <[email protected]> * Add correction col Signed-off-by: Karen Feng <[email protected]> * Add golden logistf results Signed-off-by: Karen Feng <[email protected]> * yapfAll Signed-off-by: Karen Feng <[email protected]> * Address comments Signed-off-by: Karen Feng <[email protected]> * More clean up Signed-off-by: Karen Feng <[email protected]> * Add test for missing samples Signed-off-by: Karen Feng <[email protected]> * Address comments Signed-off-by: Karen Feng <[email protected]> * Remove correction_method Signed-off-by: Karen Feng <[email protected]> * Fix lin reg Signed-off-by: Karen Feng <[email protected]> * Set min spark vsn Signed-off-by: Karen Feng <[email protected]> Co-authored-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
* firth fixes Signed-off-by: Henry D <[email protected]> * perf improvements Signed-off-by: Henry D <[email protected]> * fix Signed-off-by: Henry D <[email protected]> * add docs for contigs param Signed-off-by: Henry D <[email protected]> * renamings Signed-off-by: Henry D <[email protected]> * add test Signed-off-by: Henry D <[email protected]> * update lin_reg docs too Signed-off-by: Henry D <[email protected]> * fix typo Signed-off-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
* GWAS docs WIP Signed-off-by: Karen Feng <[email protected]> * Doc tests Signed-off-by: Karen Feng <[email protected]> * Clean up GWAS notebook Signed-off-by: Karen Feng <[email protected]> * Revert comment Signed-off-by: Karen Feng <[email protected]> * use add_intercept Signed-off-by: Karen Feng <[email protected]> * Store PCs in CSV Signed-off-by: Karen Feng <[email protected]> Signed-off-by: brian cajes <[email protected]>
* Improve glow.register behavior Signed-off-by: Henry D <[email protected]> * comment Signed-off-by: Henry D <[email protected]> * yapf Signed-off-by: Henry D <[email protected]> * typo Signed-off-by: Henry D <[email protected]> * tense Signed-off-by: Henry D <[email protected]> * update docs Signed-off-by: Henry D <[email protected]> * Remove unnecessary conf Signed-off-by: Henry D <[email protected]> * fix tests Signed-off-by: Henry D <[email protected]> * fix python test Signed-off-by: Henry D <[email protected]> * fixture Signed-off-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
* Make mean_substitute faster Signed-off-by: Henry D <[email protected]> * add a comment Signed-off-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
* first cut Signed-off-by: Henry D <[email protected]> * WIP, tests failing Signed-off-by: Karen Feng <[email protected]> * Multi-offset multi-missing test failing Signed-off-by: Karen Feng <[email protected]> * Fix test with copy Signed-off-by: Karen Feng <[email protected]> * WIP, regenie comparison test failing Signed-off-by: Karen Feng <[email protected]> * yapf Signed-off-by: Karen Feng <[email protected]> * Tests still failing Signed-off-by: Karen Feng <[email protected]> * Fix test by re-indexing after subtracting offset Signed-off-by: Karen Feng <[email protected]> * Add new test Signed-off-by: Karen Feng <[email protected]> * 3chr test and fix docs Signed-off-by: Karen Feng <[email protected]> * Add out-of-order offset test Signed-off-by: Karen Feng <[email protected]> * Address comments Signed-off-by: Karen Feng <[email protected]> * Only run tests on Spark 3+ Signed-off-by: Karen Feng <[email protected]> Co-authored-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
Signed-off-by: Karen Feng <[email protected]> Signed-off-by: brian cajes <[email protected]>
* WIP Signed-off-by: Karen Feng <[email protected]> * Cleanup Signed-off-by: Karen Feng <[email protected]> * More clean up Signed-off-by: Karen Feng <[email protected]> * Remove refs in notebooks Signed-off-by: Karen Feng <[email protected]> * Revert "Remove refs in notebooks" This reverts commit 2b17d20. Signed-off-by: Karen Feng <[email protected]> Signed-off-by: brian cajes <[email protected]>
* Add instructions to test code on a Databricks cluster Signed-off-by: Henry D <[email protected]> * list Signed-off-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
Signed-off-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
…reduction in binary WGR; Make addition of intercept to covariates consistent (projectglow#323) * revised design Signed-off-by: kianfar77 <[email protected]> * qt working Signed-off-by: kianfar77 <[email protected]> * repackage Signed-off-by: kianfar77 <[email protected]> * more changes and comments Signed-off-by: kianfar77 <[email protected]> * some tests fixed Signed-off-by: kianfar77 <[email protected]> * final Signed-off-by: kianfar77 <[email protected]> * final 1 Signed-off-by: kianfar77 <[email protected]> * Replace warnings with print Signed-off-by: Karen Feng <[email protected]> * Clean up caching Signed-off-by: Karen Feng <[email protected]> * Add tests Signed-off-by: Karen Feng <[email protected]> * cherry pick and fix Karen's changes Signed-off-by: kianfar77 <[email protected]> * fix absence of intercept for logistic regression Signed-off-by: kianfar77 <[email protected]> * fix doc tests Signed-off-by: kianfar77 <[email protected]> * remove comments Signed-off-by: kianfar77 <[email protected]> * revert notebook sources Signed-off-by: kianfar77 <[email protected]> * empty Signed-off-by: kianfar77 <[email protected]> * estimate_loco_offsets Signed-off-by: kianfar77 <[email protected]> * format Signed-off-by: kianfar77 <[email protected]> Co-authored-by: Karen Feng <[email protected]> Signed-off-by: brian cajes <[email protected]>
* Try fixing tests Signed-off-by: Karen Feng <[email protected]> * Change test order Signed-off-by: Karen Feng <[email protected]> Signed-off-by: brian cajes <[email protected]>
* Update GloWGR notebooks Signed-off-by: Henry D <[email protected]> * update more nbs Signed-off-by: Henry D <[email protected]> * Make mean_substitute faster (projectglow#329) * Make mean_substitute faster Signed-off-by: Henry D <[email protected]> * add a comment Signed-off-by: Henry D <[email protected]> update more notebooks update generated source Signed-off-by: Henry D <[email protected]> * more updates Signed-off-by: Henry D <[email protected]> * remove references to genomics runtime Signed-off-by: Henry D <[email protected]> * update glowgr notebooks Signed-off-by: Henry D <[email protected]> * fix typo Signed-off-by: Henry D <[email protected]> * karen's notebook comments Signed-off-by: Henry D <[email protected]> Signed-off-by: brian cajes <[email protected]>
* Split up tests Signed-off-by: Karen Feng <[email protected]> * Add missing param Signed-off-by: Karen Feng <[email protected]> Signed-off-by: brian cajes <[email protected]>
Signed-off-by: Henry Davidge <[email protected]> Co-authored-by: Henry Davidge <[email protected]> Signed-off-by: brian cajes <[email protected]>
Signed-off-by: Karen Feng <[email protected]> Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
…,-1] Signed-off-by: brian cajes <[email protected]>
…d now be encoded as [-1,-1] Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
* update link in wgr docs page Signed-off-by: William Brandler <[email protected]> * fix type Signed-off-by: William Brandler <[email protected]> * fix links in source code Signed-off-by: William Brandler <[email protected]> Signed-off-by: brian cajes <[email protected]>
* Update Python version Signed-off-by: Karen <[email protected]> Signed-off-by: brian cajes <[email protected]> * init prototype for exposing n, sum_x, and y_transpose_x, as is done in hail Signed-off-by: brian cajes <[email protected]> * remove extraneous test Signed-off-by: brian cajes <[email protected]> * add new stat fields to output schema Signed-off-by: brian cajes <[email protected]> * force n to be integer type Signed-off-by: brian cajes <[email protected]> * verbose_output=False by default; fleshout unit test Signed-off-by: brian cajes <[email protected]> * handle null genotype calls coming from hail to glow transformation Signed-off-by: brian cajes <[email protected]> * update linreg doc string with verbose_output option Signed-off-by: brian cajes <[email protected]> * integrating karen's feedback Signed-off-by: brian cajes <[email protected]> * attempt to cleanup whitespace Signed-off-by: brian cajes <[email protected]> * ran python/yapfAll Signed-off-by: brian cajes <[email protected]> * update update verbose_output doc Signed-off-by: brian cajes <[email protected]> * Fix Glow version in doc (projectglow#364) Signed-off-by: Dmitry Degrave <[email protected]> * update docs README.md (projectglow#385) * update docs README.md Signed-off-by: wbrandler <[email protected]> * fix typo Signed-off-by: wbrandler <[email protected]> * update readme Signed-off-by: wbrandler <[email protected]> * fix syntax Signed-off-by: William Brandler <[email protected]> * init prototype for exposing n, sum_x, and y_transpose_x, as is done in hail Signed-off-by: brian cajes <[email protected]> * remove extraneous test Signed-off-by: brian cajes <[email protected]> * add new stat fields to output schema Signed-off-by: brian cajes <[email protected]> * force n to be integer type Signed-off-by: brian cajes <[email protected]> * verbose_output=False by default; fleshout unit test Signed-off-by: brian cajes <[email protected]> * handle null genotype calls coming from hail to glow transformation Signed-off-by: brian cajes <[email protected]> * update linreg doc string with verbose_output option Signed-off-by: brian cajes <[email protected]> * integrating karen's feedback Signed-off-by: brian cajes <[email protected]> * attempt to cleanup whitespace Signed-off-by: brian cajes <[email protected]> * ran python/yapfAll Signed-off-by: brian cajes <[email protected]> * update update verbose_output doc Signed-off-by: brian cajes <[email protected]> * conform to glow convention of representing null genotype calls as [-1,-1] Signed-off-by: brian cajes <[email protected]> * revert null workaround in genotypeStates. Missing calls in hail should now be encoded as [-1,-1] Signed-off-by: brian cajes <[email protected]> * adding a but more detail to verbose output docs Signed-off-by: brian cajes <[email protected]> * making verbose variable names consistent Signed-off-by: brian cajes <[email protected]> * yapf Signed-off-by: brian cajes <[email protected]> * add type info to lin_reg verbose parameters Signed-off-by: brian cajes <[email protected]> * add type info to lin_reg verbose parameters Signed-off-by: brian cajes <[email protected]> * adding optimization suggested by henrydavidge Signed-off-by: brian cajes <[email protected]> Co-authored-by: Karen <[email protected]> Co-authored-by: dim de grave <[email protected]> Co-authored-by: williambrandler <[email protected]> Signed-off-by: brian cajes <[email protected]>
* WIP Signed-off-by: Karen Feng <[email protected]> * Cleanup Signed-off-by: Karen Feng <[email protected]> * Update pyspark Signed-off-by: Karen Feng <[email protected]> * Upgrade scalatest Signed-off-by: Karen Feng <[email protected]> * Null output is not Double-typed Signed-off-by: Karen Feng <[email protected]> * Disable nested schema pruning Signed-off-by: Karen Feng <[email protected]> * Eventually Signed-off-by: Karen Feng <[email protected]> * More upgrades Signed-off-by: Karen Feng <[email protected]> * Downgrade mockito Signed-off-by: Karen Feng <[email protected]> * Scalatest is out of date in Spark 2.x Signed-off-by: Karen Feng <[email protected]> * Shim FunSuite Signed-off-by: Karen Feng <[email protected]> * Update docs Signed-off-by: Karen Feng <[email protected]> * Fix python fx test Signed-off-by: Karen Feng <[email protected]> * Only bump Hail version for Spark 3 Signed-off-by: Karen Feng <[email protected]> * Set hail version Signed-off-by: Karen Feng <[email protected]> * Address comments Signed-off-by: Karen Feng <[email protected]> * Add warning about Spark version changes breaking Row ordering Signed-off-by: Karen Feng <[email protected]> Signed-off-by: brian cajes <[email protected]>
* update getting started guide Signed-off-by: William Brandler <[email protected]> * add glow logo Signed-off-by: William Brandler <[email protected]> * add html versions of notebooks Signed-off-by: William Brandler <[email protected]> * add source versions of notebooks Signed-off-by: William Brandler <[email protected]> * update getting started doc page Signed-off-by: William Brandler <[email protected]> * remove source notebook and regenerate with gen-nb-src.py Signed-off-by: William Brandler <[email protected]> * remove source notebook and regenerate with gen-nb-src.py Signed-off-by: William Brandler <[email protected]> * remove source notebook and regenerate with gen-nb-src.py Signed-off-by: William Brandler <[email protected]> * fix init script generation Signed-off-by: William Brandler <[email protected]> * add deep null example Signed-off-by: William Brandler <[email protected]> * make more concise Signed-off-by: William Brandler <[email protected]> * moving quickstart guide to databricks docs Signed-off-by: William Brandler <[email protected]> * update getting started links Signed-off-by: William Brandler <[email protected]> * update getting started formatting Signed-off-by: William Brandler <[email protected]> * remove github links Signed-off-by: William Brandler <[email protected]> Signed-off-by: brian cajes <[email protected]>
* add init script, job config, nb-test, notebooks, docs for hail interop Signed-off-by: wbrandler <[email protected]> * update hail notebook Signed-off-by: wbrandler <[email protected]> Signed-off-by: William Brandler <[email protected]> * fix hail notebook title Signed-off-by: William Brandler <[email protected]> * remove source notebook and regenerate with gen-nb-src.py Signed-off-by: William Brandler <[email protected]> * provide mapping for jobs config files Signed-off-by: William Brandler <[email protected]> * define params for notebook mapping function Signed-off-by: William Brandler <[email protected]> * define params for notebook mapping function Signed-off-by: William Brandler <[email protected]> * remove boilerplate, change function Signed-off-by: William Brandler <[email protected]> * define param Signed-off-by: William Brandler <[email protected]> Signed-off-by: brian cajes <[email protected]>
…pe samples (i.e. the user is no longer required to drop covariate samples upstream of linreg); remove manual slicing of covariates from unit test Signed-off-by: brian cajes <[email protected]>
Signed-off-by: brian cajes <[email protected]>
…ypes Signed-off-by: brian cajes <[email protected]>
|
@williambrandler did a bit of cleanup and added doc strings around intersect_samples 4ebc298. Finally got DCO to pass https://github.com/projectglow/glow/pull/391/checks, but the git rebase HEAD~58 --signoff operation makes the history quite ugly. There seems to be some sort of authorization error in the docs test. Everything else passes. |
|
thanks @bcajes oh yeah now it is saying Also plan to look into the authorization issue for the notebook tests tomorrow |
|
DCO fix caused some messy git history. Creating a new PR to clean it up. |
What changes are proposed in this pull request?
Potential workaround for discordant gwas results between Glow gwas (with and without offsets), Hail, and statsmodel. Hail gwas, for a single phenotype group , will intersect all non-null phenotypes, covariates, and genotypes and the results generated are concordant with statsmodel baselines when the same intersections are applied. Glow regressions do not match hail and statsmodel results outside of unit tests for the same input, despite sample masks being applied under the hood. Running glow gwas on real-world phenotype data with high missingness results in massive inflation/deflation of pvalues. But, performing this intersection upstream of calling glow gwas, results in concordance with Hail and statsmodel. One problem with applying this intersection in glow is that transformation on a glow genotype dataframe is not efficient. This prototype integrates a new "intersect_samples" flag and a parameter to pass in the genotype_sample_ids and performs this intersection in numpy within the existing mapPandas call, without having to do a more expensive spark dataframe transformation upstream.
How is this patch tested?
Inflation/deflation can also be observed in offset generation, though to a much lesser extent than is seen with gwas. Applying a similar approach for the initial steps of WGR is more complicated. I'll leave this as a draft for now in hopes there is a more elegant solution that can be applied to all steps of WGR, as well. I'm also building off of my hail enhancement branch: #377