Graph mining
Our mission is to build the most scalable library for graph algorithms and analysis and apply it to a multitude of Google products.

Our mission is to build the most scalable library for graph algorithms and analysis and apply it to a multitude of Google products.
About the team
We formalize data mining and machine learning challenges as graph problems and perform fundamental research in those fields leading to publications in top venues. Our algorithms and systems are used in a wide array of Google products such as Search, YouTube, AdWords, Play, Maps, and Social.
Team focus summaries
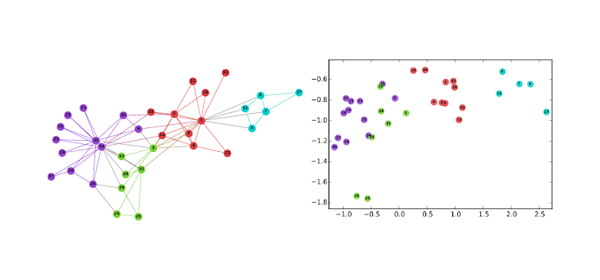
Our team specializes in clustering at Google scale, efficiently implementing many different algorithms including hierarchical agglomerative clustering, correlation clustering, k-means clustering, DBSCAN, and connected components. Our methods scale to graphs with trillions of edges using multiple machines and can efficiently handle graphs of tens of billions of edges on a single multicore machine. The clustering library powers over a hundred different use-cases across Google.
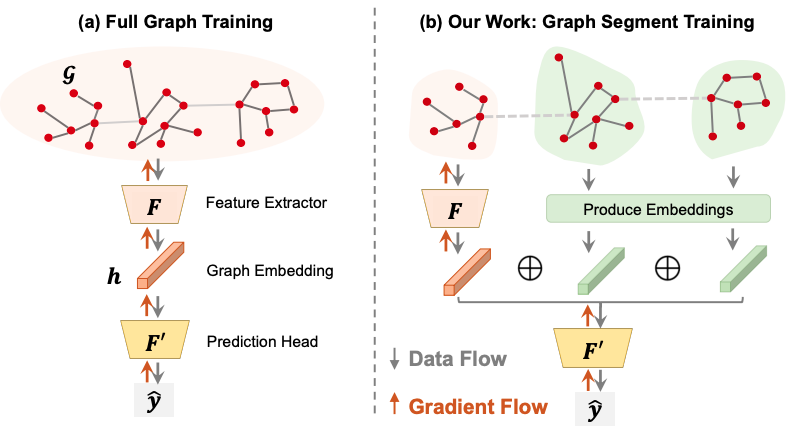
Our team specializes in large-scale learning on graph-structured data. We push the boundary on scalability, efficiency, and flexibility of our methods, informed by the complex heterogeneous systems abundant in our real-world industrial setting. In pursuit of scalability, we leverage both algorithmic improvements and novel hardware architectures. Our team develops and maintains TensorFlow-GNN, a library for training graph neural networks at Google scale.
Balanced Partitioning splits a large graph into roughly equal parts while minimizing cut size. The problem of “fairly” dividing a graph occurs in a number of contexts, such as assigning work in a distributed processing environment. Our techniques provided a 40% drop in multi-shard queries in Google Maps driving directions, saving a significant amount of CPU usage.
Our similarity ranking and centrality metrics serve as good features for understanding the characteristics of large graphs. They allow the development of link models useful for both link prediction and anomalous link discovery. Our tool Grale learns a similarity function that models the link relationships present in data.
Our research in pairwise similarity ranking has produced a number of innovative methods, which we have published at top conferences such as WWW, ICML, and VLDB. We maintain a library of similarity algorithms including distributed Personalized PageRank, Egonet similarity, and others.
Our research on novel models of graph computation addresses important issues of privacy in graph mining. Specifically, we present techniques to efficiently solve graph problems, including computing clustering, centrality scores and shortest path distances for each node, based on its personal view of the private data in the graph while preserving the privacy of each user.
We perform innovative research analyzing massive dynamic graphs. We have developed efficient algorithms for computing densest subgraph and triangle counting which operate even when subject to high velocity streaming updates.
Google’s most famous algorithm, PageRank, is a method for computing importance scores for vertices of a directed graph. In addition to PageRank, we have scalable implementations of several other centrality scores, such as harmonic centrality.
The GraphBuilder library can convert data from a metric space (such as document text) into a similarity graph. GraphBuilder scales to massive datasets by applying fast locality sensitive hashing and neighborhood search.
Distributed graph-based sampling has proved critical to various applications in active learning and data summarization, where the graph reveals signals about density and multi-hop connections. Combined with deep learning, we tackle provably hard problems and differentiable sampling helps GNN scalability too.
We design and implement graph-based optimization techniques to improve the performance of ML compilers (e.g., XLA). For example, we replaced heuristic-based cost models with graph neural networks (GNNs), achieving significant training and serving speed-ups (see our external TpuGraphs benchmarks and large-scale GNN). We have also deployed model partitioning algorithms that split ML computation graphs across TPUs for pipeline parallelism, as well as designed novel methods to certify that these partitions are near-optimal.
Featured publications
Highlighted work
-
 Google Research, 2022 & beyond: Algorithmic advancesThis post discusses progress made in several areas in 2022, including scalability, graph algorithms, privacy, market algorithms, and algorithmic foundations. Some of the important points are the development of new algorithms for handling huge datasets, achieving faster running times for graph algorithms including graph building and clustering, and privacy-preserving machine learning.
Google Research, 2022 & beyond: Algorithmic advancesThis post discusses progress made in several areas in 2022, including scalability, graph algorithms, privacy, market algorithms, and algorithmic foundations. Some of the important points are the development of new algorithms for handling huge datasets, achieving faster running times for graph algorithms including graph building and clustering, and privacy-preserving machine learning. -
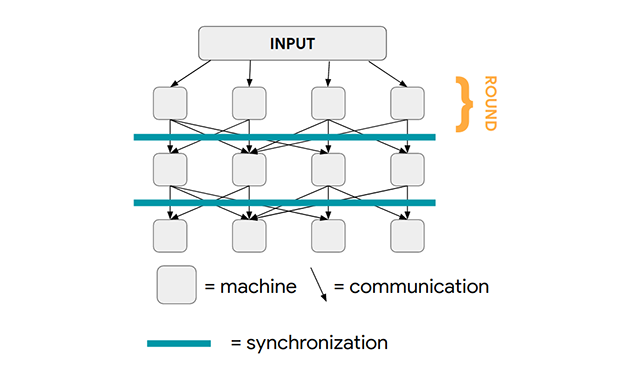
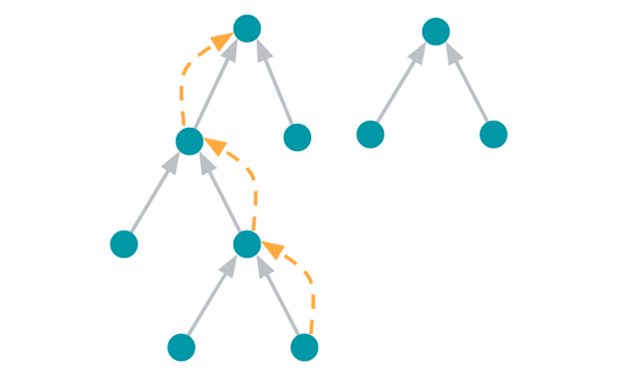
 Massively Parallel Graph Computation: From Theory to PracticeAdaptive Massively Parallel Computation (AMPC) augments the theoretical capabilities of MapReduce, providing a pathway to solve many graph problems in fewer computation rounds; the suite of algorithms, which includes algorithms for maximal independent set, maximum matching, connected components and minimum spanning tree, work up to 7x faster than current state-of-the-art approaches.
Massively Parallel Graph Computation: From Theory to PracticeAdaptive Massively Parallel Computation (AMPC) augments the theoretical capabilities of MapReduce, providing a pathway to solve many graph problems in fewer computation rounds; the suite of algorithms, which includes algorithms for maximal independent set, maximum matching, connected components and minimum spanning tree, work up to 7x faster than current state-of-the-art approaches. -
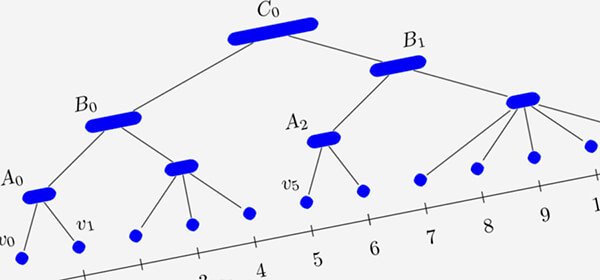
 Balanced Partitioning and Hierarchical Clustering at ScaleThis post presents the distributed algorithm we developed which is more applicable to large instances.
Balanced Partitioning and Hierarchical Clustering at ScaleThis post presents the distributed algorithm we developed which is more applicable to large instances. -
 Innovations in Graph Representation LearningWe share the results of two papers highlighting innovations in the area of graph representation learning: the first paper introduces a novel technique to learn multiple embeddings per node and the second addresses the fundamental problem of hyperparameter tuning in graph embeddings.
Innovations in Graph Representation LearningWe share the results of two papers highlighting innovations in the area of graph representation learning: the first paper introduces a novel technique to learn multiple embeddings per node and the second addresses the fundamental problem of hyperparameter tuning in graph embeddings. -
 Graph Mining & Learning @ NeurIPS 2020The Mining and Learning with Graphs at Scale workshop focused on methods for operating on massive information networks: graph-based learning and graph algorithms for a wide range of areas such as detecting fraud and abuse, query clustering and duplication detection, image and multi-modal data analysis, privacy-respecting data mining and recommendation, and experimental design under interference.
Graph Mining & Learning @ NeurIPS 2020The Mining and Learning with Graphs at Scale workshop focused on methods for operating on massive information networks: graph-based learning and graph algorithms for a wide range of areas such as detecting fraud and abuse, query clustering and duplication detection, image and multi-modal data analysis, privacy-respecting data mining and recommendation, and experimental design under interference. -
 Graph Neural Networks in TensorFlowGraph Neural Networks (GNNs) in TensorFlow (TF-GNN). The post discusses typical GNN architectures, why GNNs are useful and some GNN applications. Most importantly, it announces the release of TensorFlow GNN 1.0—Google's open-source GNN library for TensorFlow.
Graph Neural Networks in TensorFlowGraph Neural Networks (GNNs) in TensorFlow (TF-GNN). The post discusses typical GNN architectures, why GNNs are useful and some GNN applications. Most importantly, it announces the release of TensorFlow GNN 1.0—Google's open-source GNN library for TensorFlow. -
 Robust Graph Neural NetworksThis blog describes our framework for shift-robust Graph Neural Networks (SR-GNN) that can reduce the influence of biased training data on many GNN architectures. Increasing the robustness of GNN models helps to ensure accurate output in the face of changing data.
Robust Graph Neural NetworksThis blog describes our framework for shift-robust Graph Neural Networks (SR-GNN) that can reduce the influence of biased training data on many GNN architectures. Increasing the robustness of GNN models helps to ensure accurate output in the face of changing data. -
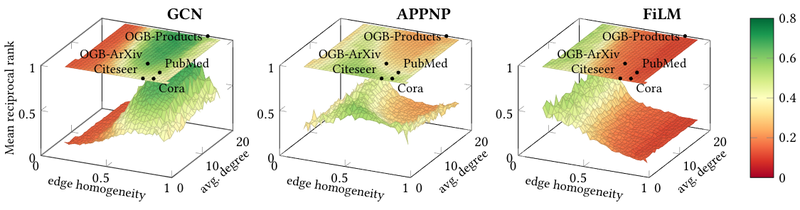
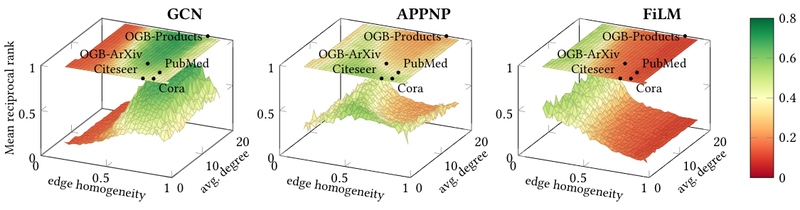 GraphWorld: Advances in Graph BenchmarkingThis blog post introduces GraphWorld, a system that generates synthetic graphs for benchmarking GNNs. GraphWorld allows researchers to explore GNN performance on a wider variety of graphs than was previously possible and identify weaknesses in current GNN Models.
GraphWorld: Advances in Graph BenchmarkingThis blog post introduces GraphWorld, a system that generates synthetic graphs for benchmarking GNNs. GraphWorld allows researchers to explore GNN performance on a wider variety of graphs than was previously possible and identify weaknesses in current GNN Models. -
 Teaching old labels new tricks in heterogeneous graphsComplex data struggles with limited labels for certain types, hurting HGNN performance. Our Knowledge Transfer Network (KTN) tackles this by finding connections between node types. KTN transfers knowledge from well-labeled nodes to those with few labels, allowing HGNNs to learn better representations for all data points.
Teaching old labels new tricks in heterogeneous graphsComplex data struggles with limited labels for certain types, hurting HGNN performance. Our Knowledge Transfer Network (KTN) tackles this by finding connections between node types. KTN transfers knowledge from well-labeled nodes to those with few labels, allowing HGNNs to learn better representations for all data points. -
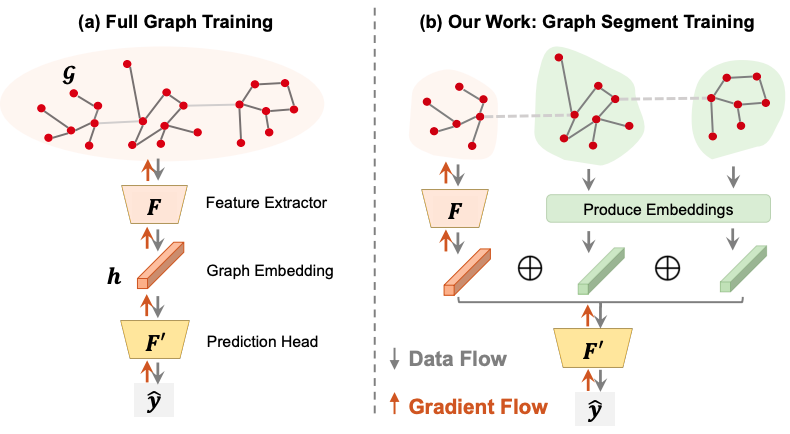 Advancements in machine learning for machine learningIn this blog post, we present exciting advancements in machine learning to improve machine learning (ML 4 ML)! In particular, we show how we use Graph Neural Networks to improve the efficiency of ML workloads by optimizing the choices made by the ML Compiler.
Advancements in machine learning for machine learningIn this blog post, we present exciting advancements in machine learning to improve machine learning (ML 4 ML)! In particular, we show how we use Graph Neural Networks to improve the efficiency of ML workloads by optimizing the choices made by the ML Compiler. -
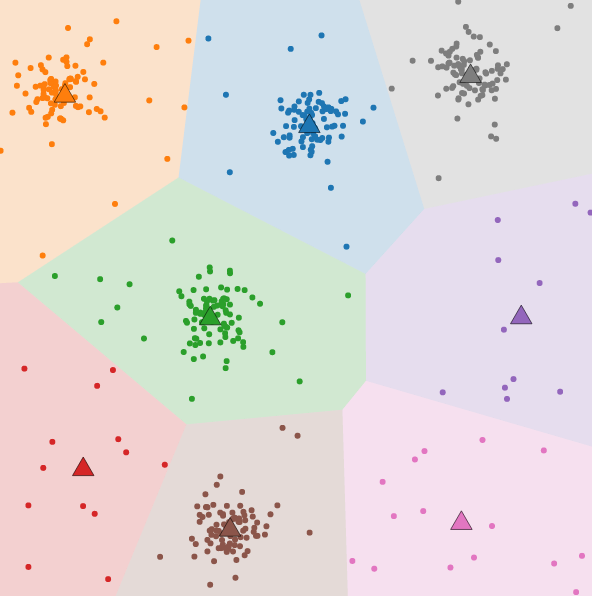 Differentially private clustering for large-scale datasetsThis blog highlights advancements in privacy-preserving clustering: 1) a novel ICML 2023 algorithm and 2) open-source scalable k-means code. We also discuss applying these techniques to inform public health via COVID Vaccine Insights.
Differentially private clustering for large-scale datasetsThis blog highlights advancements in privacy-preserving clustering: 1) a novel ICML 2023 algorithm and 2) open-source scalable k-means code. We also discuss applying these techniques to inform public health via COVID Vaccine Insights.

Some of our locations





Some of our people
-

Alessandro Epasto
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-

Allan Heydon
- Machine Intelligence
- Software Engineering
- Software Systems
-

Anton Tsitsulin
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-

Arjun Gopalan
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- Machine Intelligence
-

Bahare Fatemi
- Data Mining and Modeling
- Machine Perception
- Natural Language Processing
-

Brandon Asher Mayer
- Distributed Systems and Parallel Computing
- Machine Intelligence
- Machine Perception
-

Bryan Perozzi
- Data Mining and Modeling
- Machine Intelligence
-

CJ Carey
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

David Eisenstat
- Algorithms and Theory
-

Dustin Zelle
- Data Mining and Modeling
- Machine Intelligence
-

Goran Žužić
- Algorithms and Theory
- Distributed Systems and Parallel Computing
-
Hendrik Fichtenberger
- Algorithms and Theory
-

Jason Lee
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Johannes Gasteiger, né Klicpera
- Machine Intelligence
-

Jonathan Halcrow
- Algorithms and Theory
- Machine Intelligence
-

Kevin Aydin
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Jakub Łącki
- Algorithms and Theory
- Distributed Systems and Parallel Computing
-

Laxman Dhulipala
- Algorithms and Theory
- Distributed Systems and Parallel Computing
-
Lin Chen
- Algorithms and Theory
- Machine Intelligence
-

Matthew Fahrbach
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Mohammadhossein Bateni
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Nikos Parotsidis
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-
Peilin Zhong
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Rajesh Jayaram
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Sami Abu-El-Haija
- Algorithms and Theory
- Machine Perception
-

Sasan Tavakkol
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Machine Intelligence
-

Siddhartha Visveswara Jayanti
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Silvio Lattanzi
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-
Gang (Thomas) Fu
- Distributed Systems and Parallel Computing
- Machine Learning
-

Vahab S. Mirrokni
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- Algorithms and Theory
-

Vincent Pierre Cohen-addad
- Algorithms and Theory
- Machine Intelligence
