Impact-Driven Research, Innovation and Moonshots
Impact-Driven Research, Innovation and Moonshots (I-DRIM) is a global and multidisciplinary research team harnessing AI’s potential to advance science, drive product innovation, and address societal challenges, all with the aim to positively impact billions of lives.
Impact-Driven Research, Innovation and Moonshots (I-DRIM) is a global and multidisciplinary research team harnessing AI’s potential to advance science, drive product innovation, and address societal challenges, all with the aim to positively impact billions of lives.
About the team
Our teams focus on artificial intelligence (AI) and machine learning (ML) research to drive innovation and advance science. We aim to help communities and governments mitigate, adapt and build resilience to the increasing climate crisis through various climate & sustainability efforts. Our health initiatives help catalyze the adoption of human-centered AI to make healthcare more accurate, accessible, and affordable. Our teams are also pioneering the development of AI technologies with a focus on education, by personalizing the learning journey for students and streamlining tasks for educators
The development of AI is at a crucial juncture, and the progress we make now will profoundly shape our future. We believe that together we must commit to harnessing AI for good, leveraging its potential responsibly as we aim to address real-world problems to improve lives. We're proud to advance science and drive innovation, guided by our AI principles.
Team focus summaries
Leading foundational and applied research on the factuality of large language models to enable reliable LLMs for real world applications.
Making generative AI faster using advanced techniques such as Speculative Decoding.
Rethinking AI from its first principles by working on new model architectures and training schemes for LLMs, and image and video generation models.
Advancing research to catalyze the adoption of human-centered AI in healthcare with a focus on communities, consumers, and caregivers, and driven by the belief that care can be made more accurate, equitable, accessible and affordable.
Advancing AI research to help address climate mitigation (e.g., reducing impact of transportation on global warming) and climate adaptation (e.g., flood forecasting, wildfire predictions, food security).
Pioneering education-focused AI technologies aimed at enhancing both the students’ learning journey and the teachers’ experience.
Advancing efforts to develop knowledge and tools to inform the design and analysis of complex ecosystems.
Advance state of the art on foundational questions related to ML, natural language processing (NLP), and differential privacy.
Featured publications
Highlighted work
-
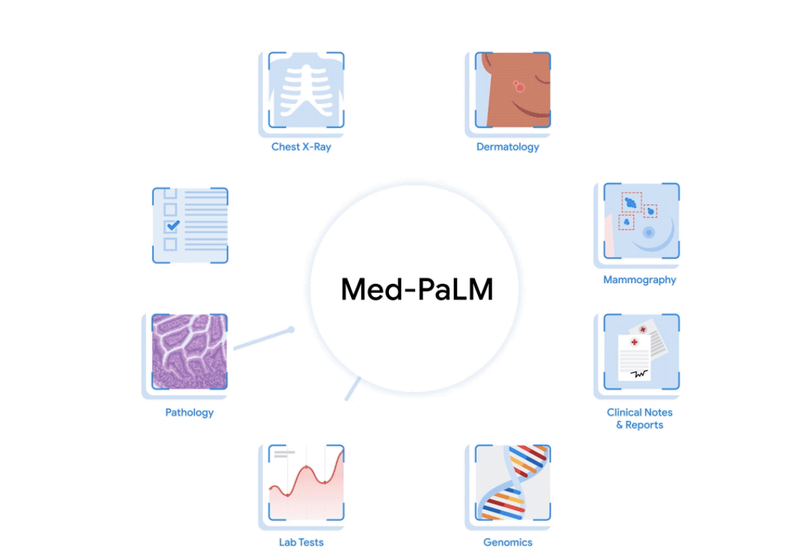
 Med-PaLMA large language model fine-tuned and designed to provide high quality answers to medical questions.
Med-PaLMA large language model fine-tuned and designed to provide high quality answers to medical questions. -
 Flood Forecasting initiativeUsing AI models to predict when floods will occur and help make critical flood forecasting information accessible to all.
Flood Forecasting initiativeUsing AI models to predict when floods will occur and help make critical flood forecasting information accessible to all. -
 Multimodal medical AIWe are exploring a spectrum of approaches to building multimodal medical LLMs, for example through Med-PaLM, our large language model (LLM) designed to provide high quality answers to medical questions.
Multimodal medical AIWe are exploring a spectrum of approaches to building multimodal medical LLMs, for example through Med-PaLM, our large language model (LLM) designed to provide high quality answers to medical questions. -
 Green LightOptimizing traffic lights to reduce vehicle emissions in cities, helping to mitigate climate change and improve urban mobility.
Green LightOptimizing traffic lights to reduce vehicle emissions in cities, helping to mitigate climate change and improve urban mobility. -
 Wildfire detection and predictionUsing AI to provide accurate wildfire information to affected communities and fire authorities
Wildfire detection and predictionUsing AI to provide accurate wildfire information to affected communities and fire authorities -
 6 ways Google is working with AI in AfricaResearch in Africa for Africa and the World: Using AI to help solve pressing problems affecting millions of people both locally and globally.
6 ways Google is working with AI in AfricaResearch in Africa for Africa and the World: Using AI to help solve pressing problems affecting millions of people both locally and globally. -
 Large language model factualityFoundational and applied research on factuality of large language models.
Large language model factualityFoundational and applied research on factuality of large language models. -
 LLM Efficiency for faster gen AI modelsUsing advanced techniques such as Speculative Decoding to accelerate existing off-the-shelf generative AI models without retraining or making architecture changes.
LLM Efficiency for faster gen AI modelsUsing advanced techniques such as Speculative Decoding to accelerate existing off-the-shelf generative AI models without retraining or making architecture changes.






Some of our locations












Some of our people
-

Yossi Matias
- Data Management
- Data Mining and Modeling
- Algorithms and Theory
-

Avinatan Hassidim
- Algorithms and Theory
- Economics and Electronic Commerce
- Machine Intelligence
-

Greg Corrado
- Distributed Systems and Parallel Computing
- Machine Intelligence
- Machine Perception
-

Andrei Z. Broder
- Information Retrieval and the Web
-

Dale Webster
- General Science
- Machine Intelligence
- Machine Perception
-

Yishay Mansour
- Algorithms and Theory
- Machine Intelligence
- Networking
-

Idan Szpektor
- Human-Computer Interaction and Visualization
- Machine Intelligence
- Natural Language Processing
-

Gal Yona
- Algorithms and Theory
- Natural Language Processing
- Responsible AI
-

Deborah Cohen
- Machine Intelligence
- Natural Language Processing
-

Christopher Semturs
- Human-Computer Interaction and Visualization
- Machine Intelligence
- General Science
-

Alan Karthikesalingam
- Machine Intelligence
- Machine Perception
- Health & Bioscience
-

Vivek Natarajan
- Education Innovation
- Machine Intelligence
- Algorithms and Theory
-

Gal Elidan
- Data Mining and Modeling
- Machine Intelligence
- Machine Perception
-

Roni Rabin
- Education Innovation
- Natural Language Processing
-

Amir Globerson
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Mor Geva
- Natural Language Processing
-

Ayelet Benjamini
- Natural Language Processing
- Health & Bioscience
- Climate and Sustainability
-

Haim Kaplan
- Algorithms and Theory
- Networking
- Security, Privacy and Abuse Prevention
-

Uri Stemmer
- Algorithms and Theory
- Machine Intelligence
- Security, Privacy and Abuse Prevention
-

Amit Daniely
- Algorithms and Theory
- Machine Intelligence
-
Oren Gilon
