

Abstract
One of the main challenges in autonomous robotic exploration and navigation in unknown and unstructured environments is determining where the robot can or cannot safely move. A significant source of difficulty in this determination arises from stochasticity and uncertainty, coming from localization error, sensor sparsity and noise, difficult-to-model robot-ground interactions, and disturbances to the motion of the vehicle. Classical approaches to this problem rely on geometric analysis of the surrounding terrain, which can be prone to modeling errors and can be computationally expensive. Moreover, modeling the distribution of uncertain traversability costs is a difficult task, compounded by the various error sources mentioned above. In this work, we take a principled learning approach to this problem. We introduce a neural network architecture for robustly learning the distribution of traversability costs. Because we are motivated by preserving the life of the robot, we tackle this learning problem from the perspective of learning tail-risks, i.e. the conditional value-at-risk (CVaR). We show that this approach reliably learns the expected tail risk given a desired probability risk threshold between 0 and 1, producing a traversability costmap which is more robust to outliers, more accurately captures tail risks, and is more computationally efficient, when compared against baselines. We validate our method on data collected by a legged robot navigating challenging, unstructured environments including an abandoned subway, limestone caves, and lava tube caves.
Index Terms—: Planning under Uncertainty, Deep Learning Methods, Field Robots, Motion and Path Planning, Robotics in Hazardous Fields
I. Introduction
Uncertainty is ever-present in robotic sensing and navigation. Localization error can severely degrade the quality of a robot’s environment map, leading to a robot over-estimating or under-estimating the safety of traversing some particular terrain [28]. Sensor noise, sparsity, and occlusion can similarly degrade localization and mapping performance, especially in perceptually degraded environments such as in dark, dusty, or featureless environments [25]. Moreover, the environment itself is a constant source of mobility uncertainty, as ground-vehicle interactions are notoriously difficult to model and even more difficult to accurately compute in real time - especially in unstructured environments such as those filled with slopes, rough terrain, low traction, rubble, narrow passages, and the like (Figure 1) [11]. In each case, modeling these uncertainties often relies on computationally tractable but distributionally restrictive assumptions; for example, assuming Gaussian distributions for localization error, or worst-case bounds on a settled pose [21].
Figure 1.

Left: Spot autonomously exploring Valentine Cave, Lava Beds National Monument, CA, USA. Right: LiDAR pointcloud and computed costmap in the same environment. In this work, we aim to infer a CVaR costmap from the LiDAR pointcloud.
We wish to more accurately quantify the uncertainty of computing traversability costs. This allows the robot to have some measure of control over the level of risk it is willing to take. This control can be used by task or mission-level planners which weigh a variety of factors to decide the best course of action [13].
Risk measures, often used in finance and operations research, provide a mapping from a random variable (usually the cost) to a real number. These risk metrics should satisfy certain axioms in order to be well-defined as well as to enable practical use in robotic applications [20]. Conditional value-at-risk (CVaR) is one such risk measure that has this desirable set of properties, and is a part of a class of risk metrics known as coherent risk measures [2].
Accurately constructing these risk measures poses a challenge, often relying on distributional assumptions such as Gaussianity [21]. In our previous work [7], we model traversability risks as Gaussian random variables and use them to efficiently construct risk measures which are useful for kinodynamic planning. While these approaches have the advantage of allowing for efficient, kinodynamic, risk-aware planning, they may suffer from relying too heavily on these modeling assumptions. Such assumptions include: 1) Localization error is accurately known (and is Gaussian), 2) various component risks can be accurately determined from a map (such as slope, step size, roughness, collision), and 3) these risks are normally distributed and both mean and variances can be accurately modeled.
Learning CVaR from data is an attractive approach to bypassing these complex issues. Since Koenker and Hallock [15] showed that minimizing a quantile loss function results in unbiased prediction of the VaR, or quantile function, many deep learning applications of this idea have been examined [14, 4]. However, there is little work on predicting CVaR directly. Instead, it is typically computed by sampling from the risk variable of interest [27], or relies on assumptions of the underlying distribution. More recently, Peng et al. [23] propose a method for predicting CVaR with a deep neural network under assumptions of i.i.d. samples, and prove convergence of the scheme. In this work, we propose an approach for distribution-free CVaR learning which scales to images and large datasets. We construct loss and evaluation functions for both VaR and CVaR which enforce monotonicity with respect to the risk probability.
Learning-based costmaps have seen more recent development for robotics and autonomous driving. The concept is attractive, possibly because it bypasses traditional modeling approaches, reduces computation, and improves performance from data. Recent work on CVaR based costmaps rely on assumptions of distribution (Gaussian) or sampling to estimate CVaR [3]. Hakobyan and Yang [9] learns an approximating CVaR costmap from precomputed CVaR values on a collision-avoidance task. Our contribution to this space is to propose learning CVaR directly in a distribution-free manner, with a novel application to navigation in challenging terrain.
We propose an architecture in which raw or minimally processed pointcloud data is transformed and fed into a convolutional neural network (CNN). In contrast to other approaches, the network directly produces a CVaR costmap which encodes the traversability risk, given a desired probability of confidence. Note that in this work we treat the risks in each cell in the costmap as static and independent of the others, that is, we do not consider the risk of traversing multiple cells sequentially. (See recent work [7, 20] which addresses the notion of dynamic risk metrics in the context of planning and assessing risk over a path). We restrict our approach to assessing point-wise risks which can then be used to commit the robot to finding a path which uses these risks as a constraint, avoiding the riskiest regions and thereby remaining safe. (In contrast, in [7] we minimize the CVaR of the risk along an entire path.)
Our contributions are summarized as follows:
A novel neural network architecture for transforming pointcloud data into risk-aware costmaps.
A loss function which trains this network to produce quantile and CVaR values without distribution assumptions.
A solution to a challenging traversability learning task in unknown environments, validated on a wide range of unstructured and difficult terrain.
Evaluation metrics which assess the goodness-of-fit of the network and comparison between different baseline approaches.
II. Method
In this section we establish definitions and describe our method for learning CVaR costmaps. We first formally define our notion of “traversability”. Then we discuss risk metrics, value-at-risk (VaR) and conditional value-at-risk (CVaR). We discuss the losses used to train a network to produce these values, and describe how we obtain training labels.
A. Traversability as a random variable
We define traversability as the capability for a ground vehicle to reside over a terrain region under an admissible state [22]. We represent traversability as scalar value r which indicates the magnitude of damage (or cost of repair) the robot will experience if placed in that state. We then wish to construct a model of this traversability given the robot’s state and knowledge:
| (1) |
where is the robot position in 2-D coordinates represents the current belief of the local environment, and is a traversability assessment model. This model captures various unfavorable events such as collision, getting stuck, tipping over, high slippage, to name a few. A mobility platform has a unique assessment model which reflects its mobility capability. In most real-world applications where perception capabilities are limited, the true value can be highly uncertain. To handle this uncertainty, consider a map belief, i.e., a probability distribution p(m|x0:k, z0:k) over a possible set , where z0:k are sensor observations. Then, the traversability estimate is a random variable . We call this probabilistic mapping from map belief and state to possible traversability cost values a risk assessment model.
B. Risk Metrics, VaR and CVaR
A risk metric is a mapping from a random variable to a real number which quantifies some notion of risk. Local environment information is encoded within m. This can be raw sensor data, e.g. observations, or processed map data (e.g. represented as m=(m(1),m(2), ⋯) where mi is the i-th element of the map). In the case of a 2-D or 2.5-D representation, i represents the cell index. Risk metrics can be coherent, which mean they satisfy six properties with respect to the random variables they act upon, namely: normalized, monotonic, sub-additive, positive homogeneity, and translation invariant. Majumdar and Pavone [20] argues that the consideration of risk in robotics should utilize coherent risk metrics for their intuitive and well-formulated properties. In this work we are concerned with right-tail risk only, since the random variable R is a positive “cost” for which we seek to avoid high values.
Let α ∈ [0,1] denote the risk probability level. High values of α imply more risk. The value-at-risk of the random variable R(m,x) can be defined by (we write R for brevity):
| (2) |
This is also known as the α-quantile. While there are multiple ways to define the conditional value-at-risk, one common definition is as follows:
| (3) |
C. Learning VaR and CVaR
We wish to construct a model with inputs m, x, and α, and outputs CVaRα(R(m, x)), parameterized by network weights θ. We denote this model as Cθ(m, x, α). To learn CVaR we take a joint approach where we learn both VaR and CVaR together. We construct a similar VaR model, also as a function of m and x as VaRα(R(m, x)), which we denote Vθ(m, x, α). Learning VaR can be accomplished by minimizing the Koenker-Bassett error with respect to θ [15]:
| (4) |
where (·)+ = max(·, 0) and (·)− = min(·, 0). From the estimated VaR, we can compute the expected CVaR and construct an L1-loss for Cθ:
| (5) |
With the assumption of i.i.d. sampled data, when and are minimized, Vθ will approximate VaR and Cθ will approximate CVaR. If during training we uniformly randomly sample values of α ∈ [0,1], then the input α to these models should be meaningful as well.
In practice, a few modifications to these losses are needed to improve numerical stability. First, similar to [4], we smooth the quantile loss function near the inflection point Vθ=R by using a modified Huber loss [10]:
| (6) |
where controls how much smoothing is added (Figure 3). The new VaR loss is then:
| (7) |
Figure 3.

Modified quantile Huber loss lh(e,α), for varying values of α and h.
Second, instead of learning Cθ directly, we can learn the residual between Cθ and Vθ. Suppose we construct a model instead of Cθ, and let . Then the loss can be written as:
| (8) |
This serves to separate the error signals between the two models.
Third, we introduce a monotonic loss to enforce that increasing values of α result in increasing values of Vθ(m,x,α) and Cθ(m,x,α). This can be done by penalizing negative divergence of the output with respect to α [6]. We also introduce a smoothing function to prevent instability near the inflection point when the divergence equals 0. The total monotonic loss is:
| (9) |
| (10) |
| (11) |
| (12) |
In practice we find that under gradient-based optimization, this loss decreases to near 0 in the first epoch and does not notice-ably affect the minimization of the quantile and CVaR losses.
To summarize, the total loss function is the sum of the modified Huber quantile loss (7), the L1 residual CVaR loss (8), and the monotonic loss (12):
| (13) |
We minimize this loss over a dataset, sampled i.i.d from the distribution of R, which is a function of m and x. We also sample from a uniform distribution for α. In other words, we seek to minimize the expected loss with respect to θ:
| (14) |
This expectation is approximated using stochastic gradient descent [26]. Given the dataset , the distribution p(m, x) is sampled from the distribution of data collected by the robot as it moves in the environment, observing samples of its position x and its environment data m. The distribution p(R|m,x) is sampled by determining the traversability cost given a sampled (m,x). This determination may be stochastic or imprecise, and may possibly come from any traversability assessment method. Happily, our learning approach should capture this stochasticity. In Figure 4, we demonstrate this learning approach on a toy 1-D problem. We use a 3 layer feed-forward MLP neural network to learn the state-varying VaR and CVaR values of a random variable. We notice that our learning approach captures the risk of the known distributions accurately. Next, we describe the application of this loss function to learning unknown distributions of 2-D traversability costs from 3D pointclouds.
Figure 4.

Learned VaR and CVaR on a toy 1-D problem. Top: Samples drawn from a distribution y ~ f(x) which is multimodal and heteroskedastic. Solid and dotted lines show learned VaR and CVaR levels, respectively, for different values of α. Bottom: PDF of the true distribution for varying values of x. Also marked are the learned VaR (solid vertical line) and CVaR (dotted vertical line) values, when α=0.9.
D. Obtaining Ground Truth Labels
As mentioned, computing traversability costs from sensor data is a rich field in itself. Computing these costs may include geometric analysis [8], semantic understanding and detection [17], proprioceptive sensing [18], or hand-labeling. Our approach is extensible to both dense and sparse ground truth labels in the costmap. In this work we focus on costs arising through geometric analysis. We leverage prior work (Fan et al. [7]), which itself follows a tradition of geometric analyses for ground vehicle traversal [21, 8]. These analyses are based on pointcloud data and provide model-based costs which are computed in a dense local region around the robot, but are affected by sensor occlusion, sparsity, noise, and localization error. These sources of ambiguity and stochasticity are exactly what we aim to capture with our risk-aware model. However, instead of having to explicitly model these uncertainties, we simple compute a mean value best-guess at the traversability cost, and use learning to aggregate the variation of these costs.
III. Implementation Details
In this section, we discuss details of the dataset, data processing, network architecture, and training procedures.
A. Dataset
Our motivation for tackling this problem comes from extensive field testing in various underground caves and decaying urban environments [1]. We collected data from autonomous exploration runs in six different environments of various types (Figure 5, Table I). These environments are as follows:
An abandoned subway station in Los Angeles, CA, the first floor has a large open atrium with pillars (Subway Atrium / SA).
The basement floor of the same subway station, featuring offices and narrow corridors (Subway Office / SO).
Kentucky Underground Storage in Lexington, KY, which consists of very large cavernous grids of tunnels (Limestone Mine / LM)
Wells Cave in Pulaski County, KY, which is a natural limestone cave with very rough floors, narrow passages, low ceilings, and rubble (Limestone Cave / LC)
Valentine Cave at Lava Beds National Park, CA, which is an naturally formed ancient lava tube, with sloping walls and rough, rocky floors (Lava Tube A / TA)
Mammoth Cave at Lava Beds National Park, CA, which is also a lava tube but with sandy, sloping floors and occasional large piles of rubble (Lava Tube B / TB).
Figure 5.

Datasets collected in 6 different environments. Top row: Photo of the environment. Second row: LiDAR pointcloud and elevation map produced after ground segmentation. Third row: Handcrafted risk map with varying risk (white: safe (r<=0.1), yellow to red: moderate (0.1<r<=0.9), black: risky (r>0.9)). Pointclouds are also shown. Bottom row: Map of the entire environment, generated by aggregating LiDAR pointclouds during each data collection run. Scale (in meters) is shown in the lower right corner.
Table I.
Details of datasets, with number of data samples, duration of the runs, approximate distance traveled, and average width of the passages in the environment.
| SA | SO | LM | LC | TA | TB | |
|---|---|---|---|---|---|---|
| # Samples | 1585 | 2883 | 942 | 331 | 852 | 1148 |
| Duration (min) | 53 | 96 | 31 | 11 | 28 | 38 |
| Distance (m) | 1000 | 1000 | 600 | 300 | 600 | 800 |
| Min Width (m) | 5 | 1 | 10 | 0.5 | 1 | 3 |
| Max Width (m) | 50 | 10 | 20 | 5 | 10 | 10 |
Data was collected using Boston Dynamics’s Spot legged robot equipped with JPL’s NeBula payload [1]. The payload includes onboard computing, one VLP-16 Velodyne LiDAR sensor, and a range of other cameras and sensors. Spot is equipped with 5 Intel RealSense depth cameras which are pointed at the ground. A new data sample was added to the dataset at approximately 0.5Hz, while the average top speed of the robot was set to 1m/s.
B. Computing Traversability Cost
Traversability costs are computed online and saved along with dataset. These costs are generated via a risk-aware traversability pipeline [7], which we will briefly summarize here. First, we aggregate LiDAR pointclouds over time, using odometry. Odometry is generated using a combination of Spot’s on-board VIO and ICP-based pointcloud matching. Next, we perform ground segmentation to isolate “ground” points, “obstacle” points, and “ceiling” points. We then perform elevation mapping, which probabilistically builds a 2.5-D elevation map using the “ground” points. Localization noise and delay are taken into account here, resulting in elevation variance information as well. We then compute costs as a function of various geometric information arising from the elevation map and the pointcloud, such as slope, step size, roughness, negative obstacles, and collision obstacles. These costs are then aggregated into a combined mean cost (as well as a cost variance). The traversability cost is scaled between 0 and 1, with 1 being lethal and 0 being safe. In [7], the mean cost and variance of the cost are then used to compute CVaR, with assumption of a Gaussian distribution. In this work, however, we only use the mean cost which represents R. We aim to directly predict CVaR from the distribution of costs that arise through this analysis and the environment itself.
C. Transforming Pointclouds to Costmaps
We aim to construct a network whose inputs are the LiDAR pointcloud, and whose output is a CVaR costmap (2-D). There are many different approaches for processing LiDAR data using neural networks, but engineering a custom pointcloud-to-image neural network architecture is beyond the scope of this work. For simplicity, we restrict ourselves to using an image-to-image autoencoder type of network (namely, U-Net with partial convolutions [19]), leaving the difficult task of transforming a LiDAR pointcloud to images for future work. To adapt our pipeline for this approach, we bin pointcloud data into 5 height bins relative to the computed elevation map. We count the number of points which fall into these bins and generate an image from these counts. We end up with input features where each feature channel is a 2-D image (see Figure 6). Image sizes are 400×400 pixels, with each pixel representing 0.1m, for a total area of 40m × 40m covered.
Figure 6.

Input features converted from LiDAR pointclouds, showing different features in columns from left to right, while each row corresponds to one sample from each of the 6 datasets. Features are, from left to right: 1) elevation, 2) number of LiDAR points, 3) obstacle points (older points have a lower intensity), 4–8) number of points in each of 5 z-height bins, relative to the elevation map, with a bin height of 0.1m, 9) distance from the robot location, 10) “known” region mask, which marks regions which have sensor coverage.
The presence of gaps and occlusions in LiDAR data lead to known and unknown regions in the image-translated input data. These unknown regions need to be handled by the network. A naive approach would be to use zero-padding, i.e. replacing unknown pixels with 0. However, this can lead to blurring and other spurious artifacts at the edges. For this reason, the use of partial convolutional neural networks lends itself particularly well to this image-to-image learning task with unstructured, unknown masks [19].
Additionally, we provide the desired α level as an image to the input of the network. Since α is an image it can vary spatially. The loss function takes this desired α into account per-pixel, and trains the network to produce the correct risk level according to the desired input pattern. During training, we use a uniformly distributed smoothed random pattern, whose distribution spans α ∈ [0,1].
Figure 8 outlines the costmap network architecture used in our approach. The pipeline consists of three components: 1) Pointcloud-to-image features transform, 2) an image-to-costmap translation network using a PartialConv U-Net, and 3) VaR (Vθ(m,x,α)) and CVaR outputs, which are fed into the loss function (Equation 13). The loss is averaged pixel-wise across the known mask regions only. This implies that each α value is independent from its neighbors.
Figure 8.

Our pointcloud-to-costmap pipeline. From left to right: Raw pointclouds are aggregated and used to create 2-D image-like input features and the mask. A 2-D α channel also provides input to the network. The PartialConv U-Net architecture maps these input features to 2 output channels, namely VaR and CVaR−VaR. These two outputs are combined with the handcrafted cost labels to compute the loss.
During both training and inference time, we expect to use only a certain distribution of patterns of α. A smoothly varying α pattern may emphasize correlations between neighboring pixels, while a completely random α image might encourage less correlations (See Figure 7).
Figure 7.

Some examples of α input channel images. Left: Randomly generated Gaussian filter, renormalized to have a uniform distribution. Middle: Randomly generated Voronoi-regions, with uniformly distributed α values. Right: A radially decaying α input, α=1 within 5 meters of the robot, and decays linearly down to 0 at 20m from the robot.
Figure 9 shows corresponding outputs for the inputs shown in Figure 6. The leftmost column shows the ground truth traversability cost, while the next 3 columns show CVaR at varying α levels (α = 0.1,0.5,0.9). Note that CVaR steadily increases as α increases, and generally is a greater value than the traversability cost. The next three columns show CVaR at the same varying alpha levels, minus the VaR output of the network when α = 0.1. This provides more insight into the changes in VaR and CVaR as α is increased. The final column shows the same CVaR − VaR0.1 except with a varying α input, in a radially decaying pattern, with high α = 1 in the center, and low α=0 at the edges. This kind of pattern could be useful for a risk-aware system which wishes to be more conservative when planning motions in the regions near the robot. Such a behavior could be useful when the user believes he can rely more on data closer to the robot with greater sensor coverage, as well as wishing to allow for a relaxed commitment to avoiding traversability risks further away.
Figure 9.

Network outputs on the same input examples shown in Figure 6. Columns from left to right: 1) Handcrafted cost label, 2–4) CVaR values with α=0.1,0.5,0.9 respectively, 5–7) CVaRα−VaR0.1 for varying α=0.1,0.5,0.9 respectively. This enables us to more clearly see the differences between values of α. It also shows the difference between CVaR and VaR. 8) CVaRα−VaR0.1 when α is radially decaying, with α=1 at the center and decaying to α=0 at the edges. Notice that the output risk also decays radially from the center of the map.
D. Training
Next we describe some details of training and hyperparameters. We used weights for the CVaR loss (13) of λV = 10.0, λC = 1.0 λm = 1.0e−4. We used a Huber smoothing coefficient of h=1.0e−3. The network was trained on a 90 : 5 : 5 split of training, validation, and test data. We used Adam optimization with an initial learning rate of 0.0005, and batch size of 1. No pre-training of the network was used, weights were initialized with Xavier random weights. During training, data augmentation was used - including rotation, translation, scaling, shearing, and flipping. Training took about 16 hours on a 12GB NVIDIA Tesla K80 GPU.
IV. Evaluation and Results
In this section, we evaluate the method on data which is both in-distribution and out-of-distribution, compare against different baselines, and investigate the behavior of the network. We first present some qualitative observations about the performance of the model. Figure 10 shows an interesting case where the traversability cost of an obstacle is difficult to determine. In this case (taken from the Limestone Cave dataset), a row of cinderblocks (0.15–0.2m in height) blocks Spot’s path. Spot is usually capable of traversing such obstacles but they do pose some risk. (In this particular instance, the robot tripped over and fell down.) We observe the network has learned the concept of the variation of this risk as α is increased from 0.1 to 0.9. While the handcrafted traversability cost shows a risky region on the wall for this sample, other samples or other similar situations have shown less traversability cost, so the network has learned to smoothly interpolate along this distribution. Note that this change is more than simple scaling up all costs in the output, as can be seen from the plots of CVaRα − VaR0.1. As α increases, we see a much stronger increase in CVaR at the location of the low wall relative to the rest of the costmap.
Figure 10.

Case study for a low wall obstacle. Top left: On-board camera image of the obstacle. Top middle: pointcloud and elevation map. Spot has placed one foot on top of the wall. Top right: Handcrafted traversability cost. The wall appears in the center of the map in a line. Middle row: CVaR at varying levels of α = 0.1, 0.3, 0.5, 0.7, 0.9 respectively. Bottom row: CVaRα−VaR0.1 at varying levels of alpha. The risk of the wall increases greatly as α is increased, while other regions increase in risk more gradually. Color scale of all maps range from 0 to 1.
We also observe the network learns to remove spurious noise and artifacts from the costmap (Figure 11). These artifacts occur sporadically, which means they lie far out in the tail of the risk distribution. In this example (from Lava Tube A), several artifacts are visible in the handcrafted costmap, arising from localization noise and sparse sensor coverage. The worst offending artifact entirely blocks a passageway - this is caused by localization noise which creates artifacts in the elevation map. The network produces a clean risk map which ignores these artifacts.
Figure 11.
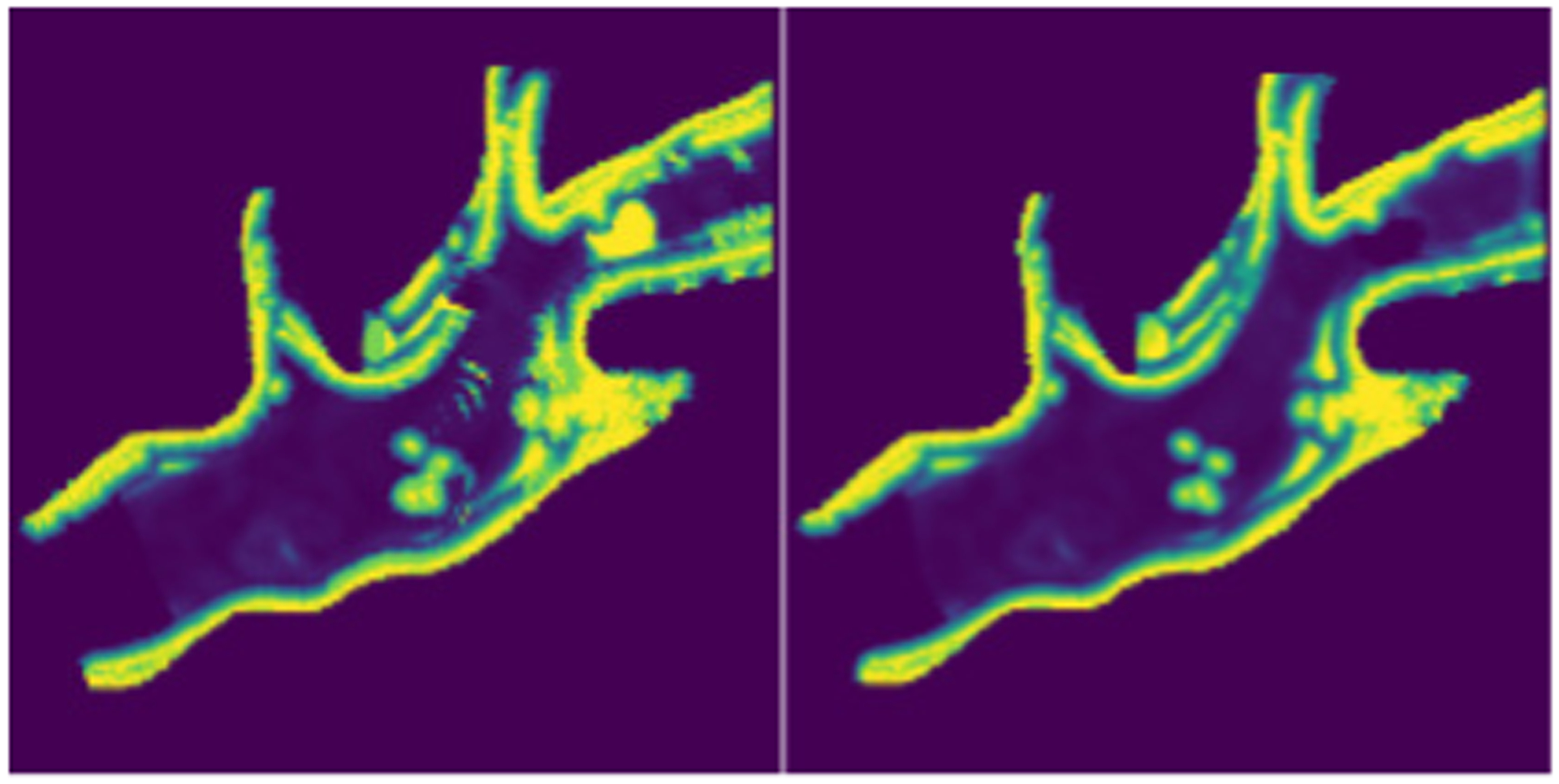
Case study of localization artifact removal. Left: Handcrafted traversability cost. Right: CVaR network output when α = 0.5. We observe that artifacts arising from localization error and sensor sparsity are not present in the predicted risk map. In this particular case, this has significant impact on path planning through the narrow passage.
A. Evaluation Metrics
We introduce three evaluation metrics for assessing the quality of VaR and CVaR learning for a given value of α. First, we compute the implied-α (Iα) value, which is a measure of how closely the predicted VaR value matches the true quantile:
| (15) |
An accurate model should have a value of Iα ≈ α. Note that we sum over all valid (non-masked) pixels and data samples. The denominator counts the number of non-masked pixels.
The R2 coefficient of determination metric is useful for comparing the explanatory power of a model relative to the distribution of the data. To quantify the modeling capacity of the network when compared to other baselines, we use a pseudo-R2, which is a function of α. For assessing pseudo-R2 for VaR, we use the following metric [16]:
| (16) |
where is the constant α-quantile computed from the training data. This metric compares the Koenker-Bassett error of a quantile regression model against the total absolute deviation of the data from an independent α quantile. A value of 1 is the best, reflecting total explanation of the dependent variable, while a value less than 0 is poor, implying worse explanatory power than the simple quantile.
Finally, to assess the CVaR modeling, we construct a similar pseudo-R2 metric for CVaR. Instead of the Koenker-Bassett error, we use the empirical CVaR error (see [24] for a rigorous discussion of a similar but computationally less tractable approach). Our CVaR pseudo-R2 metric compares the total absolute error between our CVaR model and an average empirical CVaR computed from the training data:
| (17) |
where is the constant α-CVaR computed from the training data.
B. In-distribution (ID) Performance
We begin by evaluating the in-distribution (ID) performance of the network. Figure 12 shows a boxplot of the three evaluation metrics described above, testing on the held-out test data, for a network trained on all 6 datasets. The box plots show the distribution of metrics computed per-sample. Implied α holds up well, forming tracking α, while VaR R2 and CVaR R2 are close to 1 for most values of α. As α nears 0.9 and 0.95, the CVaR R2 drops closer to 0, implying less of the data is being accurately explained by the model. This is likely due to the distribution of traversability costs lying between 0 and 1. When α is high, both VaR and CVaR are more frequently predicted to be 1. This results in a lower CVaR R2 since the denominator will be small.
Figure 12.
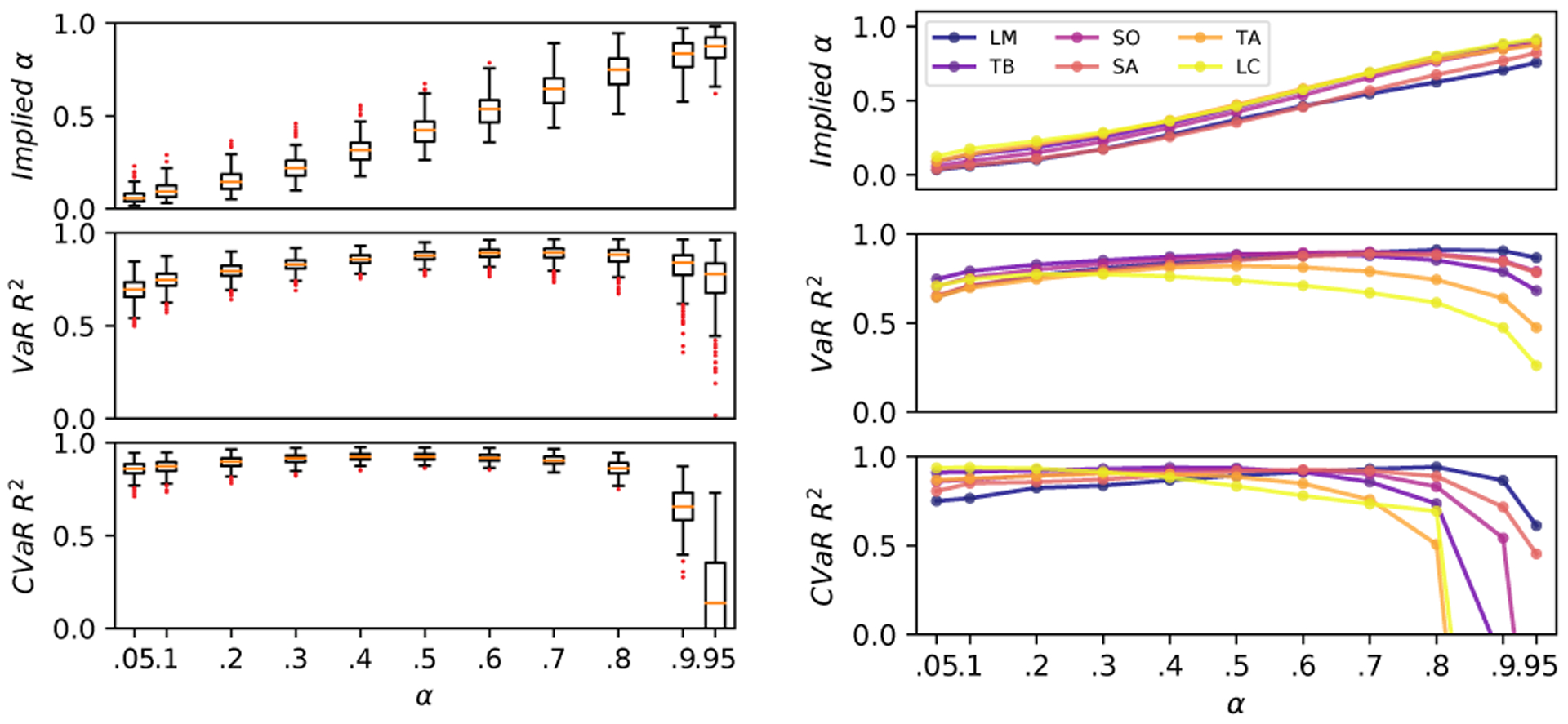
ID performance: (Left) Boxplot of evaluation metrics for model trained on all 6 datasets, evaluated on held-out test data from all 6 datasets. The evaluation metrics are computed on each sample individually, and aggregated to make a box plot. (Right) Evaluation metrics for model trained on all 6 datasets, evaluated on held-out test data from 6 datasets individually.
We also plot evaluation metrics on each of the 6 dataset categories individually (Figure 12). This allows us to evaluate the differences between each dataset. We note that the Limstone Cave dataset has the highest levels of risk, which results in more frequent distortion of the CVaR R2 metric for high α levels. Nevertheless, all datasets perform well, with pseudo-R2 values close to 1.0.
C. Out-of-Distribution (OOD) Performance
To evaluate out-of-distribution (OOD) performance, we train the network on all data except the one dataset, and then evaluate the network on the OOD dataset (which the network has not seen during training). We do this by holding out the Limestone Cave dataset (Figure 13). The Limestone Cave dataset has the most different and challenging terrain with the highest average risks, and with many features not present in the other datasets, such as sharp jagged rocks, narrow passages, channels of water, and rough floors. We see that OOD performance on this dissimilar dataset desires improvement, in contrast to OOD performance on other more similar datasets (not shown). However, the Limestone Cave OOD model is still able to maintain healthy pseudo-R2 statistics (>0) for a large range of α.
Figure 13.
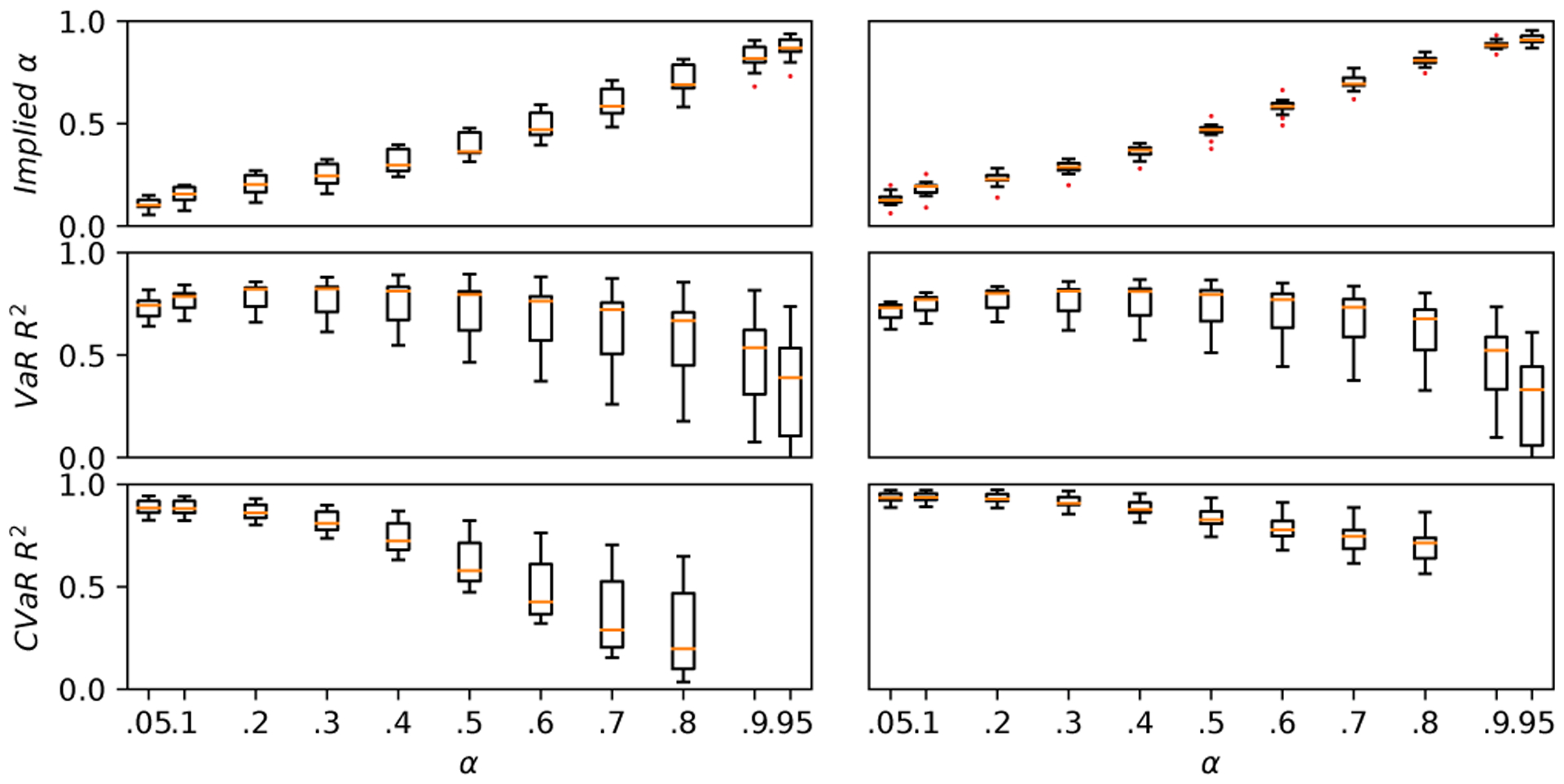
OOD performance: (Left) Boxplot of evaluation metrics for model trained on all datasets except the Limestone Cave, evaluated on held-out data from the Limestone Cave. Performance is worse than the ID performance, i.e. when the model is trained on all data, and evaluated on the Limestone Cave data (Right).
D. Comparisons against baselines
Finally, we compare our approach against three baselines: 1) the handcrafted traversability risk model which relies on assumptions of Gaussianity and accurate mean and variance, described in Section III-B, 2) a model trained to predict the traversability cost using an L1 loss function only, and 3) a model trained to predict both traversability mean and variance using a Gaussian negative log likelihood (NLL) loss [12], which is then used to compute VaR and CVaR assuming a Gaussian distribution. We computed metrics by taking the average over all test datasets, shown in Figure 14. The L1 Loss model does not capture any quantile information and does not depend on α. Therefore, it does not capture the VaR or CVaR as well as the trained model. The hand-crafted traversability cost model also does not perform well - it fails to accurately capture the quantile (VaR) for most values of α. It also does not provide as accurate CVaR values as the learned model. The NLL loss model fairs relatively well predicting CVaR, but less-so for VaR. However, the learned CVaR model still outperforms it in the CVaR statistic.
Figure 14.
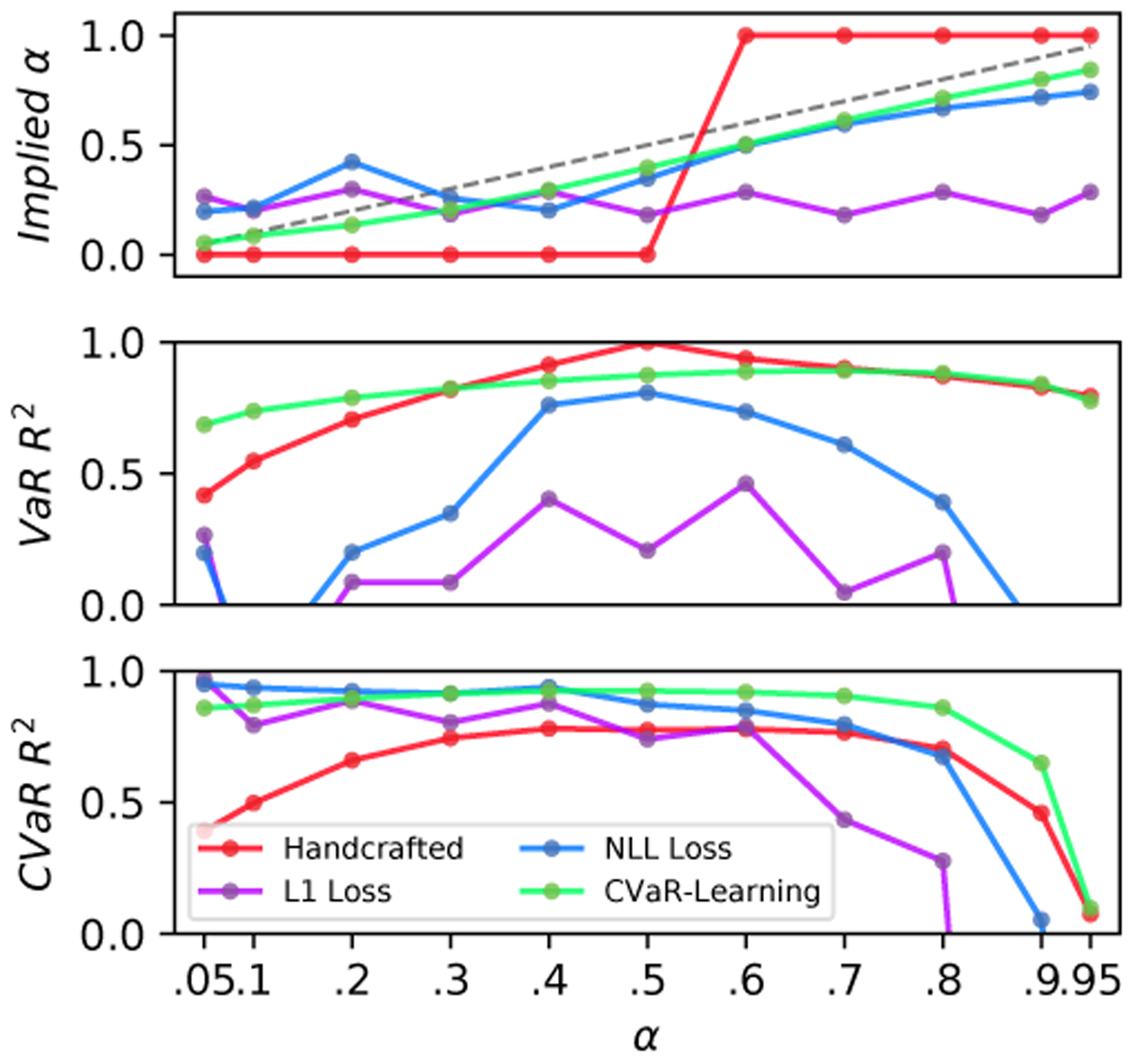
Comparing CVaR-learning model against handcrafted CVaR cost model, L1-loss model, and NLL-loss model. The learned model was trained on all 6 datasets. Shown here are evaluation metrics computed over the held-out test data for all 6 datasets. The CVaR-learning method outperforms by a clear margin. Dotted line in first plot indicates ideal implied α values.
We also consider the computation time of using the handcrafted traversability cost method vs. our CVaR learning method (Table II). The CVaR learning approach tends to be almost 5x more efficient then the handcrafted approach. (Both methods currently rely on ground segmentation and elevation mapping steps.) We see that replacing the handcrafted costmap with the learned one removes the largest bottleneck in the traversability assessment pipeline.
Table II.
Computation time for handcrafted costmap vs. CVaR-learning costmap, computed from N=250 samples. Also shown are times for preprocessing steps, i.e. ground segmentation and creating the 2.5-D elevation map.
| Computation Time | μ (ms) | σ (ms) |
|---|---|---|
| Ground Segmentation | 13.97 | 3.88 |
| Elevation Mapping | 140.19 | 65.48 |
| Handcrafted Costmap | 241.92 | 30.11 |
| CVaR-Learning Costmap | 48.94 | 15.36 |
V. Conclusion
In this work, we introduced a novel neural network architecture for transforming pointcloud data into risk-aware costmaps. We also introduced a novel formulation of CVaR and VaR loss functions which train the network to accurately capture tail risk, without relying on cumbersome modeling or distribution assumptions. We demonstrated this approach on a robotic navigation task in unstructured and challenging terrain. We evaluated the method using metrics which show that this approach reliably learns the expected tail risk given a desired probability risk threshold between 0 and 1 and produces a traversability costmap which is robust to outliers, accurately captures tail risks, generalizes well to out-of-distribution data, and is more computationally efficient. Future work includes investigation of architectures which directly map LiDAR points to costs, investigating the use of importance sampling to improve risk estimates for high values of α [5], and investigation of learning dynamic risk metrics [20].
Figure 2.

Comparison of the mean, VaR, and CVaR for a given risk level α ∈ (0,1]. The axes denote the values of the stochastic variable R, which in our work represents traversability cost. The shaded area denotes the (1−α)% of the area under p(R). CVaRα(R) is the expected value of R under the shaded area. (From [7]).
VI. Acknowledgement
We thank Keuntaek Lee, Kyohei Otsu, Anushri Dixit, and Nicholas Palermo for useful discussions and contributions to the code base.
This work was supported by the JPL Year Round Internship Program and the National Aeronautics and Space Administration (NASA).
References
- [1].Agha A, Otsu K, Morrell B, Fan DD, Thakker R, Santamaria-Navarro A, Kim S-K, Bouman A, Lei X, Edlund J, et al. Nebula: Quest for robotic autonomy in challenging environments; Team CoSTAR at the DARPA Subterranean Challenge. arXiv preprint arXiv:2103.11470, 2021. [Google Scholar]
- [2].Artzner P, Delbaen F, Eber J, and Heath D. Coherent measures of risk. Mathematical Finance, 9(3):203–228, 1999. [Google Scholar]
- [3].Choudhry A, Moon B, Patrikar J, Samaras C, and Scherer S. CVaR-based Flight Energy Risk Assessment for Multirotor UAVs using a Deep Energy Model. arXiv preprint arXiv:2105.15189, 2021. [Google Scholar]
- [4].Dabney W, Rowland M, Bellemare MG, and Munos R. Distributional reinforcement learning with quantile regression. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018. [Google Scholar]
- [5].Deo A and Murthy K. Optimizing tail risks using an importance sampling based extrapolation for heavy-tailed objectives. In 2020 59th IEEE Conference on Decision and Control (CDC), pages 1070–1077. IEEE, 2020. [Google Scholar]
- [6].Fan DD, Agha-mohammad A.-a., and Theodorou EA. Deep learning tubes for tube MPC. arXiv preprint arXiv:2002.01587, 2020. [Google Scholar]
- [7].Fan DD, Otsu K, Kubo Y, Dixit A, Burdick J, and Agha-Mohammadi A-A. STEP: Stochastic traversability evaluation and planning for safe off-road navigation. Robotics: Science and Systems (RSS), 2021. [Google Scholar]
- [8].Goldberg SB, Maimone MW, and Matthies L. Stereo vision and rover navigation software for planetary exploration. In IEEE Aerospace Conference. IEEE, 2002. [Google Scholar]
- [9].Hakobyan A and Yang I. Distributionally robust risk map for learning-based motion planning and control: A semidefinite programming approach. arXiv preprint arXiv:2105.00657, 2021. [Google Scholar]
- [10].Huber PJ. Robust estimation of a location parameter. In Breakthroughs in Statistics, pages 492–518. Springer, 1992. [Google Scholar]
- [11].Kalita H, Morad S, Ravindran A, and Thangavelautham J. Path planning and navigation inside off-world lava tubes and caves. In IEEE/ION Position, Location and Navigation Symposium, pages 1311–1318, 2018. [Google Scholar]
- [12].Kendall A and Gal Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?, 2017. ISSN; 16653521. [Google Scholar]
- [13].Kim S-K, Bouman A, Salhotra G, Fan DD, Otsu K, Burdick J, and Agha-mohammadi A.-a.. PLGRIM: Hierarchical value learning for large-scale exploration in unknown environments. In Proceedings of the International Conference on Automated Planning and Scheduling, volume 31, pages 652–662, 2021. [Google Scholar]
- [14].Kivaranovic D, Johnson KD, and Leeb H. Adaptive, distribution-free prediction intervals for deep networks. In International Conference on Artificial Intelligence and Statistics, pages 4346–4356. PMLR, 2020. [Google Scholar]
- [15].Koenker R and Hallock KF. Quantile regression. Journal of Economic Perspectives, 15(4):143–156, 2001. [Google Scholar]
- [16].Koenker R and Machado JA. Goodness of fit and related inference processes for quantile regression. Journal of the American Statistical Association, 94(448):1296–1310, 1999. [Google Scholar]
- [17].Kostavelis I and Gasteratos A. Semantic mapping for mobile robotics tasks: A survey. Robotics and Autonomous Systems, 66:86–103, 2015. [Google Scholar]
- [18].Lew T, Emmei T, Fan DD, Bartlett T, Santamaria-Navarro A, Thakker R, and Agha-mohammadi A.-a.. Contact inertial odometry: Collisions are your friends. arXiv preprint arXiv:1909.00079, 2019. [Google Scholar]
- [19].Liu G, Reda FA, Shih KJ, Wang T-C, Tao A, and Catanzaro B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), pages 85–100, 2018. [Google Scholar]
- [20].Majumdar A and Pavone M. How should a robot assess risk? towards an axiomatic theory of risk in robotics. In Robotics Research, pages 75–84. Springer, 2020. [Google Scholar]
- [21].Otsu K, Matheron G, Ghosh S, Toupet O, and Ono M. Fast approximate clearance evaluation for rovers with articulated suspension systems. Journal of Field Robotics, 37(5):768–785, 2020. [Google Scholar]
- [22].Papadakis P. Terrain traversability analysis methods for unmanned ground vehicles: A survey. Engineering Applications of Artificial Intelligence, 26(4):1373–1385, 2013. [Google Scholar]
- [23].Peng C, Li S, Zhao Y, and Bao Y. Sample average approximation of CVaR-based hedging problem with a deep-learning solution. North American Journal of Economics and Finance, 56, 2021. ISSN; 10629408. doi: 10.1016/j.najef.2020.101325. [DOI] [Google Scholar]
- [24].Rockafellar RT, Royset JO, and Miranda SI. Superquantile regression with applications to buffered reliability, uncertainty quantification, and conditional value-at-risk. European Journal of Operational Research, 234(1):140–154, 2014. [Google Scholar]
- [25].Santamaria A, Thakker R, Fan DD, Morrell B, and Agha-mohammadi A.-a.. Towards resilient autonomous navigation of drones. Proceedings of the International Symposium on Robotics Research, 2019. [Google Scholar]
- [26].Shamir O and Zhang T. Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging schemes. In International conference on machine learning, pages 71–79. PMLR, 2013. [Google Scholar]
- [27].Tamar A, Glassner Y, and Mannor S. Optimizing the cvar via sampling. In Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015. [Google Scholar]
- [28].Thakker R, Alatur N, Fan DD, Tordesillas J, Paton M, Otsu K, Toupet O, and Agha-mohammadi A. Autonomous off-road navigation over extreme terrains with perceptually-challenging conditions. International Symposium on Experimental Robotics, 2020. [Google Scholar]