DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES - Technical analysis of cybersecurity measures in data protection and privacy JANUARY 2021
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES Technical analysis of cybersecurity measures in data protection and privacy JANUARY 2021 0

DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 ABOUT ENISA The European Union Agency for Cybersecurity, ENISA, is the Union’s agency dedicated to achieving a high common level of cybersecurity across Europe. Established in 2004 and strengthened by the EU Cybersecurity Act, the European Union Agency for Cybersecurity contributes to EU cyber policy, enhances the trustworthiness of ICT products, services and processes with cybersecurity certification schemes, cooperates with Member States and EU bodies, and helps Europe prepare for the cyber challenges of tomorrow. Through knowledge sharing, capacity building and awareness raising, the Agency works together with its key stakeholders to strengthen trust in the connected economy, to boost resilience of the Union’s infrastructure, and, ultimately, to keep Europe’s society and citizens digitally secure. For more information, visit www.enisa.europa.eu. CONTACT For contacting the authors please use [email protected]. For media enquiries about this paper, please use [email protected]. CONTRIBUTORS Cedric Lauradoux (INRIA), Konstantinos Limniotis (HDPA), Marit Hansen (ULD), Meiko Jensen (Kiel University), Petros Eftasthopoulos (NortonLifeLock) EDITORS Athena Bourka (ENISA), Prokopios Drogkaris (ENISA) ACKNOWLEDGEMENTS We would like to thank the European Data Protection Supervisor (EDPS), Technology and Privacy Unit, for reviewing this report and providing valuable comments. We would also like to thank Giuseppe D'Acquisto (Italian DPA), Nils Gruschka (University of Oslo) and Simone Fischer-Hübner (Karlstad University) for their review and valuable comments. LEGAL NOTICE Notice must be taken that this publication represents the views and interpretations of ENISA, unless stated otherwise. This publication should not be construed to be a legal action of ENISA or the ENISA bodies unless adopted pursuant to the Regulation (EU) No 2019/881. This publication does not necessarily represent state-of the-art and ENISA may update it from time to time. Third-party sources are quoted as appropriate. ENISA is not responsible for the content of the external sources including external websites referenced in this publication. This publication is intended for information purposes only. It must be accessible free of charge. Neither ENISA nor any person acting on its behalf is responsible for the use that might be made of the information contained in this publication. 1

DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 COPYRIGHT NOTICE © European Union Agency for Cybersecurity (ENISA), 2021 Reproduction is authorised provided the source is acknowledged. For any use or reproduction of photos or other material that is not under the ENISA copyright, permission must be sought directly from the copyright holders. ISBN 978-92-9204-465-7 - DOI 10.2824/860099. 2
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 TABLE OF CONTENTS 1. INTRODUCTION 7 1.1 BACKGROUND 7 1.2 OBJECTIVES 8 1.3 OUTLINE 9 2. PSEUDONYMISATION BASICS 10 2.1 PSEUDONYMISATION SCENARIOS 10 2.2 PSEUDONYMISATION TECHNIQUES AND POLICIES 12 3. ADVANCED PSEUDONYMISATION TECHNIQUES 14 3.1 ASYMMETRIC ENCRYPTION 14 3.2 RING SIGNATURES AND GROUP PSEUDONYMS 16 3.3 CHAINING MODE 18 3.4 PSEUDONYMS BASED ON MULTIPLE IDENTIFIERS OR ATTRIBUTES 19 3.5 PSEUDONYMS WITH PROOF OF OWNERSHIP 21 3.5.1 Zero-Knowledge Proof 22 3.6 SECURE MULTIPARTY COMPUTATION 23 3.7 SECRET SHARING SCHEMES 25 3.8 CONCLUSION 26 4. PSEUDONYMISATION USE CASES IN HEALTHCARE 27 4.1 EXAMPLE SCENARIO 27 4.2 PSEUDONYMISATION USE CASES 28 4.2.1 Patient record comparison use-case 28 4.2.2 Medical research institution use-case 30 4.2.3 Distributed storage use-case 31 3

DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 4.3 ADVANCED PSEUDONYMISATION SCENARIO: THE DATA CUSTODIANSHIP 32 4.3.1 Notion of data custodianship 32 4.3.2 Personal Information Management System (PIMS) as data custodian 34 4.3.3 Data custodian as a part of the hospital 34 4.3.4 Data custodian as an independent organisation 35 4.3.5 Interconnected data custodian network 36 5. PSEUDONYMISATION USE CASES IN CYBERSECURITY 38 5.1 THE ROLE AND SCOPE OF SECURITY TELEMETRY 38 5.2 A USE CASE ON REPUTATION SYSTEM TRAINING AND USER-TAILORED PROTECTION 39 5.2.1 Entities and roles 39 5.2.2 File Reputation 40 5.2.3 URL Reputation 42 5.3 USE CASES ON SECURITY OPERATIONS AND CUSTOMER SUPPORT CENTRES 43 5.3.1 Security Operations Centers 43 5.3.2 Consumer customer support 44 5.3.3 Protection gap and real-time protection 46 5.4 ADDITIONAL CYBERSECURITY USE CASES 46 6. CONCLUSIONS AND RECOMMENDATIONS 47 7. REFERENCES 50 4

DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 EXECUTIVE SUMMARY Pseudonymisation is an established and accepted data protection measure that has gained additional attention following the adoption of the General Data Protection Regulation (GDPR) 1 where it is both specifically defined and many times referenced as a safeguard. ENISA, in its prior work on this field, has explored the notion and scope of data pseudonymisation, while presenting some basic technical methods and examples to achieve pseudonymisation in practice. In this new report, ENISA complements its past work by discussing advanced pseudonymisation techniques, as well as specific use cases from the specific sectors of healthcare and cybersecurity. In particular, the report, building on the basic pseudonymisation techniques, examines advanced solutions for more complex scenarios that can be based on asymmetric encryption, ring signatures and group pseudonyms, chaining mode, pseudonyms based on multiple identifiers, pseudonyms with proof of knowledge and secure multi-party computation. It then applies some of these techniques in the area of healthcare to discuss possible pseudonymisation options in different example cases, while also exploring the possible application of the data custodianship model. Lastly, it examines the application of basic pseudonymisation techniques in common cybersecurity use cases, such as the use of telemetry and reputation systems. Based on the analysis provided in the report, the following basic conclusions and recommendations for all relevant stakeholders are provided. Defining the best possible technique As it has been stressed also in past ENISA’s reports, there is no fit-for-all pseudonymisation technique and a detailed analysis of the case in question is necessary in order to define the best possible option. To do so, it is essential to take a critical to look into the semantics (the “full picture”) before conducting data pseudonymisation. In addition, pseudonymisation is only one possible technique and must be combined with a thorough security risk assessment for the protection of personal data. Data controllers and processors should engage in data pseudonymisation, based on a security and data protection risk assessment and taking due account of the overall context and characteristics of personal data processing. This may also comprise methods for data subjects to pseudonymise personal data on their side (e.g. before delivering data to the controller/processor) to increase control of their own personal data. Regulators (e.g. Data Protection Authorities and the European Data Protection Board) should promote risk-based data pseudonymisation through the provision of relevant guidance and examples. 1 Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation), https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32016R0679&from=EN 5

DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 Advanced techniques for advanced scenarios While the technical solution is a critical element for achieving proper pseudonymisation, one must not forget that the organisational model and its underlying structural architecture are also very important parameters of success. Advanced techniques go together with advanced scenarios, such as the case of the data custodianship model. Data controllers and processors should consider possible scenarios that can support advanced pseudonymisation techniques, based – among other – on the principle of data minimisation. The research community should support data controllers and processors in identifying the necessary trust elements and guarantees for the advanced scenarios (e.g. data custodianship) to be functional in practice. Regulators (e.g. Data Protection Authorities and the European Data Protection Board) should ensure that regulatory approaches, e.g. as regards new technologies and application sectors, take into account all possible entities and roles from the standpoint of data protection, while remaining technologically neutral. Establishing the state-of-the-art Although a lot of work is already in place, there is certainly more to be done in defining the state-of-the-art in data pseudonymisation. To this end, research and application scenarios must go hand-in-hand, involving all relevant parties (researchers, industry, and regulators) to discuss joined approaches. The European Commission, the relevant EU institutions, as well as Regulators (e.g. Data Protection Authorities and the European Data Protection Board) should support the establishment and maintenance of the state-of-the-art in pseudonymisation, bringing together all relevant stakeholders in the field (regulators, research community, and industry). The research community should continue its efforts on advancing the existing work on data pseudonymisation, addressing special challenges appearing from emerging technologies, such as Artificial Intelligence. The European Commission and the relevant EU institutions should support and disseminate these efforts. Towards the broader adoption of data pseudonymisation Recent developments, e.g. in international personal data transfers, show clearly the need to further advance appropriate safeguards for personal data protection. This will only be intensified in the future by the use of emerging technologies and the need for open data access. It is, thus, important to start today the discussion on the broader adoption of pseudonymisation in different application scenarios. Regulators (e.g. Data Protection Authorities and the European Data Protection Board), the European Commission and the relevant EU institutions should disseminate the benefits of data pseudonymisation and provide for best practices in the field. 6

DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 1. INTRODUCTION Pseudonymisation is an established and accepted data protection measure that has gained additional attention following the adoption of the General Data Protection Regulation (GDPR), where it is both specifically defined (Article 4(5) GDPR)2 and many times referenced as a safeguard. Technical and organisational measures, in particular for security and data protection by design, comprise pseudonymisation. The application of pseudonymisation to personal data can reduce the risks to the data subjects concerned and help controllers and processors meet their data protection obligations. Nevertheless, not every so-called pseudonymisation mechanism fulfils the definition of the GDPR, and pseudonymisation techniques that may work in one specific case to achieve data protection, may not be sufficient in other cases3. Still, the basic concept of substituting identifying data with pseudonyms can contribute to reducing data protection risks. 1.1 BACKGROUND Given the growing importance of pseudonymisation for both data controllers and data subjects, ENISA has been working over the past years on this topic, in co-operation with experts and national regulatory authorities. Indeed, ENISA issued its first relevant report in January 2019 (ENISA, 2019 - 1) presenting an overview of the notion and main techniques of pseudonymisation in correlation with its new role under the GDPR. A second ENISA report followed in November 2019 (ENISA, 2019 - 2) with a more detailed analysis of the technical methods and specific examples and best practices for particular data sets, i.e. email addresses, IP addresses and more complex data sets. In addition, a dedicated workshop on pseudonymisation4 was co-organised by ENISA and the Data Protection Authority of the German Federal State of Schleswig-Holstein (ULD) in November 2019 in order to exchange information and experience among key stakeholders5. While work and regulatory guidance in the field is growing 6, it is apparent that further effort is needed, especially addressing specific application scenarios and different types of datasets. Both ENISA’s reports and the conclusions of the ULD-ENISA workshop lead towards this direction, which could eventually support the development of “a catalogue of techniques” or a “cookbook” towards applying pseudonymisation in practice in different application scenarios. 2 It has to be noted that personal data that has been pseudonymised is still regarded as “personal data” pursuant to Article 4(1) GDPR and must not be confused with “anonymised data” where it is no longer possible for anyone to refer back to individual data subjects, see Recital 28 GDPR. 3 In order to fully understand the role of pseudonymisation for the processing of personal data, a full analysis of the legal situation in the specific case would also be required. For the assessment of concrete processing operations, controllers and processors must take account of all factors playing a role for the risk to the fundamental rights of individuals induced by the processing as such and by potential breaches of security, also going beyond technical and organisational measures considered in this study. 4 https://www.enisa.europa.eu/events/uld-enisa-workshop/uld-enisa-workshop-pseudonymization-and-relevant-security- technologies 5 https://www.enisa.europa.eu/events/uld-enisa-workshop/uld-enisa-workshop-notes/view 6 See also EDPS and Spanish DPA joint paper on the introduction of hash as pseudonymisation technique, https://edps.europa.eu/data-protection/our-work/publications/papers/introduction-hash-function-personal-data_en 7

DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 Should this be achieved, it would be a significant step towards the definition of the state-of-the- art for pseudonymisation techniques. Against this background and following previous relevant ENISA’s work7, the Agency decided under its 2020 work-programme to elaborate further on the practical application of data pseudonymisation techniques. 1.2 OBJECTIVES The overall scope of this report is to continue past ENISA’s work by providing (on the basis of the previous analysis) specific use cases for pseudonymisation, along with more advanced techniques and scenarios that can support its practical implementation by data controllers or processors. More specifically, the objectives of the report are as follows: Explore further advanced pseudonymisation techniques which were not covered in prior ENISA’s work, based on cryptographic algorithms and privacy enhancing technologies. Discuss specific application use cases where pseudonymisation can be applied, analysing the particular scenarios, roles and techniques that could be of interest in each case. In particular, for the scope of the report, use cases are presented in two different sectors: (a) healthcare information exchange; (b) cybersecurity information exchange with the use of innovative technologies (e.g. machine learning technologies). It should be noted that the selection of the use cases was based on the fact that the specific sectors (healthcare, cybersecurity) represent quite common cases for the application of pseudonymisation in several real-life situations. At the same time, the selected use cases also reflect diverse requirements with regard to pseudonymisation, e.g. in terms of the scenarios/roles involved, as well as in terms of the techniques that could be applied in practice. The target audience of the report consists of data controllers, data processors and manufacturers/producers of products, services and applications, Data Protection Authorities (DPAs), as well as any other interested party in data pseudonymisation. The document assumes a basic level of understanding of personal data protection principles and the role/process of pseudonymisation. For an overview of data pseudonymisation under GDPR, please also refer to relevant ENISA’s work in the field (ENISA, 2019 - 1) & (ENISA, 2019 - 2). The discussion and examples presented in the report are only focused on technical solutions that could promote privacy and data protection; they should by no means be interpreted as a legal opinion on the relevant cases. 7 https://www.enisa.europa.eu/topics/data-protection/privacy-by-design 8

DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 1.3 OUTLINE The outline of the remaining part of the report is as follows: Chapter 2 provides an overview of the basic scenarios, pseudonymisation techniques and policies discussed under (ENISA, 2019 - 2). Chapter 3 presents a number of advanced pseudonymisation techniques, including asymmetric encryption, ring signatures, chaining mode, Merkle trees, pseudonyms with proof or ownership, secure multiparty computation and secret sharing schemes. Chapter 4 analyses pseudonymisation techniques and application scenarios in the area of healthcare. It particularly focuses on the use of the tree-based pseudonyms approach and the data custodianship model. Chapter 5 discusses the application of pseudonymisation in the broader area of cybersecurity technologies. Chapter 6 summarises the previous discussions and provides the main conclusions and recommendations for all related stakeholders. This report is part of the work of ENISA in the area of privacy and data protection 8, which focuses on analysing technical solutions for the implementation of GDPR, privacy by design and security of personal data processing. 8 https://www.enisa.europa.eu/topics/data-protection 9
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 2. PSEUDONYMISATION BASICS As mentioned in (ENISA, 2019 - 2), the most obvious benefit of pseudonymisation is to hide the identity of the data subjects from any third party (other than the Pseudonymisation Entity, i.e. the entity responsible for pseudonymisation). Still, pseudonymisation can go beyond hiding real identities and data minimisation into supporting the data protection goal of unlinkability and contributing towards data accuracy. When implementing pseudonymisation, it is important to clarify as a first step the application scenario and the different roles involved, in particular the role of the Pseudonymisation Entity (PE), which can be attributed to different entities (e.g. a data controller, a data processor, a Trusted Third Party or the data subject), depending on the case. Under a specific scenario, it is then required to consider the best possible pseudonymisation technique and policy that can be applied, given the benefits and pitfalls that each one of those techniques or policies entails. Obviously, there is not a one-size-fits-all approach and risk analysis should in all cases be involved, considering privacy protection, utility, scalability, etc. In that regard, this Chapter provides a brief overview of the basic pseudonymisation scenarios and techniques, as these are outlined in (ENISA, 2019 - 2), which will be then further complemented and analysed in the next Chapters of the report. 2.1 PSEUDONYMISATION SCENARIOS Six different pseudonynimisation scenarios are discussed in (ENISA, 2019 - 2) and are presented in Figure 1 below. The defining difference between the scenarios is firstly the actor who takes the role of the Pseudonymisation Entity (PE) and secondly the other potential actors that may be involved (and their roles). Clearly, in all three first scenarios in Figure 1, the data controller is the PE, either acting alone (scenario 1) or involving a processor before pseudonymisation (scenario 2) or after pseudonymisation (scenario 3). In scenario 4, the PE is the processor that performs pseudonymisation on behalf of the controller (thus, controller maintaining still control over the original data). Scenario 5 sets a Trusted Third Party entity, outside the control of the data controller, as PE, therefore involving an intermediary to safeguard the pseudonymisation process. Lastly, scenario 6 provides for data subjects to be the PE and, thus, control an important part of the pseudonymisation process. Later in this report we will explore the practical application of these scenarios in specific cases, especially scenarios 1 and 3 under cybersecurity use cases (Chapter 5) and scenarios 5 and 6 under healthcare use cases (Chapter 4). For the scenario 5 particularly we will further detail the notion of the Trusted Third Party (data custodian) and the forms that it could take in the healthcare sector. 10
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 Figure 1: Basic pseudonymisation scenarios 11
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 2.2 PSEUDONYMISATION TECHNIQUES AND POLICIES The basic pseudonymisation techniques that can be applied in practice, as also discussed in (ENISA, 2019 - 2) are as follows: Counter: the simplest pseudonymisation function, where the identifiers are substituted by a number chosen by a monotonic counter. Its advantages rest with its simplicity, which make it a good candidate for small and not complex datasets. It provides for pseudonyms with no connection to the initial identifiers (although the sequential character of the counter can still provide information on the order of the data within a dataset). However, the solution may have implementation and scalability issues in cases of large and more sophisticated datasets. Random Number Generator (RNG): a similar approach to the counter with the difference that a random number is assigned to the identifier. It provides strong data protection (as, contrary to the counter, a random number is used to create each pseudonym, thus it is difficult to extract information regarding the initial identifier, unless the mapping table is compromised). Collisions, however, may be an issue 9, as well as scalability, depending on the implementation scenario. Cryptographic hash function: directly applied to an identifier to obtain the corresponding pseudonym with the properties of being a) one-way and b) collision free10. While a hash function can significantly contribute towards data integrity, it is generally considered weak as a pseudonymisation technique, as it is prone to brute force and dictionary attacks (ENISA, 2019 - 2). Message authentication code (MAC): similar to a cryptographic hash function except that a secret key is introduced to generate the pseudonym. Without the knowledge of this key, it is not possible to map the identifiers and the pseudonyms. MAC is generally considered as a robust pseudonymisation technique from a data protection point of view. Recovery might be an issue in some cases (i.e. if the original identifiers are not being stored). Different variations of the method may apply with different utility and scalability requirements. HMAC (Bellare, Canetti, & Krawczyk, 1996) is by far the most popular design of message authentication code used in Internet protocols. Symmetric encryption: the block cipher is used to encrypt an identifier using a secret key, which is both the pseudonymisation secret and the recovery secret. Using block ciphers for pseudonymisation requires to deal with the block size. Symmetric encryption is a robust pseudonymisation technique, with several properties being similar to MAC (i.e. the aforementioned properties of the secret key). One possible issue in terms of data minimisation is that the PE can always reverse the pseudonyms, even if there is no need to store the initial individuals’ identifiers. 9 Still, it should be noted that cryptography-based constructions of pseudo-random number generators are available, which can avoid collisions if they are properly configured and could be possibly similarly used to provide pseudonyms (e.g. discrete logarithm based constructions (Blum, Feldman, & Micali, 1984). 10 This holds under the assumption that a cryptographically strong hash function is used. Moreover, it is essential that hashing should be applied to appropriate individual’s identifiers (e.g. hashing the first name and last name may not avoid collisions, if this combination does not constitute an identifier in a specific context – i.e. there may be two individuals with the same fist name and last name). More details are given in (ENISA, 2019 - 1) (ENISA, 2019 - 2). 12
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES January 2021 Independently of the choice of the technique, the pseudonymisation policy (i.e. the practical implementation of the technique) is also critical to the implementation in practice. Three different pseudonymisation policies have been considered to that end: Deterministic pseudonymisation: in all the databases and each time it appears, is always replaced by the same pseudonym . Document randomised pseudonymisation: each time appears in a database, it is substituted with a different pseudonym ( 1 , 2 ,...); however, is always mapped to the same collection of ( 1 , 2 ) in the dataset and . Fully randomised pseudonymisation: for any occurrences of within a database or , is replaced by a different pseudonym ( 1 , 2 ). As summarised in (ENISA, 2019 - 2), the choice of a pseudonymisation technique and policy depends on different parameters, primarily the identified level or risk and the expected/identified utilisation of the pseudonymised dataset In terms of protection, random number generator, message authentication codes and encryption are stronger techniques as they prevent by design exhaustive search, dictionary search and random search. Still, utility requirements might lead the Pseudonymisation Entity (PE) towards a combination of different approaches or variations of a selected approach. Similarly, with regard to pseudonymisation policies, fully- randomised pseudonymisation offers the best protection level but prevents any comparison between databases. Document-randomised and deterministic functions provide utility but allow linkability between records. Using the aforementioned scenarios, techniques and policies as a basis for any practical implementation of pseudonymisation, Chapter 3 explores more advanced techniques that often rely on the basic existing techniques, while offering advanced protection, along with other properties. Chapters 4 and 5 discuss how both basic and advanced techniques can be employed in practice with specific examples and use cases. 13
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES Final Draft | 3.3 | Internal | January 2021 3. ADVANCED PSEUDONYMISATION TECHNIQUES In Chapter 2 we presented a number of pseudonymisation techniques (alongside with relevant policies and scenarios) that can improve the level of protection of personal data, provided that the pseudonymisation secrets used to create the pseudonyms are not exposed. However, in order to address some specific personal data protection challenges, typical pseudonymisation techniques, such as pseudonymisation tables or conventional cryptographic primitives (ENISA, 2019 - 2) may not always suffice. It is possible though to create pseudonyms addressing more complex situations, whilst the risks of a personal data breach are minimised. This Chapter reviews some of these solutions, based on cryptographic techniques, and discusses what problems they could be used to solve in practice. In particular, the following techniques are presented: Asymmetric encryption. Ring signatures and group pseudonyms. Chaining mode. Pseudonyms based on multiple identifiers or attributes. Pseudonyms with proof of ownership. Secure multiparty computations. Secret sharing schemes. For each technique we analyse its application to support pseudonymisation, pointing out possible examples, as well as shortcomings in this context. 3.1 ASYMMETRIC ENCRYPTION Although symmetric encryption is most commonly used (compared to asymmetric encryption) in the area of pseudonymisation, asymmetric encryption has some interesting properties that could also support data minimisation and the need-to-know principle, while providing robust protection. Asymmetric encryption enables the possibility to have two different entities involved during the pseudonymisation process: (i) a first entity can create the pseudonyms from the identifiers using the Public pseudonymisation Key (PK), and (ii) another entity is able to resolve the pseudonyms to the identifiers using the Secret (private) pseudonymisation Key (SK)11. The entity who applies the pseudonymisation function and the entity who can resolve the pseudonyms into the original identifiers do not have to share the same knowledge. For example, a data controller can make available its public key PK to its data processors. The data processors can collect and pseudonymise the personal data using the PK. The data controller is the only entity which can later compute the initial data from the pseudonyms. Such a scenario is strongly related to the generic scenario of a data processor being the 11 Actually other combinations are also possible, as they are being discussed later on; for example, utilising the private key may allow for proof of ownership of a pseudonym (see Section 3.5, Chapter 3). 14
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES Final Draft | 3.3 | Internal | January 2021 Pseudonymisation Entity (see Scenario 4 in Section 2.1 Chapter 2), with the additional advantage, in terms of protecting individuals’ identities, that the processors do not have the pseudonymisation secret12. It is not possible to achieve such pseudonymisation scheme using symmetric encryption because the data controller and the data processor need to share the same pseudonymisation secret. Similarly, a Trusted Third Party (TTP) may publish its public key PK to one or more data controllers. In such a scenario, the TTP can resolve any pseudonym created by a data controller using its private key SK (e.g. at the request of a data subject); such scenario may also be relevant to cases of joint controllership, where a controller is performing the pseudonymisation and another controller only receives the pseudonymised data for further processing (see Scenario 5 in (ENISA, 2019 - 2)). Therefore, asymmetric encryption facilitates the delegation of pseudonymisation. However, pseudonymisation using asymmetric encryption needs to be carefully implemented (see also (ENISA, 2019 - 1)). For example, textbook application of RSA (Rivest, Shamir, & Adleman, 1978) or Rabin scheme (Rabin, 1979) both fail to achieve strong pseudonymisation. Indeed, since the encryption key PK is publicly available, an adversary knowing both PK and the set of original identifiers can perform an exhaustive search attack for those schemes. Therefore It is important to use a randomised encryption scheme – i.e. at each encryption, a random value (nonce) is being introduced to ensure that for given input (user’s identifier) and PK, the output (pseudonym) cannot be predicted (ENISA, 2019 - 1). Several asymmetric encryption algorithms are by default randomised, like Paillier (Paillier, Public-Key Cryptosystems Based on Composite Degree Residuosity Classes, 1999) or Elgamal (Elgamal, 1985). It should be noted that, by these means, a fully-randomised pseudonymisation policy is achieved – i.e. a different pseudonym is derived each time for the same identifier, without changing the pseudonymisation process or the pseudonymisation secret (see Section 5.2.3 (ENISA, 2019 - 2)). Although in cryptographic applications the usage of asymmetric encryption algorithms implies that the relevant PKs are available to everyone (including adversaries), in the context of pseudonymisation we may deviate from this assumption (thus allowing for more flexibility in designing pseudonymisation schemes)13; indeed, the PK in such cases is needed to be known only by the pseudonymisation entities (regardless of their role – i.e. data controllers, data processors, data subjects), since these are the only entities, which will need to utilise this PK to perform pseudonymisation – and, thus, this public key should be distributed to the Pseudonymisation Entities through a secure channel. However, even if the PK is indeed available to everyone, the inherent security properties of asymmetric encryption ensure that an adversary will not be able to reverse pseudonymisation, under the assumption that a cryptographically strong asymmetric algorithm is being used14. It is worth mentioning that certain asymmetric encryption schemes support homomorphic operations (Armknecht, et al., 2015). Homomorphic encryption is a specific type of encryption, allowing a third party (e.g. a cloud service provider) to perform certain computations on the ciphertexts without having knowledge of the relevant decryption key15. For instance, the product of two pseudonyms created using Paillier’s scheme (which is homomorphic) is the pseudonym of sum of the two identifiers. This advantage, in terms of cryptographic operation, can be also a drawback in terms of pseudonymisation. An adversary can substitute a pseudonym by the 12 Assuming that the data processors do not store the mapping between original identifiers and the derived pseudonyms. 13 This may be necessary in some cases, e.g. if it is not desirable that any other party, apart from the Pseudonymisation Entity, has adequate information to allow that party generating valid pseudonyms for a specific application. 14 Indeed, an adversary, even if the PK is unknown, can resolve any pseudonyms if he/she knows either (i) the original identifiers and all the nonces or (ii) the secret key SK. For the first case (i), the adversary must know all the nonces used during the pseudonymisation which represents a large quantity of data. The second case (ii) is rather unlikely to occur if the secret key SK is protected with appropriate measures (e.g. encrypted on an access-controlled device). 15 For example, an additively homomorphic encryption scheme with E and D as the encryption and decryption functions respectively, satisfies the following: For any input arithmetic messages 1, 2and the corresponding ciphertexts 1 = ( 1), 2 = ( 2) obtained by the same encryption key, performing the decryption ( 1 + 2) with the corresponding private key yields the sum 1 + 2 (i.e. adding ciphertexts results in the encryption of the sum of the original messages). 15
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES Final Draft | 3.3 | Internal | January 2021 product of other pseudonyms P1 and P2 without knowing the public key PK or even the original identifiers associated to P1 and P2; therefore, if the sum of two identifiers is also a meaningful identifier (for example, in case of numerical identifiers with no prescribed format), a valid pseudonym can be generated by an adversary without having access to the pseudonymisation secret. This issue can also occur with certain symmetric encryption schemes. Consequently, if the homomorphic property is present, appropriate safeguards should also be in place (for example, appropriate integrity measures to ensure that it is not possible to tamper with the pseudonyms).The generation speed and the size of the pseudonym obtained using asymmetric encryption can also be an issue. These parameters are strongly correlated to the size of the keys16. For certain setups, the key size can be up to 2018 or 3096 bits. However, it is possible to use elliptic curves cryptography to reduce this cost to 256 bits (Paillier, Trapdooring Discrete Logarithms on Elliptic Curves over Rings, 2000), (Joye, 2013). There are efficient implementations of elliptic curves cryptography that reduce the performance gap with symmetric encryption. Several pseudonymisation schemes based on asymmetric encryption have already been proposed. A typical application is to make available healthcare data to research groups; more precisely, by using fully randomised pseudonymisation schemes based on asymmetric cryptography (ENISA, 2019 - 1), we may ensure that the identifiers (e.g. social security number or medical registration number or any other identifier) of a given patient are not linkable. For instance, a participant may have different local pseudonyms at doctors X, Y, Z, and at medical research groups U, V, W – thus providing domain-specific pseudonyms to ensure unlinkability between these different domains; by these means, doctors will store both the real name/identity of their patients and their local pseudonyms, but researchers will only have (their own) local pseudonyms. . As characteristic examples, ElGamal cryptosystem has been used in (Verheul, Jacobs, Meijer, Hildebrandt, & de Ruiter, 2016) and Paillier in (He, Ganzinger, & Hurdle, 2013), (Kasem-Madani, Meier, & Wehner). Another application of asymmetric encryption for pseudonymisation is outsourcing. In (Lehmann, 2019), a distributed pseudonymisation scheme based on ElGamal is proposed. An entity can pseudonymise a dataset without learning neiither any sensitive data nor the created pseudonyms. It is also used as a building block to create a more advanced form of pseudonymisation like in (Camenisch & Lehmann, (Un)linkable Pseudonyms for Governmental Databases, 2015), (Camenisch & Lehmann, Privacy-Preserving User-Auditable Pseudonym Systems, 2017). As another characteristic example, in which asymmetric cryptographic primitives have an essential role, is the case of the so-called linkable transaction pseudonyms, introduced in (Weber, 2012). By the approach described therein, users may generate their own transaction pseudonyms – i.e. short-term pseudonyms – providing unlinkability (that is different pseudonyms each time for the same user), but with the additional property that some linkability can be present in a step-wise re-identification fashion (for example, authorised parties may link pseudonyms without being able though to reveal the actual identity or may check if a pseudonym corresponds to a user with specific attributes). However, in the work presented in (Weber, 2012), not simply asymmetric encryption but more complex cryptographic primimitives such as zero-knowledge proofs and threshold encryption are being used; such primitives are being individually discussed next in this Chapter. 3.2 RING SIGNATURES AND GROUP PSEUDONYMS The notion of digital signatures is widely used in many applications, constituting a main cryptographic primitive towards ensuring both the integrity of the data as well as the authentication of the originating user, i.e. the so-called signer of the message. The underlying idea of a conventional digital signature is that anybody can verify the validity of the signature, 16 https://www.keylength.com/ 16
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES Final Draft | 3.3 | Internal | January 2021 which - in the typical scenario - is associated with a known signer. Typically, asymmetric encryption provides the means for implementing digital signatures, since they are both based on the safe concept of Public and Private key, as well as on a Trusted Third Party (TTP) issuing the keys. In many pseudonymisation schemes, like (Camenisch & Lehmann, (Un)linkable Pseudonyms for Governmental Databases, 2015), (Camenisch & Lehmann, Privacy-Preserving User-Auditable Pseudonym Systems, 2017), (Lehmann, 2019), signature schemes are also combined with other primitives (e.g. asymmetric encryption) to achieve advanced properties like auditability. Several advanced digital signature techniques are known, with diverge properties, each aiming to a different challenge based on the requirements of a specific application. One such scheme is the so-called ring signature. A ring signature is a digital signature that is created by a member of a group of users, so as to ensure the following property: the verifier can check that the signature has indeed been created by a member from this group, whilst he/she cannot determine exactly the person in the group who has created the signature. In other words, the identity of the signer is indistinguishable from any other user of this group. The first approach for ring signatures scheme has been proposed by (Rivest, Shamir, & Tauman, 2001). Ring signatures do not necessitate a TTP. This concept is based on asymmetric cryptography, as it is assumed that each possible signer (i.e. the kth amongst n users, 1 ≤ k ≤ n) is associated with a public key Pk and a relevant secret (private) key Sk. In this scheme, any user from the group can generate, for any given message m, a signature s by appropriately using his/her secret key and the public keys of all the other members of the group. A verifier with access to the public keys of all members of the group is able to confirm that a given signed message m has been signed by a member of the group, but he/she cannot identify explicitly which user is the actual signer. In their original paper, (Rivest, Shamir, & Tauman, 2001) described ring signatures as a way to leak a secret; for instance, a ring signature could be used to provide a verifiable signature from “a high-ranking official” (i.e. a member of a well-determined group of officials), without revealing though who exactly is the official that signed the message. Figure 2: The ring signature operation A variant of traditional ring signatures, being called linkable ring signatures, has been proposed in (Liu & Wong, 2005), which allows any of n group members to generate a ring signature on some message, with the additional property that all signatures from the same member can be linked together. Although ring signatures are often being mentioned as anonymous signatures in the literature, they actually constitute pseudonymous data. Indeed, such signatures are in fact uniquely associated to a person (under the assumption that the group of possible signers consists of individuals), despite the fact that no other entity can explicitly re-identify the signer. However, the secret key of the signer suffices to prove, if it is revealed, that the signature has been generated by him/her. Therefore, we actually have a pseudonymous scheme, allowing for a specific utilisation (i.e. verifying that the data stem from a well-determined group of users), in 17
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES Final Draft | 3.3 | Internal | January 2021 which the pseudonymisation secret (i.e. the secret key17) is under the sole control of the data subject. Ring signatures are being recently used, as a privacy enhancing technology, for the creation of the so-called anonymous cryptocurrencies (see, for, example, the open-source technology Cryptonote18); in this framework, ring signatures may provide the means for implementing untraceable payments – i.e. for each incoming transaction, all possible senders are equiprobable. In other words, a verifier can only verify that a signer of a transaction belongs to a specific group of users, without being able to explicitly pinpoint the user that signed the transaction. Despite the use of the term “anonymous cryptocurrency”, these data are actually pseudonymous – and not anonymous – data, where the user (signer) owns his/her pseudonymisation secret. Group pseudonyms have been used in many contact tracing protocols (like Pronto-C2 (Avitabile, Botta, Iovino, & Visconti, 2020)) proposed during the COVID-19 pandemic. The idea is that each time two data subjects meet, a pseudonym is created with a contribution from each data subject. After the encounter, they both have computed the same pseudonym. Each data subject has a list of group or encountered pseudonyms. If one of them is exposed, all his/her group pseudonyms are published on a public board and all the contacts can check if they have been exposed. This pseudonymisation scheme is randomised in such that when two data subjects meet again, they always obtain a new group pseudonym to avoid any malicious traceability. 3.3 CHAINING MODE As discussed in (ENISA, 2019 - 2), a secure cryptographic hash function is rarely expected to be an appropriate pseudonymisation technique. Authentication codes and keyed-hash functions must be preferred – which include the use of a secret key. However, more advanced techniques can be obtained by appropriately chaining hash functions, as discussed next. Chaining the outputs of multiple cryptographic hash functions was first proposed by Lamport (Lamport, 1981) to store passwords. This idea has been generalised to create key derivation functions (Krawczyk, 2010) and password hashing functions (Biryukov, Dinu, & Khovratovich, 2016), which can be used to pseudonymise personal data. Figure 3: A typical hash chain Previous approaches of chaining (Lamport, 1981), (Krawczyk, 2010), (Biryukov, Dinu, & Khovratovich, 2016) involved only one entity, however the approach of chaining keyed hash functions discussed in this report is distributed (Figure 3). It is a layered approach: i.e. several somehow intermediate pseudonyms are (temporarily) generated, in order to finally obtain the 17 This actually constitutes the additional information needed to allow re-identification, according to the Article 4(5) of the GDPR. 18 https://cryptonote.org/ 18
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES Final Draft | 3.3 | Internal | January 2021 pseudonym, which is the output of the last hash function. Each layer is computed by a different entity19 and each entity holds a secret used to obtain an intermediate pseudonym. As depicted in Figure 3, K1 is used to obtain the temporary value = 1 ( ). Value X is then transmitted to the second entity which computes = 2 ( ). Finally, the last entity computes the = 3 ( ). Such a chain mitigates the risk of a data breach. An adversary needs to compromise the three entities in order to reverse the pseudonymisation, i.e. he/she must know K1, K2, K3. The only drawback of chaining is that pseudonym resolution requires to have the three entities to cooperate. However, on the other side, this ensures an additional property that cannot be achieved by a single keyed hash function; any entity receiving an intermediate pseudonym cannot reverse it, whereas the first entity (which obviously knows the original identifiers) is not able to match the final pseudonyms with the identifiers (of course, these properties hold under the assumption that the secret keys are not exchanged between the pseudonymisation entities). For example, the recipient of the final (or even any intermediate) pseudonym may perform statistical/scientific analysis on the pseudonymous data without being able to map the pseudonyms to the original users’ identifiers. A hash chain can be further generalised into more complex structures. Apparently, the notion of chaining pseudonymisation mechanisms could also be applied more generally – i.e. not only for cryptographic hash functions, but also for other techniques (e.g for typical symmetric cryptographic algorithms). Actually, depending on the application scenario, each entity may apply a different pseudonymisation technique in such a chaining approach, thus allowing for more flexibility which in turn may give rise to more sophisticated pseudonymisation schemes. 3.4 PSEUDONYMS BASED ON MULTIPLE IDENTIFIERS OR ATTRIBUTES Pseudonymisation is usually considered as the processing of an identifier into a pseudonym (one-to-one mapping). It is possible to slightly modify this definition to add new properties. The pseudonym can be the processing of several identifiers (many-to-one mapping). The identifiers can be homogeneous, i.e. they have the same type (only phone number for instance) and they are related to different individuals. Otherwise, they are heterogeneous and they match different attributes of a single individual (social security number, phone number, first name and last name). Any case in between is possible. Any known pseudonymisation technique can be easily applied to more than one identifiers – e.g. a keyed hash function, as pseudonymisation primitive, may have, as input data, a combination of more than one identifiers of an individual in order to derive a pseudonym for him/her (see also (ENISA, 2019 - 1)). However, to ensure some additional properties of such pseudonyms which correspond to many-to-one-mappings, more sophisticated approaches are needed; this is discussed next. Cryptographic accumulators (Benaloh & de Mare, 1993), (Fazio & Nicolosi, 2002)] are best fitted to implement a many-to-one pseudonymisation scheme. A cryptographic accumulator can accumulate a set L of values into a unique, small value z in such a way that it is possible only for elements y L to provide a proof that a given y actually has been accumulated within z. Such a proof is called a witness w. To illustrate this short definition, we provide an example based on Merkle Tree (Merkle, 1987). This cryptographic data structure is a binary tree constructed through hash functions (which in turn could be seen as a generalisation of hash chains). This tree structure could be 19 These entities may have specific roles in terms of personal data protection. For example, these entities could be joint controllers (Article 26 of the GDPR), each of them with a well described role. 19
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES Final Draft | 3.3 | Internal | January 2021 appropriately used for pseudonymisation purposes, as follows: a) the root of the tree is the pseudonym; b) the leaves of the tree correspond to the authentication codes of the identifiers computed using a message authentication code G and different keys20. In such case, the inner nodes of the tree are computed using a cryptographic hash function H. The role of the authentication codes is to ensure that no dictionary attack is possible. The root and the inner nodes of the tree are computed using H to let anybody verify that a leaf is associated to a given root z (i.e. being the witness wi for the corresponding IDi). For example, let us consider the Merkle tree in Figure 4. The pseudonym has been derived by four identifiers (ID1, ID2, ID3 and ID4) and, thus, it depends on all of them. To prove that a known identifier ID1 has contributed in deriving the root pseudonym z, the contributor of ID 1 reveals the corresponding key k1 (which was used for constructing the leaf of the tree corresponding to ID1), as well as the following information: y1 = Gk1 (ID1) (actually y1 is computed by the verifier who knows ID1 and k1) a1 = H(y1||y2) (y2 is provided as part of the witness w1 of ID1, to compute a1) z‘ = H(a1 ||a2 ) (both a1 and a2 are also parts of the witness w1 of ID1). If z’ ≠ z then ID1 does not belong to the set L accumulated into z. Otherwise, it belongs to z. Figure 4: A Merkle tree with 22 = 4 leaves In general, each contributor knows IDi and the corresponding witness wi (including the corresponding key ki) A contributor can later reveal IDi and wi to prove he/she has contributed to z. Actually, this property of Merkle trees is widely used in constructing one-time signature schemes that achieve post-quantum security. It is important to notice that it is impossible to revert the tree, i.e. recover any values ID 1, ID2, ID3 or ID4 while knowing only its root (i.e. the accumulated pseudonym). If a subset of identifiers, ID1 and ID3 for instance, has been revealed, it is still not possible to recover the other identifiers ID2 and ID4. It is only possible to know that ID2 and ID4 have accumulated into z if and only if their corresponding witnesses w2 and w4 have been revealed. 20 In a typical Merkle tree, the leaves are simple (i.e. unkeyed) hash values of some initial data. In the context of pseudonymisation, since a simple hash function is generally considered as a weak technique, it is preferable to employ a secret key to derive the leaves of the tree. Although in this report we refer to authentication codes, other approaches could also be considered – e.g. the leaves could be derived by encryption of the original identifiers. 20
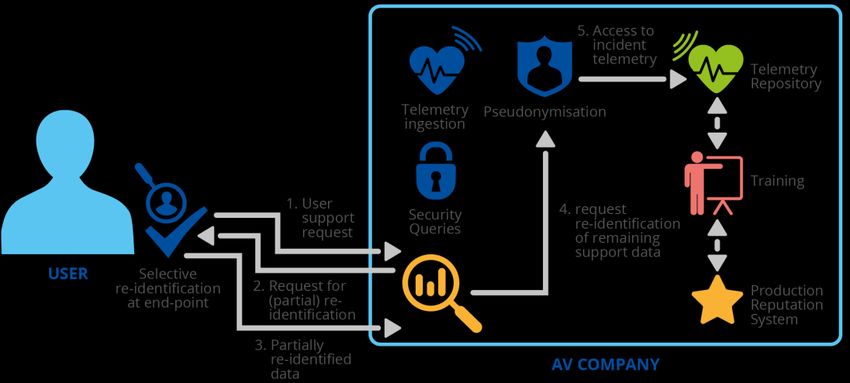
DATA PSEUDONYMISATION: ADVANCED TECHNIQUES & USE CASES Final Draft | 3.3 | Internal | January 2021 Many designs of cryptographic accumulators have been proposed through the years. There are many designs now based on hash functions only (Nyberg, 2005), elliptic curves (Tartary, 2008) or bilinear mapping (Camenisch, Kohlweiss, & Soriente, An Accumulator Based on Bilinear Maps and Efficient Revocation for Anonymous Credentials, 2009). They support different operations like dynamic modifications (addition or revocation) (Barić & Pfitzmann, 1997), (Badimtsi, Canetti, & Yakoubov, 2020). An interesting observation is that the above properties of Merkle trees as pseudonymisation primitives could be preferable in cases that a user-generated pseudonym is needed - i.e. in cases that the Pseudonymisation Entity coincides with the individual. Indeed, an individual may produce a pseudonym based on a list of more than one identifiers of his/her so as: i) no identifier can be computed by any party having access to this pseudonym, ii) the individual is able to prove, at any time, that this pseudonym is bound to a specific identifier from this list (i.e. allowing individual’s identification or authentication, depending on the context), without revealing the secret information or any other identifier from the list. This is also strongly related to the so- called pseudonyms with proof of ownership, as discussed in Section 3.5, Chapter 3. Structures as the Merkle trees (which are binary trees) can be appropriately generalised. Indeed, any tree-structure starting with several types of personal data as its leaves and appropriately moving upwards via employing hashing operations preserves somehow the same properties as described above. Actually, the value at each internal node in this tree structure - which is the hash of a set of values - can be seen as an intermediate pseudonym, depending on one or more individual’s attributes (i.e. being an accumulator of these values). The value z’ of each intermediate pseudonym does not allow computation of the original personal data (i.e. pseudonymisation reversal), but allows for verification whether, for a given initial set of values, these values have accumulated into the pseudonym z’ or not. Each intermediate pseudonym may be handled by a different entity21. A concrete practical example in this direction is presented in Chapter 5. 3.5 PSEUDONYMS WITH PROOF OF OWNERSHIP As already discussed, pseudonymisation is a data protection technique which aims at protecting the identity of individuals by substituting their identifiers by pseudonyms. However, pseudonymisation may in certain cases interfere with the exercise of the rights that a data subject has on his/her data as defined in the GDPR (Articles 15 to 20) 22. For example, in cases where the data controller does not have access to original identifiers but only to pseudonyms23, then any request from a data subject to the data controller can be satisfied only if the data subject is able to prove that the pseudonym is related to his/her own identity; indeed, although the pseudonym is a type of an identifier in such a context, if its association with a specific data subject cannot be appropriately established, then the data controller cannot satisfy relevant data subject requests. Therefore, in the cases as described above, it may be useful to create pseudonyms with proof of ownership. Such pseudonymisation techniques do exist (Montenegro & Castelluccia, 2004). The solution described verifies that the pseudonyms are hiding and binding. A pseudonym P is created by a data subject from a given identifier ID and later transferred to a data controller (Figure 5). The data controller must not be able to recover any information from the pseudonym P (hiding property). This property is important to avoid exposing the personal data of the data subject. At the same time, it must not be possible to find another identifier ID’≠ ID that is 21 Again, as in the case of chaining, an appropriate joint controllership could be possibly established, assigning relevant responsibilities (vis-a-vis to the data processors). 22 Recalling the Article 11 of the GDPR, if the purposes for which a controller processes personal data do not require the identification of a data subject by the controller, the controller shall not be obliged to maintain, acquire or process additional information in order to identify the data subject. In such cases Articles 15 to 20 shall not apply, except where the data subject, for the purpose of exercising his or her rights under those Articles, provides additional information enabling his or her identification. 23 This may be a requirement from a data protection perspective – i.e. if the data controller does not need to process direct identification information for the purposes of processing. 21
You can also read

















































