This page describes how to use the Query insights dashboard to detect and analyze performance problems.
You can use Gemini in Databases assistance to help you observe and troubleshoot your Cloud SQL for MySQL resources. For more information, see Observe and troubleshoot with Gemini assistance.
Introduction
Query insights helps you detect, diagnose, and prevent query performance problems for Cloud SQL databases. It supports intuitive monitoring and provides diagnostic information that helps you go beyond detection to identify the root cause of performance problems.
With query insights, you can monitor performance at an application level and trace the source of a problematic query across the application stack by model, view, controller, route, user, and host. The query insights tool can integrate with your existing application monitoring (APM) tools and Google Cloud services by using open standards and APIs. This way, you can monitor and troubleshoot query problems by using your favorite tool.
Query insights helps you improve Cloud SQL query performance by guiding you through the following steps:
- View the database load for top queries
- Identify a potentially problematic query or tag
- Examine the query or tag to identify issues
- Trace the source of the problem
Query insights for Cloud SQL Enterprise Plus edition
If you're using Cloud SQL Enterprise Plus edition, then you can access additional capabilities in query insights to perform advanced query performance diagnostics. In addition to the standard capabilities of the Query insights dashboard, query insights for Cloud SQL Enterprise Plus edition lets you do the following:
- Filter aggregated database load by additional dimensions such as queries, tags, and more
- Capture query plans for all executed queries
- Sample up to 200 query plans per minute
- Capture longer query text up to 1 MB
- Obtain near real-time updates for metrics (in the order of seconds)
- Maintain a longer 30-day retention of metrics
The following table compares functional requirements and capabilities of query insights for Cloud SQL Enterprise edition with query insights for Cloud SQL Enterprise Plus edition.
| Comparison area | Query insights for Cloud SQL Enterprise edition | Query insights for Cloud SQL Enterprise Plus edition |
|---|---|---|
| Supported database versions | MySQL 5.7 or later | MySQL 8.0 or later |
| Supported machine types | Supported on all machine types | Not supported on instances that use a shared core machine type |
| Supported regions | Cloud SQL regional locations | Cloud SQL Enterprise Plus edition regional locations |
| Metrics retention period | 7 days | 30 days |
| Query length limit maximum | 4500 bytes | 1 MB |
| Query plan sample maximum | 20 | 200 |
To enable query insights for Cloud SQL Enterprise Plus edition during Preview for your Cloud SQL Enterprise Plus edition instance, follow the steps in Enable query insights for Cloud SQL Enterprise Plus edition.
Pricing
There's no additional cost for query insights. In addition, there's no cost for enabling query insights for Cloud SQL Enterprise Plus edition, which is in Preview.
Storage requirements
Query insights for Cloud SQL Enterprise edition doesn't occupy any storage space in your Cloud SQL instance storage space. Metrics are stored in Cloud Monitoring. For API requests, see Cloud Monitoring Pricing. Cloud Monitoring has a tier that you can use at no additional cost.
Query insights for Cloud SQL Enterprise Plus edition (Preview) stores metrics data on the same disk attached to your Cloud SQL instance and requires that you keep the automatic storage increases setting enabled.
The storage requirement for seven days worth of data is approximately 45 GB. For 30 days, you need approximately 180 GB. Query insights for Cloud SQL Enterprise Plus edition uses up to 130 MB of RAM. Metrics are expected to be available in query insights within one minute of query completion. Applicable storage fees apply.Before you begin
Before you use query insights, do the following.
- Add required roles and permissions.
- Enable the Cloud Trace API.
- If you're using Query insights for Cloud SQL Enterprise Plus edition, then make sure that Enable automatic storage increases is enabled for the instance.
Required roles and permissions
To use query insights, you need to grant roles with the required Identity and Access Management permissions or provide a user account with the required permissions.
For more information about granting roles, see Manage access.
To get the permissions that you need to access historical query execution data in the Query insights dashboard, ask your administrator to grant you the following IAM roles on the project that hosts the Cloud SQL instance:
-
Database Insights Monitoring Viewer (
roles/databaseinsights.monitoringViewer) -
Cloud SQL Viewer (
roles/cloudsql.viewer)
For more information about granting roles, see Manage access to projects, folders, and organizations.
These predefined roles contain the permissions required to access historical query execution data in the Query insights dashboard. To see the exact permissions that are required, expand the Required permissions section:
Required permissions
The following permissions are required to access historical query execution data in the Query insights dashboard:
-
databaseinsights.aggregatedStats.query -
databaseinsights.timeSeries.query
You might also be able to get these permissions with custom roles or other predefined roles.
For example, in Database Insights, you can ask your administrator to grant you the Database Insights Viewer (roles/databaseinsights.viewer) predefined
role. Then, in Cloud SQL, you can ask your administrator to grant you one of the following predefined roles:
- Cloud SQL Editor (
roles/cloudsql.editor) - Cloud SQL Admin (
roles/cloudsql.admin)
Enable the Trace API
To view query plans and their end-to-end views, your Google Cloud project must have the Trace API enabled. This setting lets your Google Cloud project receive trace data from authenticated sources at no additional cost. This data can help you detect and diagnose performance issues in your instance.
To confirm that the Trace API is enabled, follow these steps:
- From the Google Cloud console, go to APIs and Services:
- Click Enable APIs and Services.
- In the search bar, enter
Trace API. - If API enabled is displayed, then this API is enabled and there's nothing for you to do. Otherwise, click Enable.
Enable automatic storage increases
If you're using Query insights for Cloud SQL Enterprise Plus edition (Preview), then make sure that the instance setting to enable automatic storage increases remains enabled. By default, this option is enabled for Cloud SQL instances.If you previously disabled this instance setting and want to enable Query insights for Cloud SQL Enterprise Plus edition, then re-enable automatic storage increases first. You can't turn off automatic storage increases and enable Query insights for Cloud SQL Enterprise Plus edition.
Enable query insights
Users who have access to the Cloud SQL dashboard can access query insights metrics. If you have permission to update instances, then you can enable query insights. For a list of permissions required for Cloud SQL instances, see Cloud SQL project access control. If you don't have these permissions and you want to enable query insights on your instances, then contact your administrator.
Console
Enable query insights for an instance
-
In the Google Cloud console, go to the Cloud SQL Instances page.
- To open the Overview page of an instance, click the instance name.
- On the Configuration tile, click Edit configuration.
- In the Customize your instance section, expand Query insights.
- Select the Enable Query insights checkbox.
- Optional. Select one or more of the following query insights additional features:
- Click Save.
Active query analysis
Default: false
Lets you review details about your actively running queries and if necessary, terminate long-running queries. For more information, see Monitor active queries. This feature is in Preview.
Enable index advisor
Default: false
Index advisor provides index recommendations to speed up query processing. When you enable index advisor, your instance requires a restart. For more information, see Index advisor overview and Use index advisor. This feature is in Preview.
Store client IP addresses
Default: false
Stores the client IP addresses where queries are coming from and helps you group that data to run metrics against it. Queries come from more than one host. Reviewing graphs for queries from client IP addresses can help identify the source of a problem.
Store application tags
Default: false
Stores application tags that help you determine the APIs and model-view-controller (MVC) routes that are making requests and group the data to run metrics against it. This option requires you to comment queries with a specific set of tags using the sqlcommenter open source object-relational mapping (ORM) auto-instrumentation library. This information helps query insights identify the source of a problem and the MVC from which the problem is coming. Application paths help you with application monitoring.
Customize query lengths
Default: 1024
Sets the query length limit to a specified value from 256 bytes to 4500 bytes. Higher query lengths are more useful for analytical queries, but they also require more memory. Changing the query length requires you to restart the instance. You can still add tags to queries that exceed the length limit.
Set the maximum sampling rate
Default: 5
Sets the maximum sampling rate. Sampling rate is the number of executed query plan samples that are captured per minute across all databases on the instance. Change this value to a number from 0 (setting this value to 0 disables sampling) to 20. Increasing the sampling rate is likely to give you more data points but might increase performance overhead.
Enable query insights for multiple instances
-
In the Google Cloud console, go to the Cloud SQL Instances page.
- Click the More Actions menu on any row.
- Select Enable Query insights.
- In the dialog, select the Enable Query insights for multiple instances checkbox.
- Click Enable.
- In the subsequent dialog, select the instances for which you want to enable query insights.
- Click Enable Query insights.
gcloud
To enable query insights for a Cloud SQL instance by using
gcloud, run gcloud sql instances patch
with the --insights-config-query-insights-enabled flag as
follows after replacing INSTANCE_ID with the ID of the instance.
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled
Also, use one or more of the following optional flags:
--insights-config-record-client-addressStores the client IP addresses where queries are coming from and helps you group that data to run metrics against it. Queries come from more than one host. Reviewing graphs for queries from client IP addresses can help identify the source of a problem.
--insights-config-record-application-tagsStores application tags that help you determine the APIs and model-view-controller (MVC) routes that are making requests and group the data to run metrics against it. This option requires you to comment queries with a specific set of tags. You can do this by using the sqlcommenter open source object-relational mapping (ORM) auto-instrumentation library. This information helps Query Insights identify the source of a problem and the MVC the problem is coming from. Application paths help you with application monitoring.
--insights-config-query-string-lengthSets the default query length limit to a specified value from 256 to 4500 bytes. The default query length is 1024 bytes. Higher query lengths are more useful for analytical queries, but they also require more memory. Changing the query length requires you to restart the instance. You can still add tags to queries that exceed the length limit.
--query_plans_per_minuteBy default, a maximum of 5 executed query plan samples are captured per minute across all databases on the instance. Change this value to a number from 0 (setting this value to 0 disables sampling) to 20. Increasing the sampling rate is likely to give you more data points but might add a performance overhead.
Replace the following:
- INSIGHTS_CONFIG_QUERY_STRING_LENGTH: The query string length to be stored, in bytes.
- API_TIER_STRING: The custom instance configuration to use for the instance.
- REGION: The region for the instance.
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled \ --insights-config-query-string-length=INSIGHTS_CONFIG_QUERY_STRING_LENGTH \ --query_plans_per_minute=QUERY_PLANS_PER_MINUTE \ --insights-config-record-application-tags \ --insights-config-record-client-address \ --tier=API_TIER_STRING \ --region=REGION
REST v1
To enable query insights for a Cloud SQL instance by using the
REST API, call the instances.patch
method with insightsConfig settings.
Before using any of the request data, make the following replacements:
- project-id: The project ID.
- instance-id: The instance ID.
HTTP method and URL:
PATCH https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id
Request JSON body:
{
"settings" : { "insightsConfig" : { "queryInsightsEnabled" : true } }
}
To send your request, expand one of these options:
You should receive a JSON response similar to the following:
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id",
"status": "PENDING",
"user": "[email protected]",
"insertTime": "2021-01-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "operation-id",
"targetId": "instance-id",
"selfLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/operations/operation-id",
"targetProject": "project-id"
}
Terraform
To use Terraform to enable query insights for a Cloud SQL instance,
set the query_insights_enabled flag to true.
Also, you can use one or more of the following optional flags:
-
query_string_length: Default is1024and you can configure it to a value between256and4500in bytes. -
record_application_tags: Set the value totrueif you want to record application tags from the query. -
record_client_address: Set the value totrueif you want to record the client IP address. -
query_plans_per_minute: Default is5and you can configure it to a value between5and20.
Here's an example:
resource "google_sql_database_instance" "INSTANCE_NAME" { name = "INSTANCE_NAME" database_version = "MYSQL_VERSION" region = "REGION" root_password = "PASSWORD" deletion_protection = false # set to true to prevent destruction of the resource settings { tier = "DB_TIER" insights_config { query_insights_enabled = true query_string_length = 2048 # Optional record_application_tags = true # Optional record_client_address = true # Optional query_plans_per_minute = 10 # Optional } } }
To apply your Terraform configuration in a Google Cloud project, complete the steps in the following sections.
Prepare Cloud Shell
- Launch Cloud Shell.
-
Set the default Google Cloud project where you want to apply your Terraform configurations.
You only need to run this command once per project, and you can run it in any directory.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Environment variables are overridden if you set explicit values in the Terraform configuration file.
Prepare the directory
Each Terraform configuration file must have its own directory (also called a root module).
-
In Cloud Shell, create a directory and a new
file within that directory. The filename must have the
.tfextension—for examplemain.tf. In this tutorial, the file is referred to asmain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
If you are following a tutorial, you can copy the sample code in each section or step.
Copy the sample code into the newly created
main.tf.Optionally, copy the code from GitHub. This is recommended when the Terraform snippet is part of an end-to-end solution.
- Review and modify the sample parameters to apply to your environment.
- Save your changes.
-
Initialize Terraform. You only need to do this once per directory.
terraform init
Optionally, to use the latest Google provider version, include the
-upgradeoption:terraform init -upgrade
Apply the changes
-
Review the configuration and verify that the resources that Terraform is going to create or
update match your expectations:
terraform plan
Make corrections to the configuration as necessary.
-
Apply the Terraform configuration by running the following command and entering
yesat the prompt:terraform apply
Wait until Terraform displays the "Apply complete!" message.
- Open your Google Cloud project to view the results. In the Google Cloud console, navigate to your resources in the UI to make sure that Terraform has created or updated them.
Metrics are expected to be available in query insights within minutes of query completion. Review the Cloud Monitoring data retention policy.
Query insights traces are stored in Cloud Trace. Review the Cloud Trace data retention policy.
Enable query insights for Cloud SQL Enterprise Plus edition
You can enable query insights for Cloud SQL Enterprise Plus edition on your Cloud SQL instance only by using the Google Cloud console.
-
In the Google Cloud console, go to the Cloud SQL Instances page.
- To open the Overview page of an instance, click the instance name.
- Click Edit.
- In the Storage section, verify that Enable automatic storage increases checkbox is selected.
- In the Customize your instance section, expand Query insights.
- Select the Enable Enterprise Plus features checkbox.
After you enable query insights for Cloud SQL Enterprise Plus edition, you can update the following fields:
Customize query lengths: specify the limit, in bytes, of the query length. You can specify a number from
1to1048576. Any query string that goes above the specified limit becomes truncated in the display. A higher query length limit requires more memory. The default value is1024bytes (1 KB).Set the maximum sampling rate: you can set the maximum query sampling rate depending on your database load. By default, the maximum sampling rate is set to 5 query plan samples per minute across all databases on the instance. You can increase the maximum to 200 to provide more data points; however, increasing the number might also increase database load.
Click Save.
View the Query insights dashboard
The Query insights dashboard shows the query load based on factors that you select. Query load is a measurement of the total work for all the queries in the instance in the selected time range. The dashboard provides a series of filters that help you view query load.
To open the Query insights dashboard, follow these steps:
- To open the Overview page of an instance, click the instance name.
- Either select the Query insights tab in the left navigation panel or click the Go to Query insights for more in-depth info on queries and performance link.
The Query insights dashboard opens. It shows the following information about your instance:
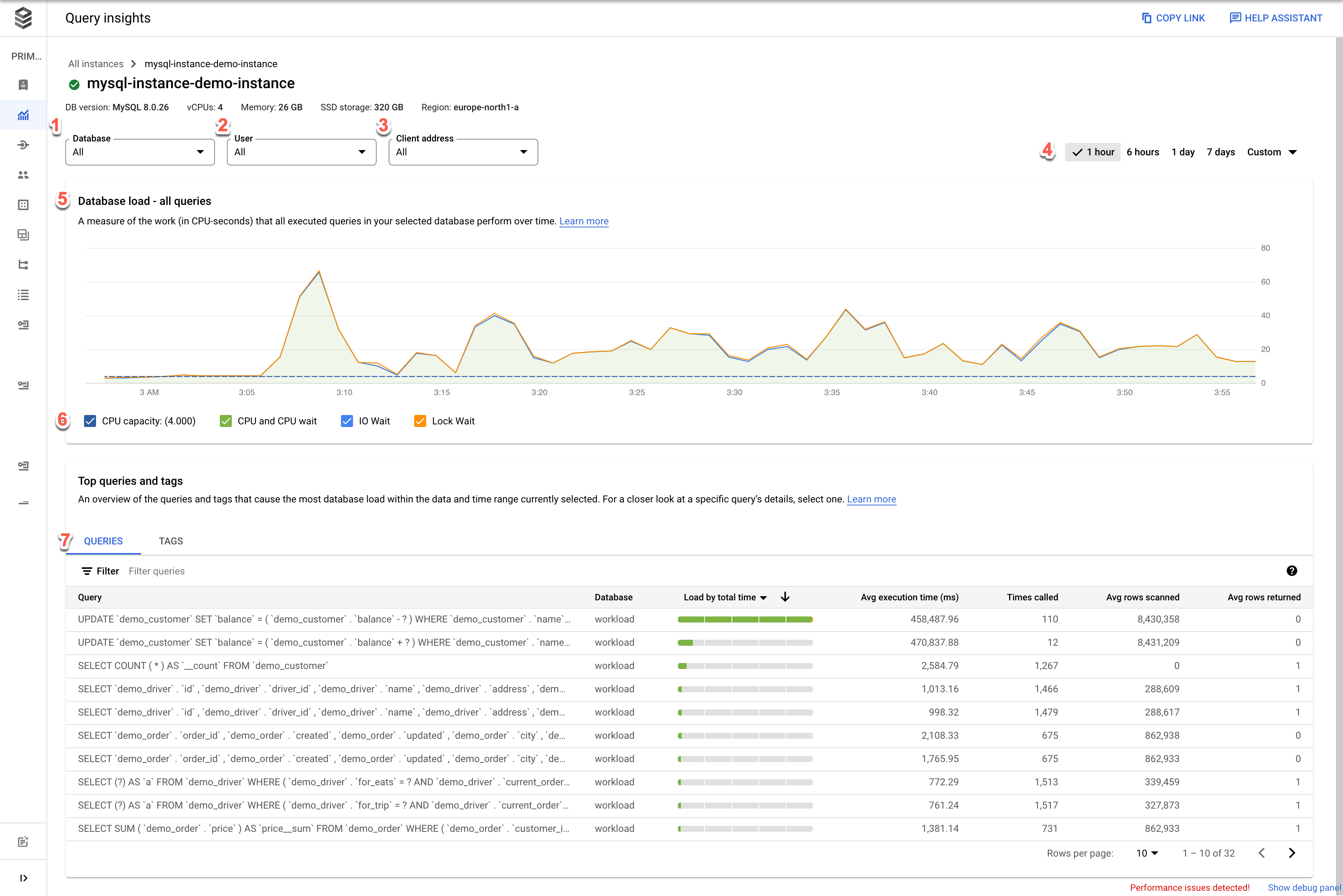
- Databases: Filters query load on a specific database or all databases.
- User: Filters query load from a specific user account.
- Client address: Filters query load from a specific IP address.
- Time range: Filters query load by time ranges, such as 1 hour, 6 hours, 1 day, 7 days, 30 days, or a custom range.
- Database load graph: Displays the query load graph, based on filtered data.
- CPU capacity, CPU and CPU wait, IO wait, and Lock wait: Filters loads based on the options that you select. See View the database load for top queries for details about each of these filters.
- Queries and Tags: Filters query load by either a selected query or a selected SQL query tag. See Filter the database load.
View the database load for all queries
Database query load is a measure of the work (in CPU seconds) that the executed queries in your selected database perform over time. Each running query is either using or waiting for CPU resources, IO resources, or lock resources. Database query load is the ratio of the amount of time taken by all the queries that are completed in a given time window to the wall-clock time.
The top-level query insights dashboard shows the Database load — all top queries graph. Drop-down menus on the dashboard let you filter the graph for a specific database, user, or client address.
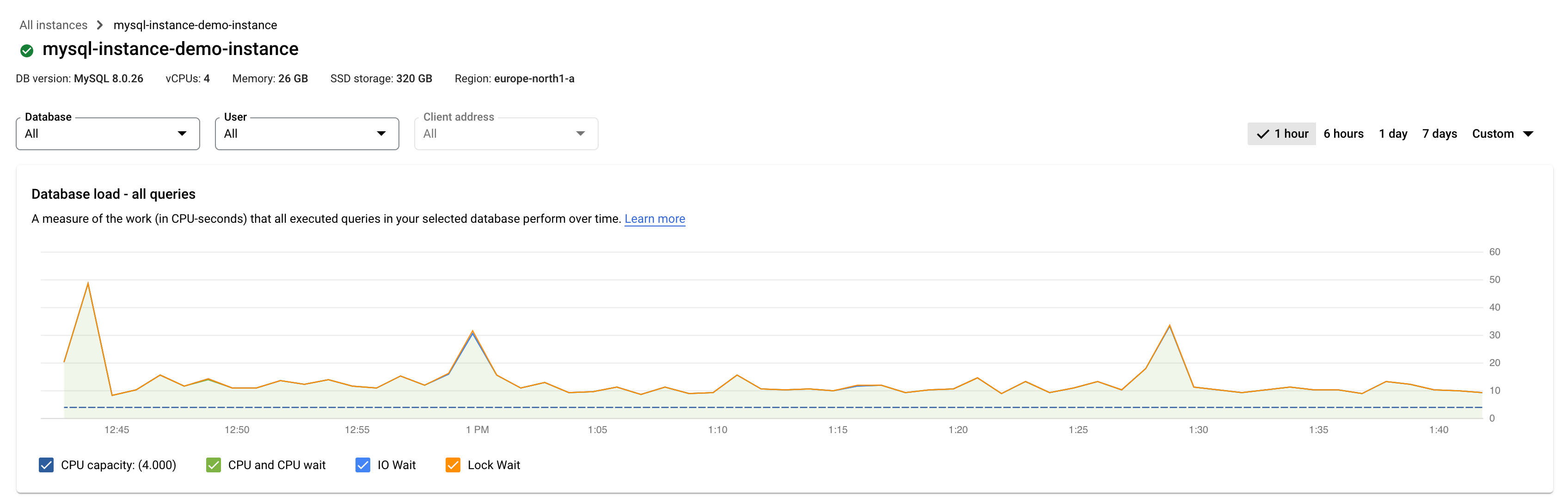
Colored lines in the graph show the query load, split into categories:
- CPU capacity: The number of CPUs available on the instance.
- CPU and CPU Wait: The ratio of the time taken by queries in an active state to wall-clock time. IO and Lock waits don't block queries that are in an active state. This metric might mean that the query is either using the CPU or waiting for the Linux scheduler to schedule the server process running the query while other processes are using the CPU.
- IO Wait: The ratio of time taken by queries that are waiting for IO to wall-clock time. IO wait includes Read IO Wait and Write IO Wait. If you want a breakdown of information for IO waits, you can see it in Cloud Monitoring. See Cloud SQL metrics for more information.
- Lock Wait: The ratio of time taken by queries that are waiting for Locks to wall-clock time. It includes Lock Waits, LwLock Waits, and Buffer pin Lock waits. To see a breakdown of information for lock waits, use Cloud Monitoring. See Cloud SQL metrics for more information.
Colored lines in the graph show per database load by execution time. Review the graph and use the filtering options to explore these questions:
- Is the query load high? Is the graph spiking or elevated over time? If you don't see a high load, then the problem isn't with your query.
- How long has the load been high? Is it high only now or has it been high for a long time? Use the range selector to select various time periods to find out how long the problem has lasted. Zoom in to view a time window where query load spikes are observed. Zoom out to view up to one week of the timeline.
- What's causing the high load? You can select options to examine the CPU capacity, CPU and CPU wait, Lock wait, or IO wait. The graph for each of these options is a different color so that you can spot the one with the highest load. The dark blue line on the graph shows the maximum CPU capacity of the system. It lets you compare the query load with the maximum CPU system capacity. This comparison helps you determine whether an instance is running out of CPU resources.
- Which database is experiencing the load? Select different databases from the Databases drop-down menu to find the databases with the highest loads.
- Do specific users or IP addresses cause higher loads? Select different users and addresses from the drop-down menus to identify the ones that are causing higher loads.
Filter the database load
You can filter the database load by queries or tags. If you're using query insights for Cloud SQL Enterprise Plus edition, then you can customize the database load chart to break down the displayed data using any of the following dimensions:- All queries
Databases
Users
Tags
Client addresses
To customize the database load chart, select a dimension from the Database Load by execution time drop-down.
View the top contributors to database load
To view the top contributors to the database load, you can use the Top dimensions by database load table. The Top dimensions by database load table displays the top contributors for the time period and dimension that you select in the Database Load by execution time chart drop-down. You can modify the time period or dimension to view the top contributors for a different dimension or time period.
In the Top dimensions by data load table, you can select the following tabs.
| Tab | Description |
|---|---|
| Queries | The table displays the top normalized queries by total execution time.
For each query, the data shown in columns are listed as follows:
|
| Databases | The table shows the list of top databases that contributed to the
load during the chosen time period across all executed queries.
|
| Users | The table shows the list of top users for the selected time period
across all executed queries.
|
| Tags | For information about tags, Filter by query tags. |
| Client addresses | The table shows the list of top users for the selected time period
across all executed queries.
|
Filter by queries
The Queries table provides an overview of the queries that cause the most query load. The table shows all the normalized queries for the time window and options selected on the Query insights dashboard. It sorts queries by the total execution time during the time window that you selected.
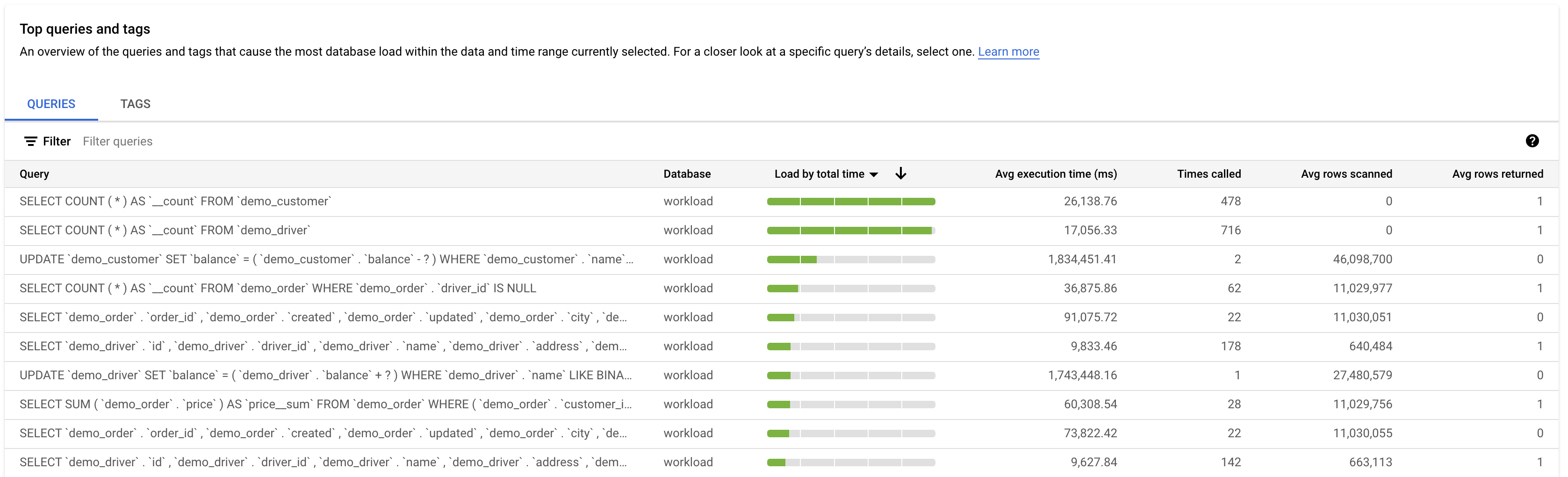
To sort the table, select a column heading or a property from Filter queries. The table shows the following properties:
- Query: the normalized query string. By default, Query insights shows only
1024 characters in the query string.
Queries labeled
UTILITY COMMANDusually includeBEGIN,COMMIT, andEXPLAINcommands or wrapper commands. - Database: the database against which the query was run.
- Load by total time/Load by CPU/Load by IO wait/Load by lock wait: The options by which you can filter specific queries to find the largest load.
- % load by queries: The percentage load by individual query.
- Avg execution time (ms): The average time for the query to execute.
- Times called: the number of times the application called the query.
- Avg rows returned: the average number of rows returned for the query.
- Avg rows scanned: the average number of rows scanned for the query.
Query insights stores and displays only normalized queries.
By default, query insights doesn't collect IP addresses or tag information. You can enable query insights to collect this information and, when required, disable collection.
Query plan traces don't collect or store any constant values and removes any PII information that the constant might show.
Query insights displays normalized queries, that is, ? replaces
the literal constant value. In the following example, the name constant is
removed and ? replaces it.
UPDATE "demo_customer" SET "customer_id" = ?::uuid, "name" = ?, "address" = ?, "rating" = ?, "balance" = ?, "current_city" = ?, "current_location" = ? WHERE "demo_customer"."id" = ?
Filter by query tags
To troubleshoot an application, you must first add tags to your SQL queries. Query load tags provide a breakdown of the query load of the selected tag over time.
Query insights provides application-centric monitoring to diagnose performance problems for applications built using ORMs. If you're responsible for the entire application stack, query insights provides query monitoring from an application view. Query tagging helps you find issues at higher-level constructs, such as with the business logic or a microservice.
You might tag queries by the business logic, for example, the payment, inventory, business analytics, or shipping tags. You can then find the query load that the various business logic create. For example, you might observe unexpected events, such as spikes for a business analytics tag at 1 PM or unexpected growth for a payment service trending over the previous week.
To calculate the Database load for tag, query insights uses the amount of time taken by every query that uses the tag that you select. The tool calculates the completion time at the minute boundary by using wall-clock time.
On the query insights dashboard, to view the tags table, select Tags. The table sorts tags by their total load by total time.

You can sort the table by selecting a property from Filter tags, or by clicking a column heading. The table shows the following properties:
- Action, Controller, Framework, Route, Application, DB driver: Each property that you added to your queries appears as a column. At least one of these properties must be added if you want to filter by tags.
- Load by total time/Load by CPU/Load by IO wait/Load by lock wait: Options to filter specific queries to find the largest load for each option.
- Avg execution time (ms): The average time for the query to run.
- Avg rows returned: The average number of rows returned for the query.
- Avg rows scanned: The average number of rows scanned for the query.
- Times called: The number of times the application called the query.
- Database: The database against which the query was run.
Examine a specific query or tag
To determine whether a query or a tag is the root cause of the problem, do the following from the Queries tab or Tags tab, respectively:
- To sort the list in descending order, click the Load by total time header.
- Click the query or tag at the top of the list. It has the highest load and is taking more time than the others.
A dashboard opens showing the details of the selected query or tag.
Examine a specific query load
The dashboard for a selected query appears as follows:
The Database load — specific query graph shows a measure of the work (in CPU seconds) that your normalized query has performed in your selected query over time. To calculate load, it uses the amount of time taken by the normalized queries that are completed at the minute boundary to the wall-clock time. At the top of the table, the first 1024 characters of the normalized query, with literals removed for aggregation and PII reasons, are displayed.
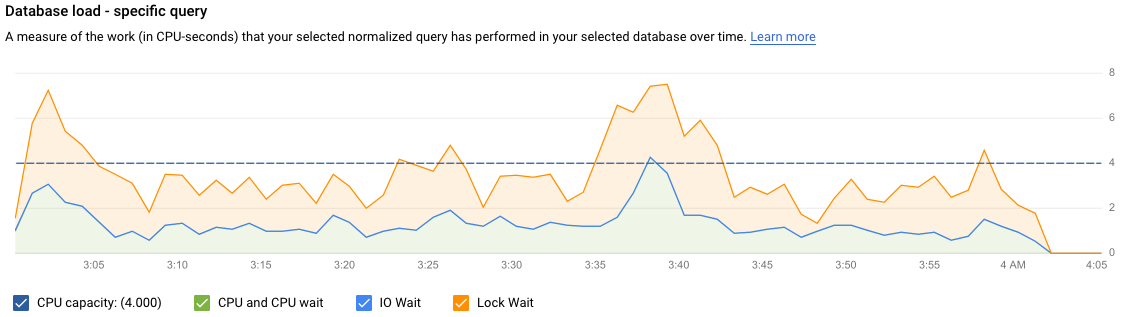
As with the total queries graph, you can filter the load for a specific query by Database, User, and Client address. Query load is split into CPU capacity, CPU and CPU wait, IO wait, and Lock wait.
Examine a specific tagged query load
The dashboard for a selected tag appears as follows. For example, if all
queries from a microservices payment are tagged as payment, you can
see the amount of query load that's trending by viewing the tag payment.
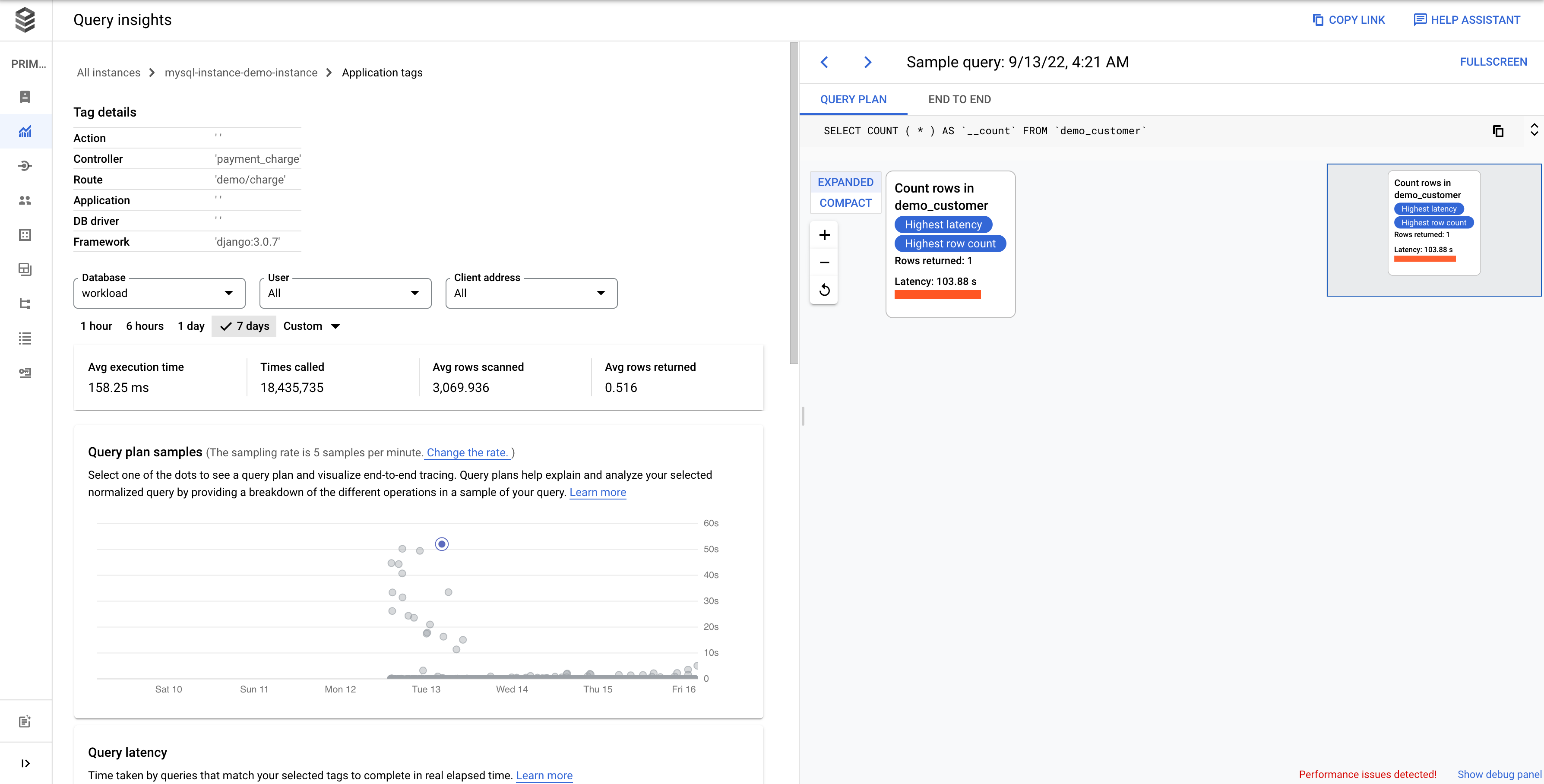
The Database load — specific tags graph shows a measure of the work (in CPU seconds) that queries matching your selected tags have performed in your selected database over time. As with the total queries graph, you can filter the load for a specific tag by Database, User, and Client address.
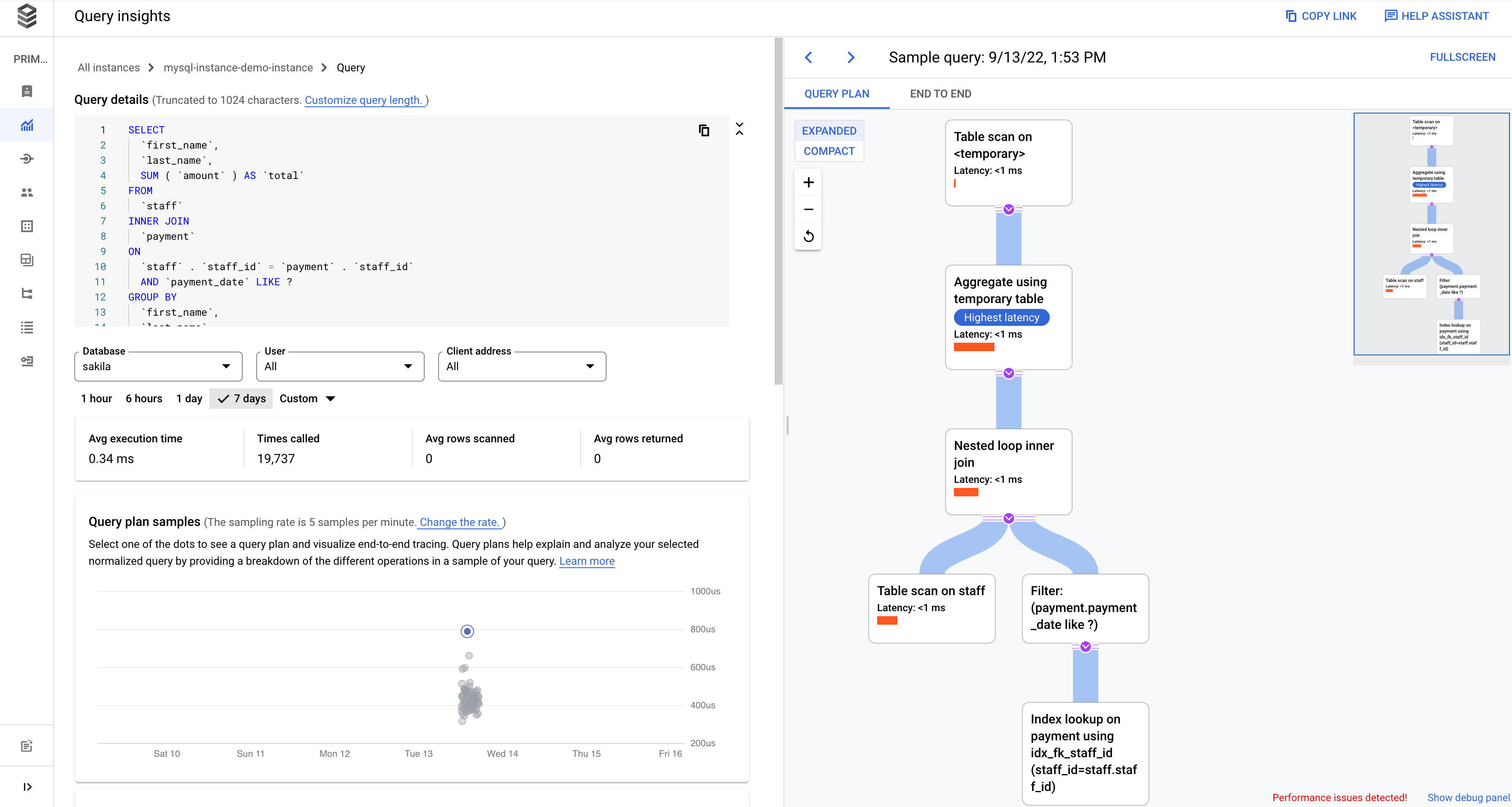
Examine operations in a sampled query plan
A query plan takes a sample of your query and breaks it down into individual operations. It explains and analyzes each operation in the query.
MySQL 5.7 provides an estimated query plan with the EXPLAIN view whereas MySQL 8.0 and later versions provide an executed query plan with the EXPLAIN ANALYZE view. An estimated query plan gives the estimated execution time of a query whereas an executed query plan provides real-time information of each execution step of a given query.
Query plans in MySQL 5.7 are supported for the following queries that are supported by the EXPLAIN statement:
- For single tables: INSERT, SELECT, UPDATE, and DELETE.
- For multiple tables: SELECT, UPDATE, and DELETE.
You can generate query plans in MySQL 8.0 and later for all queries supported by EXPLAIN ANALYZE. This tool shows you where MySQL spends time on your SELECT queries for single tables and multiple tables. Cloud SQL doesn't support the generation of multi-table Data Manipulation Language (DML) query plans because these queries aren't supported by EXPLAIN ANALYZE.
The Sample Query Plan provides an EXPLAIN ANALYZE view for the query plan samples that are related to the normalized query. These are executed query plans that provide a breakdown of the active time taken by each operation in the query plan.
The Query plan samples graph shows all the query plans running at particular times and the amount of time each plan took to run. You can change the rate at which query plan samples are captured per minute. See Enable Query Insights.
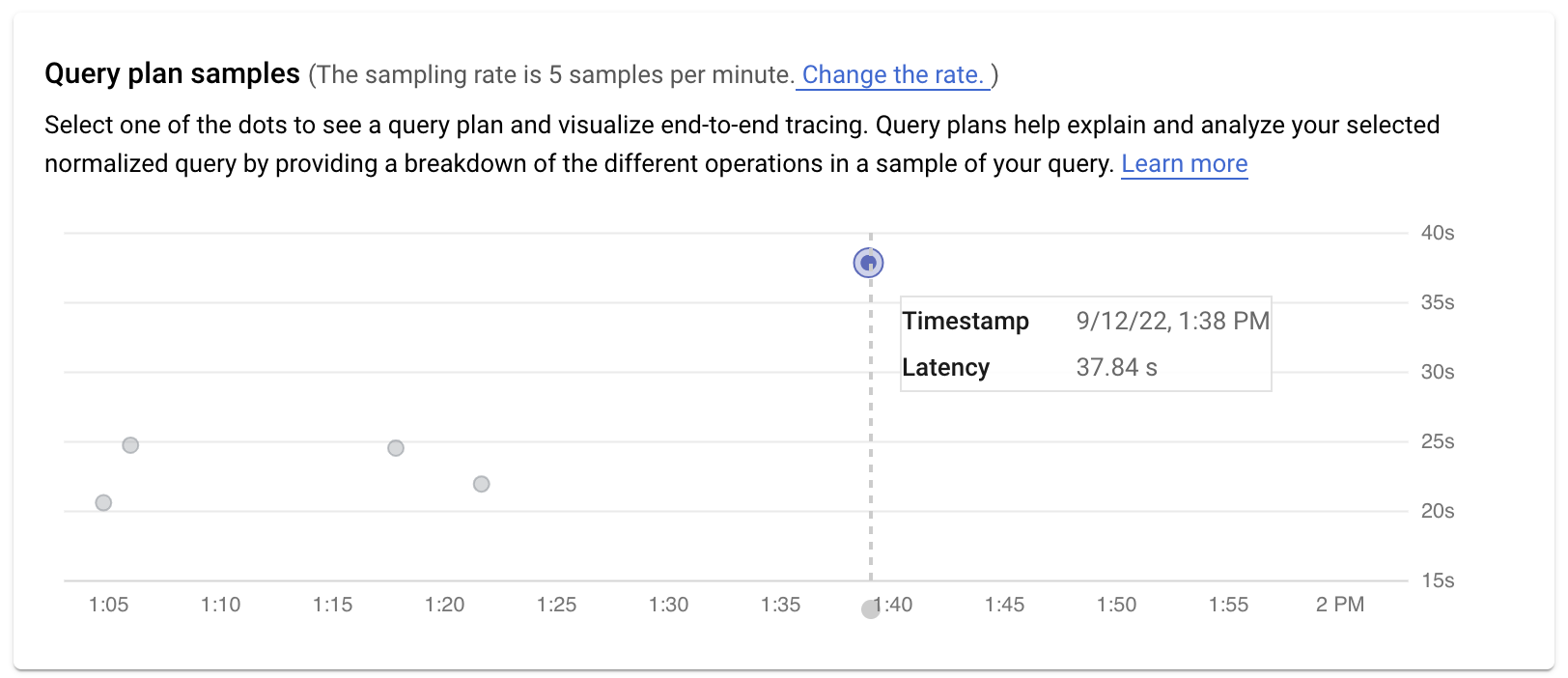
By default, the panel on the right shows the details for the sample query plan that takes the longest time, as visible on the Query plan samples graph. To see the details for another sample query plan, click the relevant circle on the graph. Expanded details show a model of all the operations in the query plan. Each operation shows the latency, rows returned, and the cost of the operation. When you select an operation, you can see more details, such as shared hit blocks, the type of schema, loops, and plan rows.
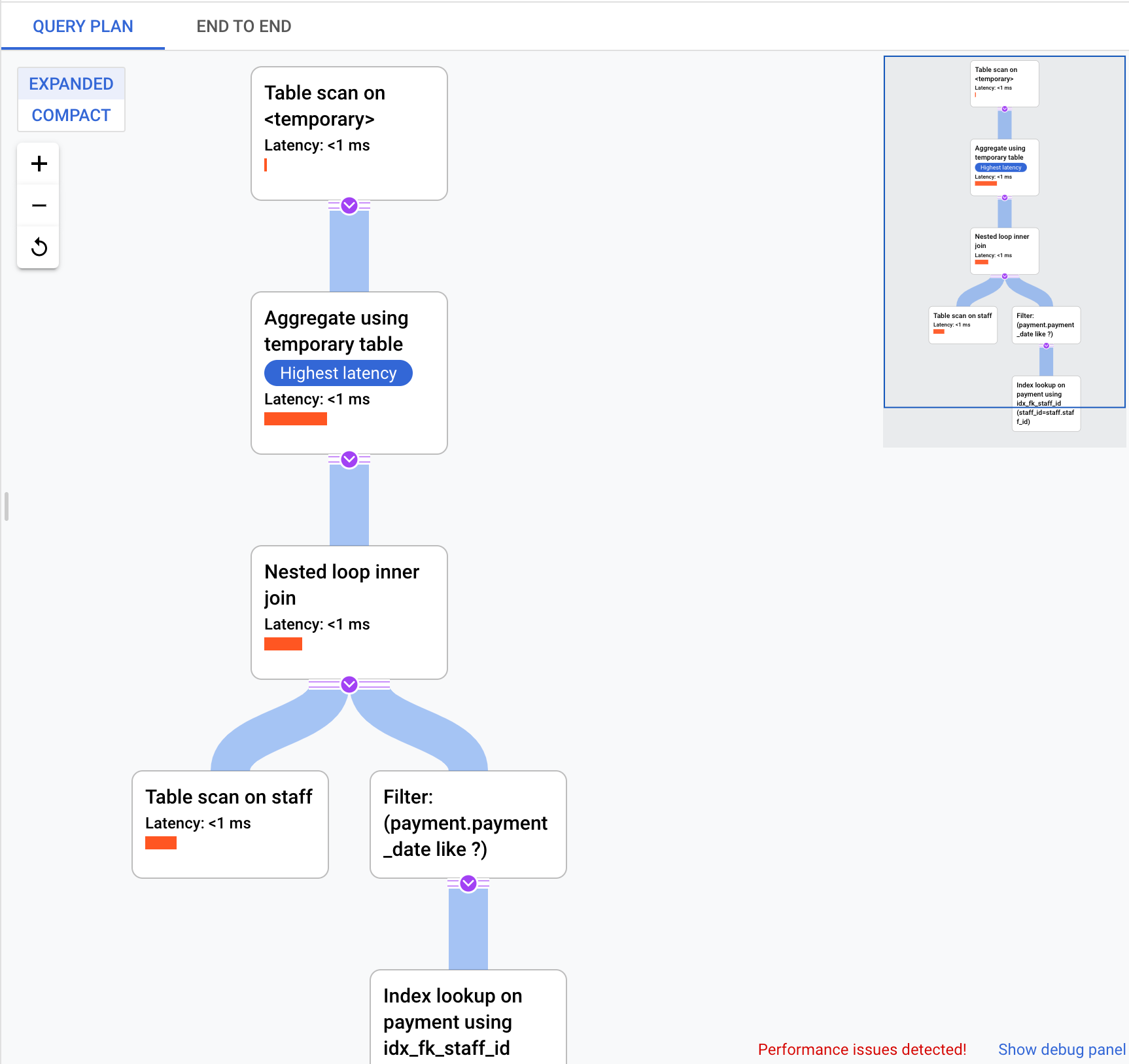
Try to narrow down the problem by looking into the following questions:
- What's the resource consumption?
- How does it relate to other queries?
- Does consumption change over time?
Examine latency
Latency is the time taken for the normalized query to complete, in wall-clock time. You use the Latency graph to examine latency on the query or tag. The latency dashboard shows the 50th, 95th, and 99th percentile latencies to find outlier behaviors.
The following image shows the database load graph at the 50th percentile for a specific query with filters selected for CPU capacity, CPU and CPU wait, IO wait, and Lock wait.
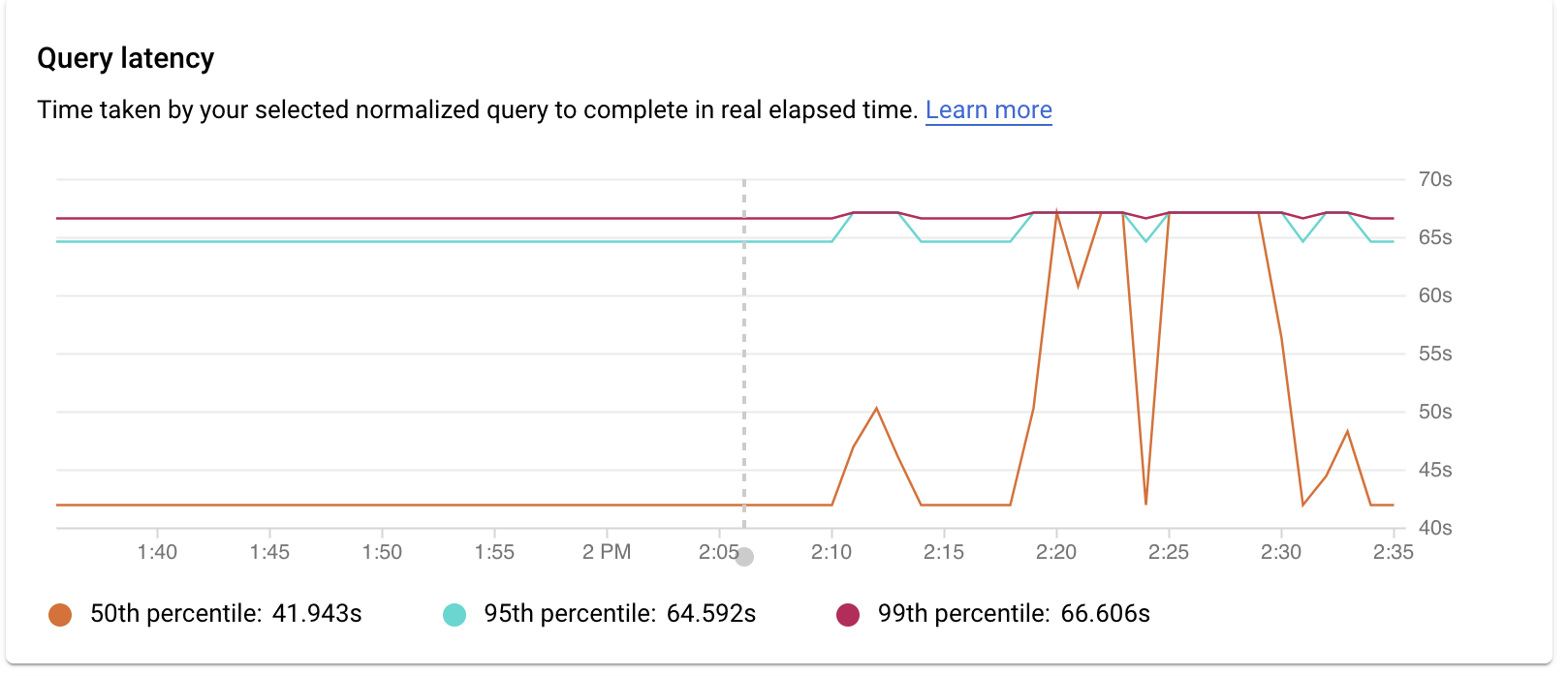
The latency of parallel queries is measured in wall-clock time even though the query load can be higher for the query due to multiple cores being used to run part of the query.
Try to narrow down the problem by looking into the following questions:
- What's causing the high load? Select options to look at the CPU capacity, CPU and CPU wait, I/O wait, or Lock wait.
- How long has the load been high? Is it only high now? Or has it been high for a long time? Change the time range to find the date and time that the load started performing poorly.
- Were there spikes in latency? Change the time window to study the historical latency for the normalized query.
Trace the source of the problem
When you find the areas and times where the load was the highest, identify the source of the problem by using tracing to drill down further.
To help you identify the specific source of the problem, such as a model, view, controller, route, host, or user, query insights provides an in-context end-to-end application trace view. This view helps you understand what's going on at the Database Layer for a specific request and to find the source of a problematic query by model, view, controllers, and route.
If you enable OpenCensus or OpenTelemetry, opencensus span information is sent to the database along with the tag information inside SQL comments. Any traces from the application to Cloud Logging are linked with database query plan traces to help identify the source of the problem.
Click the End to end tab in the Sample Query screen to look at the in-context trace.
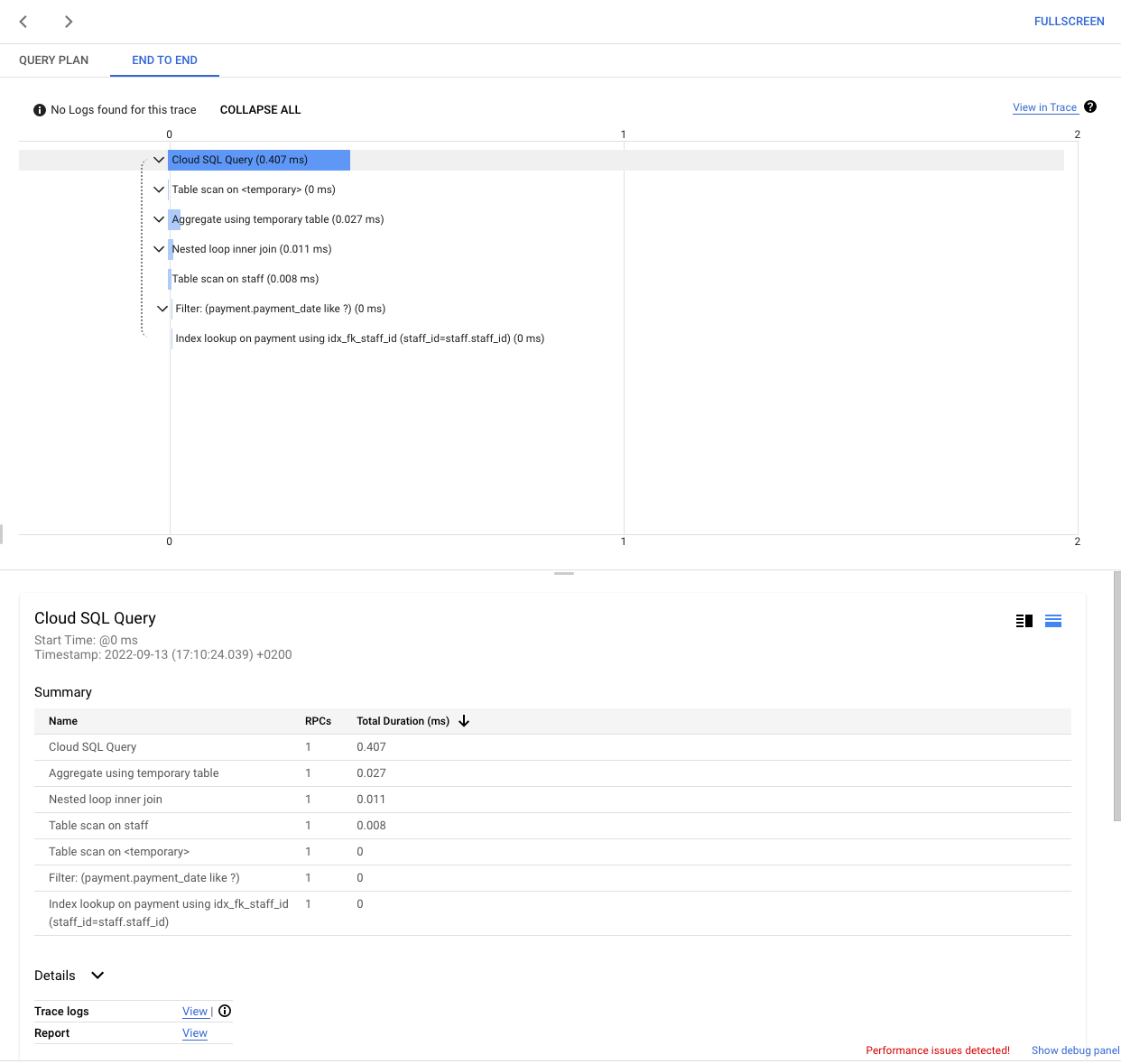
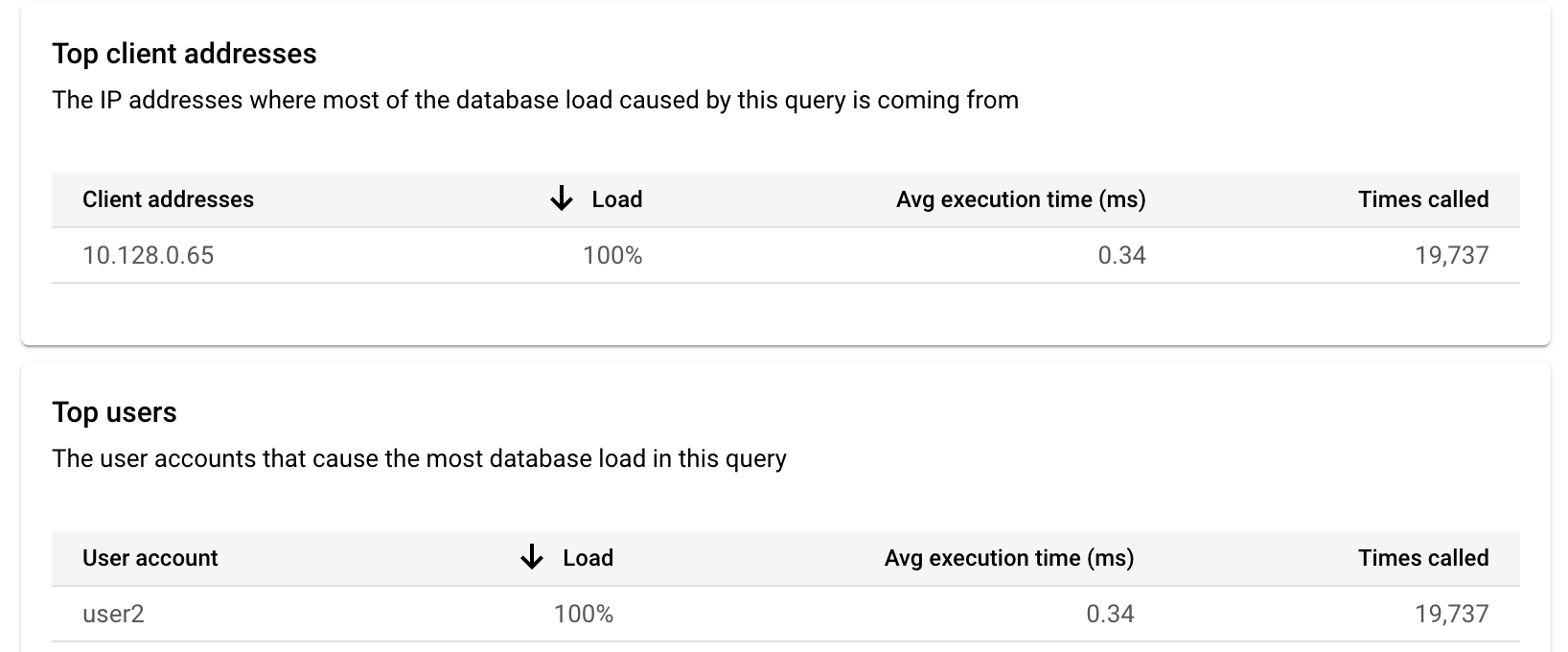
To determine the client and user causing the problem, use the Top client addresses and Top users tables to find the highest loads. You can add a user or IP address to the filter to further analyze a specific user or client address. The details in the tables include the percentage of the query load, the average execution time in milliseconds, and the times called.
You can use Cloud Trace to see end-to-end tracing for each step in the query plan. On the query insights dashboard, click the View in trace link to open the Cloud Trace tool. The trace graph shows all the traces that have been run for the selected period.
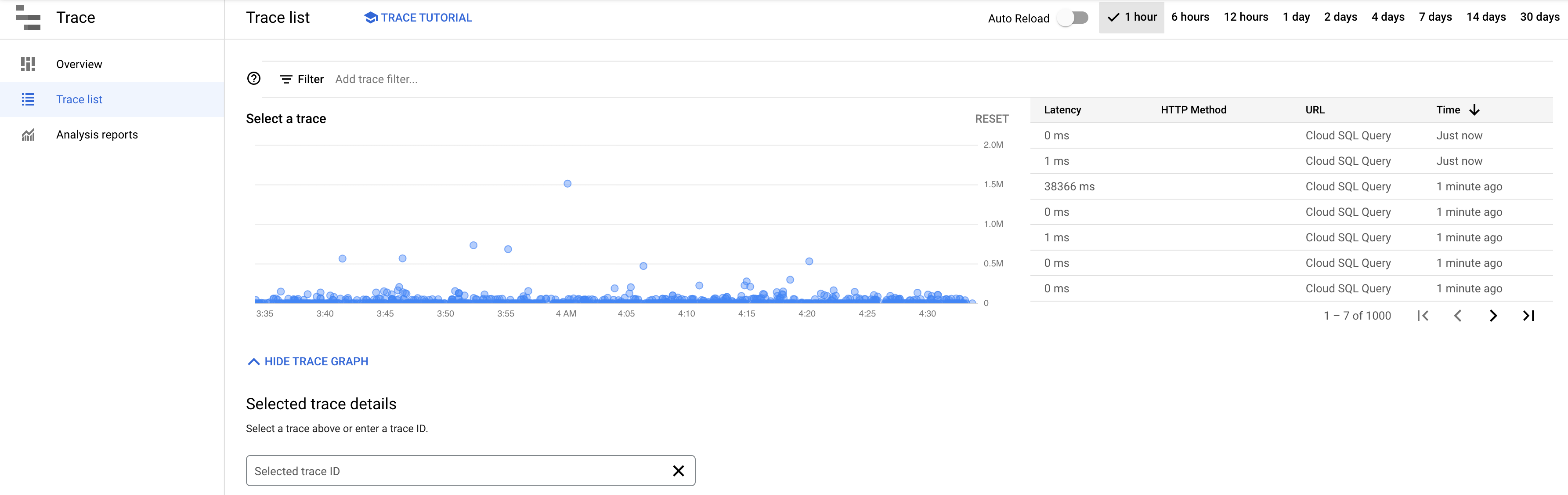
For details, see Finding and viewing traces.
Add tags to SQL queries
Tagging SQL queries simplifies application troubleshooting. You can use sqlcommenter to add tags to your SQL queries either automatically or manually.
Use sqlcommenter with ORM
When you use ORM instead of directly writing SQL queries, you might not find application code that's causing performance challenges. You might also have trouble analyzing how your application code affects query performance. To tackle this issue, Query Insights provides an open source library called sqlcommenter. This library is useful for developers and administrators using ORM tools to detect which application code is causing performance problems.
If you're using ORM and sqlcommenter together, the tags are automatically created. You don't need to add or change code in your application.
You can install sqlcommenter on the application server. The instrumentation library allows application information related to your MVC framework to be propagated to the database along with the queries as a SQL comment. The database picks up these tags and starts recording and aggregating statistics by tags, which are orthogonal to statistics aggregated by normalized queries. Query insights shows the tags so that you know which application is causing the query load and can find the application code that's causing performance problems.
When you examine results in SQL database logs, they appear as follows:
SELECT * from USERS /action='run+this', controller='foo%3', traceparent='00-01', tracestate='rojo%2'/
Supported tags include the controller name, route, framework, and action.
The set of ORM tools in sqlcommenter is supported for the following programming languages:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
For more information about sqlcommenter and how to use it in your ORM framework, see the sqlcommenter documentation.
Use sqlcommenter to add tags
If you're not using ORM, you must manually add sqlcommenter tags or comments in the correct SQL comment format to your SQL query. You must also augment each SQL statement with a comment containing a serialized key-value pair. Use at least one of the following keys:
action=''controller=''framework=''route=''application=''db driver=''
Query insights drops all other keys.
Disable query insights
Console
To disable query insights for a Cloud SQL instance by using the Google Cloud console, follow these steps:
-
In the Google Cloud console, go to the Cloud SQL Instances page.
- To open the Overview page of an instance, click the instance name.
- On the Configuration tile, click Edit configuration.
- In the Configuration options section, expand Query insights.
- Clear the Enable Query insights checkbox.
- Click Save.
gcloud
To disable query insights for a Cloud SQL instance by using gcloud,
run gcloud sql instances patch
with the --no-insights-config-query-insights-enabled flag as
follows, after replacing INSTANCE_ID with the ID of the instance.
gcloud sql instances patch INSTANCE_ID
--no-insights-config-query-insights-enabled
REST
To disable query insights for a Cloud SQL instance by using the
REST API, call the instances.patch
method with queryInsightsEnabled set to false as follows.
Before using any of the request data, make the following replacements:
- project-id: The project ID.
- instance-id: The instance ID.
HTTP method and URL:
PATCH https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id
Request JSON body:
{
"settings" : { "insightsConfig" : { "queryInsightsEnabled" : false } }
}
To send your request, expand one of these options:
You should receive a JSON response similar to the following:
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id",
"status": "PENDING",
"user": "[email protected]",
"insertTime": "2021-01-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "operation-id",
"targetId": "instance-id",
"selfLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/operations/operation-id",
"targetProject": "project-id"
}
Disable query insights for Cloud SQL Enterprise Plus edition
To disable query insights for Cloud SQL Enterprise Plus edition, do the following:
-
In the Google Cloud console, go to the Cloud SQL Instances page.
- To open the Overview page of an instance, click the instance name.
- Click Edit.
- In the Customize your instance section, expand Query insights.
- Clear the Enable Enterprise Plus features checkbox.
- Click Save.
What's next
- Launch blog: Database observability for developers: introducing Cloud SQL Insights
- See Google Cloud metrics.
- Blog: Boost your query performance troubleshooting skills with Cloud SQL Insights
- Video: Introducing Cloud SQL Insights
- Podcast: Cloud SQL Insights
- Insights Codelab
- Blog: Introducing Sqlcommenter: An open source ORM auto-instrumentation library
- Blog: Enable query tagging with Sqlcommenter