
![]()

Delta Sharing is an open protocol for secure real-time exchange of large datasets, which enables organizations to share data in real time regardless of which computing platforms they use. It is a simple REST protocol that securely shares access to part of a cloud dataset and leverages modern cloud storage systems, such as S3, ADLS, or GCS, to reliably transfer data.
With Delta Sharing, a user accessing shared data can directly connect to it through pandas, Tableau, Apache Spark, Rust, or other systems that support the open protocol, without having to deploy a specific compute platform first. Data providers can share a dataset once to reach a broad range of consumers, while consumers can begin using the data in minutes.

This repo includes the following components:
- Delta Sharing protocol specification.
- Python Connector: A Python library that implements the Delta Sharing Protocol to read shared tables as pandas DataFrame or Apache Spark DataFrames.
- Apache Spark Connector: An Apache Spark connector that implements the Delta Sharing Protocol to read shared tables from a Delta Sharing Server. The tables can then be accessed in SQL, Python, Java, Scala, or R.
- Delta Sharing Server: A reference implementation server for the Delta Sharing Protocol for development purposes. Users can deploy this server to share existing tables in Delta Lake and Apache Parquet format on modern cloud storage systems.
The Delta Sharing Python Connector is a Python library that implements the Delta Sharing Protocol to read tables from a Delta Sharing Server. You can load shared tables as a pandas DataFrame, or as an Apache Spark DataFrame if running in PySpark with the Apache Spark Connector installed.
Python 3.6+
pip install delta-sharing
If you are using Databricks Runtime, you can follow Databricks Libraries doc to install the library on your clusters.
The connector accesses shared tables based on profile files, which are JSON files containing a user's credentials to access a Delta Sharing Server. We have several ways to get started:
- Download the profile file to access an open, example Delta Sharing Server that we're hosting here. You can try the connectors with this sample data.
- Start your own Delta Sharing Server and create your own profile file following profile file format to connect to this server.
- Download a profile file from your data provider.
After you save the profile file, you can use it in the connector to access shared tables.
import delta_sharing
# Point to the profile file. It can be a file on the local file system or a file on a remote storage.
profile_file = "<profile-file-path>"
# Create a SharingClient.
client = delta_sharing.SharingClient(profile_file)
# List all shared tables.
client.list_all_tables()
# Create a url to access a shared table.
# A table path is the profile file path following with `#` and the fully qualified name of a table
# (`<share-name>.<schema-name>.<table-name>`).
table_url = profile_file + "#<share-name>.<schema-name>.<table-name>"
# Fetch 10 rows from a table and convert it to a Pandas DataFrame. This can be used to read sample data
# from a table that cannot fit in the memory.
delta_sharing.load_as_pandas(table_url, limit=10)
# Load a table as a Pandas DataFrame. This can be used to process tables that can fit in the memory.
delta_sharing.load_as_pandas(table_url)
# If the code is running with PySpark, you can use `load_as_spark` to load the table as a Spark DataFrame.
delta_sharing.load_as_spark(table_url)If the table supports history sharing(tableConfig.cdfEnabled=true in the OSS Delta Sharing Server), the connector can query table changes.
# Load table changes from version 0 to version 5, as a Pandas DataFrame.
delta_sharing.load_table_changes_as_pandas(table_url, starting_version=0, ending_version=5)
# If the code is running with PySpark, you can load table changes as Spark DataFrame.
delta_sharing.load_table_changes_as_spark(table_url, starting_version=0, ending_version=5)You can try this by running our examples with the open, example Delta Sharing Server.
- The profile file path for
SharingClientandload_as_pandascan be any URL supported by FSSPEC (such ass3a://my_bucket/my/profile/file). If you are using Databricks File System, you can also preface the path with/dbfs/to access the profile file as if it were a local file. - The profile file path for
load_as_sparkcan be any URL supported by Hadoop FileSystem (such ass3a://my_bucket/my/profile/file). - A table path is the profile file path following with
#and the fully qualified name of a table (<share-name>.<schema-name>.<table-name>).
The Apache Spark Connector implements the Delta Sharing Protocol to read shared tables from a Delta Sharing Server. It can be used in SQL, Python, Java, Scala and R.
- Java 8+
- Scala 2.12.x
- Apache Spark 3+ or Databricks Runtime 7+
The connector loads user credentials from profile files. Please see Accessing Shared Data to download a profile file for our example server or for your own data sharing server.
You can set up Apache Spark to load the Delta Sharing connector in the following two ways:
- Run interactively: Start the Spark shell (Scala or Python) with the Delta Sharing connector and run the code snippets interactively in the shell.
- Run as a project: Set up a Maven or SBT project (Scala or Java) with the Delta Sharing connector, copy the code snippets into a source file, and run the project.
If you are using Databricks Runtime, you can skip this section and follow Databricks Libraries doc to install the connector on your clusters.
To use Delta Sharing connector interactively within the Spark’s Scala/Python shell, you can launch the shells as follows.
pyspark --packages io.delta:delta-sharing-spark_2.12:0.6.4
bin/spark-shell --packages io.delta:delta-sharing-spark_2.12:0.6.4
If you want to build a Java/Scala project using Delta Sharing connector from Maven Central Repository, you can use the following Maven coordinates.
You include Delta Sharing connector in your Maven project by adding it as a dependency in your POM file. Delta Sharing connector is compiled with Scala 2.12.
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-sharing-spark_2.12</artifactId>
<version>0.6.4</version>
</dependency>You include Delta Sharing connector in your SBT project by adding the following line to your build.sbt file:
libraryDependencies += "io.delta" %% "delta-sharing-spark" % "0.6.4"After you save the profile file and launch Spark with the connector library, you can access shared tables using any language.
-- A table path is the profile file path following with `#` and the fully qualified name
-- of a table (`<share-name>.<schema-name>.<table-name>`).
CREATE TABLE mytable USING deltaSharing LOCATION '<profile-file-path>#<share-name>.<schema-name>.<table-name>';
SELECT * FROM mytable;# A table path is the profile file path following with `#` and the fully qualified name
# of a table (`<share-name>.<schema-name>.<table-name>`).
table_path = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
df = spark.read.format("deltaSharing").load(table_path)// A table path is the profile file path following with `#` and the fully qualified name
// of a table (`<share-name>.<schema-name>.<table-name>`).
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
val df = spark.read.format("deltaSharing").load(tablePath)// A table path is the profile file path following with `#` and the fully qualified name
// of a table (`<share-name>.<schema-name>.<table-name>`).
String tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>";
Dataset<Row> df = spark.read.format("deltaSharing").load(tablePath);# A table path is the profile file path following with `#` and the fully qualified name
# of a table (`<share-name>.<schema-name>.<table-name>`).
table_path <- "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
df <- read.df(table_path, "deltaSharing")You can try this by running our examples with the open, example Delta Sharing Server.
Starting from release 0.5.0, querying Change Data Feed is supported with Delta Sharing. Once the provider turns on CDF on the original delta table and shares it through Delta Sharing, the recipient can query CDF of a Delta Sharing table similar to CDF of a delta table.
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
val df = spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("startingVersion", "3")
.load(tablePath)Starting from release 0.6.0, Delta Sharing table can be used as a data source for Spark Structured Streaming. Once the provider shares a table with history, the recipient can perform a streaming query on the table.
Note: Trigger.AvailableNow is not supported in delta sharing streaming because it's supported since spark 3.3.0, while delta sharing is still using spark 3.1.1.
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
val df = spark.readStream.format("deltaSharing")
.option("startingVersion", "1")
.option("skipChangeCommits", "true")
.load(tablePath)- A profile file path can be any URL supported by Hadoop FileSystem (such as
s3a://my_bucket/my/profile/file). - A table path is the profile file path following with
#and the fully qualified name of a table (<share-name>.<schema-name>.<table-name>).
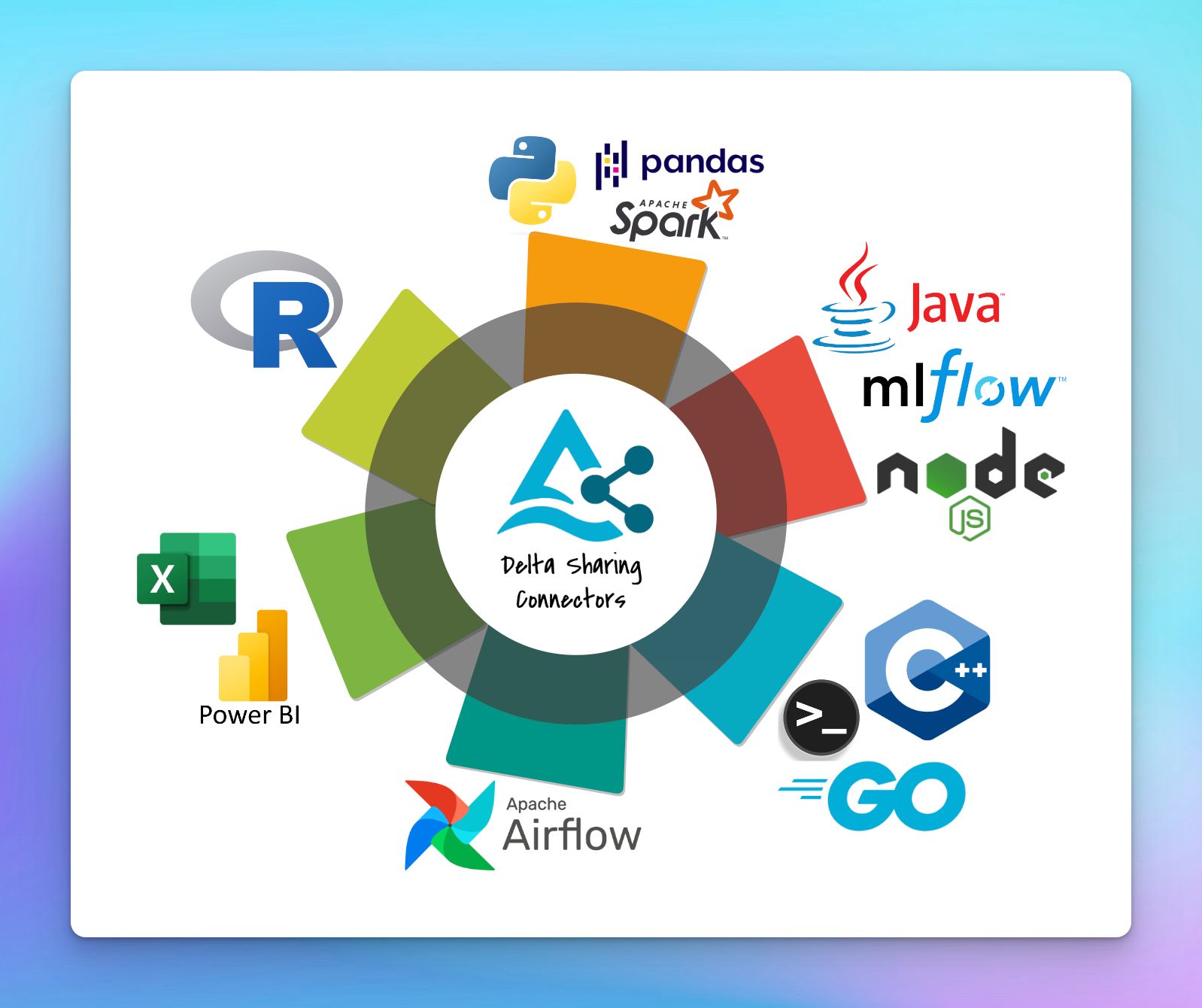
| Connector | Link | Status | Supported Features |
|---|---|---|---|
| Power BI | Databricks owned | Released | QueryTableVersion QueryTableMetadata QueryTableLatestSnapshot |
| Node.js | Released | QueryTableVersion QueryTableMetadata QueryTableLatestSnapshot |
|
| Java | Released | QueryTableVersion QueryTableMetadata QueryTableLatestSnapshot |
|
| Arcuate | Released | QueryTableVersion QueryTableMetadata QueryTableLatestSnapshot |
|
| Rust | Released | QueryTableVersion QueryTableMetadata QueryTableLatestSnapshot |
|
| Go | Released | QueryTableVersion QueryTableMetadata QueryTableLatestSnapshot |
|
| C++ | Released | QueryTableMetadata QueryTableLatestSnapshot |
|
| R | Released | QueryTableVersion QueryTableMetadata QueryTableLatestSnapshot |
|
| Google Spreadsheet | Beta | QueryTableVersion QueryTableMetadata QueryTableLatestSnapshot |
|
| Airflow | Un-released | N/A | |
| Excel-Connector | limited-release | N/A | |
| Lakehouse Sharing | Preview |
Demonstrates a table format agnostic data sharing |
The Delta Sharing Reference Server is a reference implementation server for the Delta Sharing Protocol. This can be used to set up a small service to test your own connector that implements the Delta Sharing Protocol. Please note that this is not a completed implementation of secure web server. We highly recommend you to put this behind a secure proxy if you would like to expose it to public.
Some vendors offer managed services for Delta Sharing too (for example, Databricks). Please refer to your vendor's website for how to set up sharing there. Vendors that are interested in being listed as a service provider should open an issue on GitHub to be added to this README and our project's website.
Here are the steps to setup the reference server to share your own data.
Download the pre-built package delta-sharing-server-x.y.z.zip from GitHub Releases.
- Unpack the pre-built package and copy the server config template file
conf/delta-sharing-server.yaml.templateto create your own server yaml file, such asconf/delta-sharing-server.yaml. - Make changes to your yaml file. You may also need to update some server configs for special requirements.
- To add Shared Data, add reference to Delta Lake tables you would like to share from this server in this config file.
We support sharing Delta Lake tables on S3, Azure Blob Storage and Azure Data Lake Storage Gen2.
The server is using hadoop-aws to access S3. Table paths in the server config file should use s3a:// paths rather than s3:// paths. There are multiple ways to config S3 authentication.
Applications running in EC2 may associate an IAM role with the VM and query the EC2 Instance Metadata Service for credentials to access S3.
We support configuration via the standard AWS environment variables. The core environment variables are for the access key and associated secret:
export AWS_ACCESS_KEY_ID=my.aws.key
export AWS_SECRET_ACCESS_KEY=my.secret.key
You can find other approaches in hadoop-aws doc.
The server is using hadoop-azure to read Azure Blob Storage. Using Azure Blob Storage requires configuration of credentials. You can create a Hadoop configuration file named core-site.xml and add it to the server's conf directory. Then add the following content to the xml file:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.azure.account.key.YOUR-ACCOUNT-NAME.blob.core.windows.net</name>
<value>YOUR-ACCOUNT-KEY</value>
</property>
</configuration>YOUR-ACCOUNT-NAME is your Azure storage account and YOUR-ACCOUNT-KEY is your account key.
The server is using hadoop-azure to read Azure Data Lake Storage Gen2. We support the Shared Key authentication. You can create a Hadoop configuration file named core-site.xml and add it to the server's conf directory. Then add the following content to the xml file:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.azure.account.auth.type.YOUR-ACCOUNT-NAME.dfs.core.windows.net</name>
<value>SharedKey</value>
<description>
</description>
</property>
<property>
<name>fs.azure.account.key.YOUR-ACCOUNT-NAME.dfs.core.windows.net</name>
<value>YOUR-ACCOUNT-KEY</value>
<description>
The secret password. Never share these.
</description>
</property>
</configuration>YOUR-ACCOUNT-NAME is your Azure storage account and YOUR-ACCOUNT-KEY is your account key.
We support using Service Account to read Google Cloud Storage. You can find more details in GCP Authentication Doc.
To set up the Service Account credentials, you can specify the environment GOOGLE_APPLICATION_CREDENTIALS before starting the Delta Sharing Server.
export GOOGLE_APPLICATION_CREDENTIALS="KEY_PATH"
Replace KEY_PATH with path of the JSON file that contains your service account key.
We use an R2 implementation of the S3 API and hadoop-aws to read Cloudflare R2. Table paths in the server config file should use the s3a:// scheme. You must generate an API token for usage with existing S3-compatible SDKs. These credentials can be specified in substitute of the S3 credentials in a Hadoop configuration file named core-site.xml within the server's conf directory. For R2 to work, you also need to directly specify the S3 endpoint and reduce fs.s3a.paging.maximum from Hadoop's default of 5000 to 1000 since R2 only supports MaxKeys <= 1000.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>YOUR-ACCESS-KEY</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>YOUR-SECRET-KEY</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>https://YOUR-ACCOUNT-ID.r2.cloudflarestorage.com</value>
</property>
<property>
<name>fs.s3a.paging.maximum</name>
<value>1000</value>
</property>
</configuration>Replace YOUR-ACCESS-KEY with your generated API token's R2 access key ID, YOUR-SECRET-KEY with your generated API token's secret access key, and YOUR-ACCOUNT-ID with your Cloudflare account ID.
Note: S3 and R2 credentials cannot be configured simultaneously.
The server supports a basic authorization with pre-configed bearer token. You can add the following config to your server yaml file:
authorization:
bearerToken: <token>Then any request should send with the above token, otherwise, the server will refuse the request.
If you don't config the bearer token in the server yaml file, all requests will be accepted without authorization.
To be more secure, you recommend you to put the server behind a secure proxy such as NGINX to set up JWT Authentication.
Run the following shell command:
bin/delta-sharing-server -- --config <the-server-config-yaml-file>
<the-server-config-yaml-file> should be the path of the yaml file you created in the previous step. You can find options to config JVM in sbt-native-packager.
You can use the pre-built docker image from https://hub.docker.com/r/deltaio/delta-sharing-server by running the following command
docker run -p <host-port>:<container-port> \
--mount type=bind,source=<the-server-config-yaml-file>,target=/config/delta-sharing-server-config.yaml \
deltaio/delta-sharing-server:0.6.4 -- --config /config/delta-sharing-server-config.yaml
Note that <container-port> should be the same as the port defined inside the config file.
The REST APIs provided by Delta Sharing Server are stable public APIs. They are defined by Delta Sharing Protocol and we will follow the entire protocol strictly.
The interfaces inside Delta Sharing Server are not public APIs. They are considered internal, and they are subject to change across minor/patch releases.
The Delta Sharing Protocol specification details the protocol.
To execute tests, run
python/dev/pytest
To install in develop mode, run
cd python/
pip install -e .
To install locally, run
cd python/
pip install .
To generate a wheel file, run
cd python/
python setup.py sdist bdist_wheel
It will generate python/dist/delta_sharing-x.y.z-py3-none-any.whl.
Apache Spark Connector and Delta Sharing Server are compiled using SBT.
To compile, run
build/sbt compile
To execute tests, run
build/sbt test
To generate the Apache Spark Connector, run
build/sbt spark/package
It will generate spark/target/scala-2.12/delta-sharing-spark_2.12-x.y.z.jar.
To generate the pre-built Delta Sharing Server package, run
build/sbt server/universal:packageBin
It will generate server/target/universal/delta-sharing-server-x.y.z.zip.
To build the Docker image for Delta Sharing Server, run
build/sbt server/docker:publishLocal
This will build a Docker image tagged delta-sharing-server:x.y.z, which you can run with:
docker run -p <host-port>:<container-port> \
--mount type=bind,source=<the-server-config-yaml-file>,target=/config/delta-sharing-server-config.yaml \
delta-sharing-server:x.y.z -- --config /config/delta-sharing-server-config.yaml
Note that <container-port> should be the same as the port defined inside the config file.
Refer to SBT docs for more commands.
We use GitHub Issues to track community reported issues. You can also contact the community for getting answers.
We welcome contributions to Delta Sharing. See our CONTRIBUTING.md for more details.
We also adhere to the Delta Lake Code of Conduct.
We use the same community resources as the Delta Lake project:
-
Public Slack Channel
-
Public Mailing list