- System Analysis and Design Tutorial
- System Analysis and Design - Home
- System Analysis & Design - Overview
- Differences between System Analysis and System Design
- System Analysis and Design - Communication Protocols
- Horizontal and Vertical Scaling in System Design
- Capacity Estimation in Systems Design
- Roles of Web Server and Proxies in Designing Systems
- Clustering and Load Balancing
- System Development Life Cycle
- System Development Life Cycle
- System Analysis and Design - Requirement Determination
- System Analysis and Design - Systems Implementation
- System Analysis and Design - System Planning
- System Analysis and Design - Structured Analysis
- System Design
- System Analysis and Design - Design Strategies
- System Analysis and Design - Software Deployment
- Software Deployment Example Using Docker
- Functional Vs. Non-functional Requirements
- Data Flow Diagrams(DFD)
- Data Flow Diagram - What It Is?
- Data Flow Diagram - Types and Components
- Data Flow Diagram - Development
- Data Flow Diagram - Balancing
- Data Flow Diagram - Decomposition
- Databases in System Design
- System Design - Databases
- System Design - Database Sharding
- System Design - Database Replication
- System Design - Database Federation
- System Design - Designing Authentication System
- Database Design Vs. Database Architecture
- Database Federation Vs. Database Sharding
- High Level Design(HLD)
- System Design - High Level Design
- System Design - Availability
- System Design - Consistency
- System Design - Reliability
- System Design - CAP Theorem
- System Design - API Gateway
- Low Level Design(LLD)
- System Design - Low Level Design
- System Design - Authentication Vs. Authorization
- System Design - Performance Optimization Techniques
- System Design - Containerization Architecture
- System Design - Modularity and Interfaces
- System Design - CI/CD Pipelines
- System Design - Data Partitioning Techniques
- System Design - Essential Security Measures
- System Implementation
- Input / Output & Forms Design
- Testing and Quality Assurance
- Implementation & Maintenance
- System Security and Audit
- Object-Oriented Approach
- System Analysis & Design Resources
- Quick Guide
- Useful Resources
- Discussion
System Analysis and Design - Quick Guide
System Analysis and Design - Overview
Systems development is systematic process which includes phases such as planning, analysis, design, deployment, and maintenance. Here, in this tutorial, we will primarily focus on −
- Systems analysis
- Systems design
Systems Analysis
It is a process of collecting and interpreting facts, identifying the problems, and decomposition of a system into its components.
System analysis is conducted for the purpose of studying a system or its parts in order to identify its objectives. It is a problem solving technique that improves the system and ensures that all the components of the system work efficiently to accomplish their purpose.
Analysis specifies what the system should do.
Systems Design
It is a process of planning a new business system or replacing an existing system by defining its components or modules to satisfy the specific requirements. Before planning, you need to understand the old system thoroughly and determine how computers can best be used in order to operate efficiently.
System Design focuses on how to accomplish the objective of the system.
System Analysis and Design (SAD) mainly focuses on −
- Systems
- Processes
- Technology
What is a System?
The word System is derived from Greek word Systema, which means an organized relationship between any set of components to achieve some common cause or objective.
A system is “an orderly grouping of interdependent components linked together according to a plan to achieve a specific goal.”
Constraints of a System
A system must have three basic constraints −
A system must have some structure and behavior which is designed to achieve a predefined objective.
Interconnectivity and interdependence must exist among the system components.
The objectives of the organization have a higher priority than the objectives of its subsystems.
For example, traffic management system, payroll system, automatic library system, human resources information system.
Properties of a System
A system has the following properties −
Organization
Organization implies structure and order. It is the arrangement of components that helps to achieve predetermined objectives.
Interaction
It is defined by the manner in which the components operate with each other.
For example, in an organization, purchasing department must interact with production department and payroll with personnel department.
Interdependence
Interdependence means how the components of a system depend on one another. For proper functioning, the components are coordinated and linked together according to a specified plan. The output of one subsystem is the required by other subsystem as input.
Integration
Integration is concerned with how a system components are connected together. It means that the parts of the system work together within the system even if each part performs a unique function.
Central Objective
The objective of system must be central. It may be real or stated. It is not uncommon for an organization to state an objective and operate to achieve another.
The users must know the main objective of a computer application early in the analysis for a successful design and conversion.
Elements of a System
The following diagram shows the elements of a system −
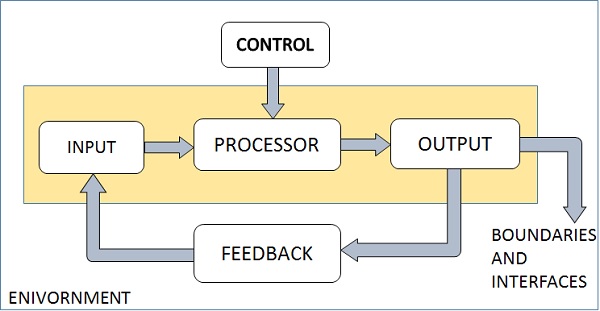
Outputs and Inputs
The main aim of a system is to produce an output which is useful for its user.
Inputs are the information that enters into the system for processing.
Output is the outcome of processing.
Processor(s)
The processor is the element of a system that involves the actual transformation of input into output.
It is the operational component of a system. Processors may modify the input either totally or partially, depending on the output specification.
As the output specifications change, so does the processing. In some cases, input is also modified to enable the processor for handling the transformation.
Control
The control element guides the system.
It is the decision–making subsystem that controls the pattern of activities governing input, processing, and output.
The behavior of a computer System is controlled by the Operating System and software. In order to keep system in balance, what and how much input is needed is determined by Output Specifications.
Feedback
Feedback provides the control in a dynamic system.
Positive feedback is routine in nature that encourages the performance of the system.
Negative feedback is informational in nature that provides the controller with information for action.
Environment
The environment is the “supersystem” within which an organization operates.
It is the source of external elements that strike on the system.
It determines how a system must function. For example, vendors and competitors of organization’s environment, may provide constraints that affect the actual performance of the business.
Boundaries and Interface
A system should be defined by its boundaries. Boundaries are the limits that identify its components, processes, and interrelationship when it interfaces with another system.
Each system has boundaries that determine its sphere of influence and control.
The knowledge of the boundaries of a given system is crucial in determining the nature of its interface with other systems for successful design.
Types of Systems
The systems can be divided into the following types −
Physical or Abstract Systems
Physical systems are tangible entities. We can touch and feel them.
Physical System may be static or dynamic in nature. For example, desks and chairs are the physical parts of computer center which are static. A programmed computer is a dynamic system in which programs, data, and applications can change according to the user's needs.
Abstract systems are non-physical entities or conceptual that may be formulas, representation or model of a real system.
Open or Closed Systems
An open system must interact with its environment. It receives inputs from and delivers outputs to the outside of the system. For example, an information system which must adapt to the changing environmental conditions.
A closed system does not interact with its environment. It is isolated from environmental influences. A completely closed system is rare in reality.
Adaptive and Non Adaptive System
Adaptive System responds to the change in the environment in a way to improve their performance and to survive. For example, human beings, animals.
Non Adaptive System is the system which does not respond to the environment. For example, machines.
Permanent or Temporary System
Permanent System persists for long time. For example, business policies.
Temporary System is made for specified time and after that they are demolished. For example, A DJ system is set up for a program and it is dissembled after the program.
Natural and Manufactured System
Natural systems are created by the nature. For example, Solar system, seasonal system.
Manufactured System is the man-made system. For example, Rockets, dams, trains.
Deterministic or Probabilistic System
Deterministic system operates in a predictable manner and the interaction between system components is known with certainty. For example, two molecules of hydrogen and one molecule of oxygen makes water.
Probabilistic System shows uncertain behavior. The exact output is not known. For example, Weather forecasting, mail delivery.
Social, Human-Machine, Machine System
Social System is made up of people. For example, social clubs, societies.
In Human-Machine System, both human and machines are involved to perform a particular task. For example, Computer programming.
Machine System is where human interference is neglected. All the tasks are performed by the machine. For example, an autonomous robot.
Man–Made Information Systems
It is an interconnected set of information resources to manage data for particular organization, under Direct Management Control (DMC).
This system includes hardware, software, communication, data, and application for producing information according to the need of an organization.
Man-made information systems are divided into three types −
Formal Information System − It is based on the flow of information in the form of memos, instructions, etc., from top level to lower levels of management.
Informal Information System − This is employee based system which solves the day to day work related problems.
Computer Based System − This system is directly dependent on the computer for managing business applications. For example, automatic library system, railway reservation system, banking system, etc.
Systems Models
Schematic Models
A schematic model is a 2-D chart that shows system elements and their linkages.
Different arrows are used to show information flow, material flow, and information feedback.
Flow System Models
A flow system model shows the orderly flow of the material, energy, and information that hold the system together.
Program Evaluation and Review Technique (PERT), for example, is used to abstract a real world system in model form.
Static System Models
They represent one pair of relationships such as activity–time or cost–quantity.
The Gantt chart, for example, gives a static picture of an activity-time relationship.
Dynamic System Models
Business organizations are dynamic systems. A dynamic model approximates the type of organization or application that analysts deal with.
It shows an ongoing, constantly changing status of the system. It consists of −
Inputs that enter the system
The processor through which transformation takes place
The program(s) required for processing
The output(s) that result from processing.
Categories of Information
There are three categories of information related to managerial levels and the decision managers make.

Strategic Information
This information is required by topmost management for long range planning policies for next few years. For example, trends in revenues, financial investment, and human resources, and population growth.
This type of information is achieved with the aid of Decision Support System (DSS).
Managerial Information
This type of Information is required by middle management for short and intermediate range planning which is in terms of months. For example, sales analysis, cash flow projection, and annual financial statements.
It is achieved with the aid of Management Information Systems (MIS).
Operational information
This type of information is required by low management for daily and short term planning to enforce day-to-day operational activities. For example, keeping employee attendance records, overdue purchase orders, and current stocks available.
It is achieved with the aid of Data Processing Systems (DPS).
Differences between System Analysis and System Design
Introduction
System analysis and system design are two critical phases in the development lifecycle of a software system. While they are often used interchangeably, they serve distinct purposes and involve different methodologies. This article will delve into the key differences between system analysis and system design, their roles in the development process, and the techniques used in each phase.
System Analysis
System analysis is the initial phase of a software development project where the requirements of the system are gathered, analyzed, and documented. It involves understanding the problem domain, identifying the stakeholders, and defining the scope and objectives of the system.
Key Activities in System Analysis
Requirement Gathering− Identifying the needs and expectations of the users and stakeholders.
Requirement Analysis− Analyzing the gathered requirements to ensure consistency, feasibility, and completeness.
Feasibility Study− Assessing the technical, economic, and operational feasibility of the proposed system.
Process Modelling− Creating diagrams and models to represent the current and proposed business processes.
Data Modelling− Defining the data entities, attributes, and relationships within the system.
Techniques Used in System Analysis
Interviews− Gathering information from stakeholders through face-to-face or online interviews.
Surveys− Collecting data from a large number of respondents using questionnaires.
Observation− Observing the current system in operation to understand its processes and workflows.
Document Analysis− Examining existing documents, reports, and manuals.
Prototyping− Creating simplified models or mock-up’s of the system to gather feedback and refine requirements.
System Design
System design is the subsequent phase where the detailed specifications of the system are developed. It involves designing the architecture, components, interfaces, and data structures that will implement the requirements defined in the analysis phase.
Key Activities in System Design
Architectural Design− Determining the overall structure and components of the system.
Component Design− Designing individual components and their interactions.
Interface Design− Specifying the interfaces between components and with external systems.
Data Design− Designing the database schema and data structures.
Detailed Design− Creating detailed specifications for each component, including algorithms and data flow.
Techniques Used in System Design
Unified Modelling Language (UML)− A standardized modelling language used to visualize, specify, construct, and document software systems.
Data Flow Diagrams (DFDs)− Diagrams that illustrate the flow of data through a system.
Entity-Relationship Diagrams (ERDs)− Diagrams that represent the entities and relationships between them in a database.
Decision Trees− Diagrams that show the possible outcomes and decisions in a process.
State Transition Diagrams− Diagrams that represent the different states a system can be in and the transitions between them.
Key Differences Between System Analysis and System Design
| Sr.No. | Feature | System Analysis | System Design |
|---|---|---|---|
| 1 | Focus | Understanding the problem domain and gathering requirements. | Specifying the solution and designing the system. |
| 2 | Output | Requirements document | System design specifications |
| 3 | Techniques | Interviews, surveys, observation, document analysis | UML, DFDs, ERDs, decision trees, state transition diagrams |
| 4 | Level of Detail | High-level understanding | Detailed specifications |
The Relationship Between System Analysis and System Design
System analysis and system design are closely interconnected. The output of the analysis phase (the requirements document) serves as the input for the design phase. The design specifications must align with the requirements to ensure that the developed system meets the needs of the users and stakeholders.
Conclusion
System analysis and system design are essential phases in the development of software systems. While they have distinct roles and methodologies, they work together to ensure that the final product meets the desired requirements and delivers value to the users. By effectively conducting system analysis and design, organizations can develop high-quality, efficient, and user-friendly software systems.
System Analysis & Design - Communication Protocols
This article covers different layers of communication, key protocols, and their practical significance.
Introduction
Effective communication is essential in modern networking systems, as it ensures seamless interaction between different devices, applications, and services. Communication protocols act as standardized sets of rules, enabling interoperability, reliability, and security in these systems. From the early days of telegraphy to modern-day internet communication, protocols have evolved to meet the growing demands of data exchange and complex applications.
This article explores the concepts of communication and the various types of protocols that govern data transfer, focusing on the significance of these protocols in today's digital landscape.
Communication Overview
Communication, in technical terms, refers to the exchange of data between two or more systems, either locally or over a network. To facilitate such exchanges, specific rules must be adhered to, ensuring that the sender and receiver can understand each other. This includes data formatting, transmission methods, and error checking.
Types of Communication
Synchronous vs. Asynchronous Communication−
Synchronous− Data is sent and received in real-time (e.g. live video conferencing).
Asynchronous− Data can be sent and processed independently (e.g., emails, messaging).
Unicast, Broadcast, and Multicast Communication−
Unicast− One-to-one communication (e.g. a client-server request).
Broadcast− One-to-many communication (e.g., TV broadcasts, Ethernet data).
Multicast− One-to-select-many (e.g., video conferencing with selected participants).
Half-duplex and Full-duplex Communication−
Half-duplex− Data transmission in one direction at a time (e.g. walkie-talkies).
Full-duplex− Simultaneous transmission and reception (e.g. telephone).
Protocols: The Backbone of Communication
A protocol is a set of rules that defines how data is transmitted and received across networks. It dictates every aspect of communication, from the format of the data to the mechanisms that ensure its delivery. Protocols operate at various levels, each tailored to a specific function within a network.
Importance of Protocols
Standardization− Protocols ensure devices from different manufacturers and environments can communicate.
Reliability− Protocols incorporate error-checking and correction mechanisms.
Interoperability− They allow systems with different architectures to communicate.
Efficiency− Data is transferred efficiently by organizing it into packets or frames.
The OSI Model: A Layered Approach
To understand the different protocols used in communication, we need to explore the Open Systems Interconnection (OSI) Model, which provides a framework for network communication divided into seven layers.
Physical Layer− Deals with the physical transmission of data (e.g. cables, switches).
Data Link Layer− Manages data transfer between directly connected nodes (e.g. MAC addresses, Ethernet).
Network Layer− Handles routing of data across networks (e.g. IP).
Transport Layer− Provides error-checking and guarantees data delivery (e.g. TCP).
Session Layer− Manages sessions between applications (e.g., establishing and terminating connections).
Presentation Layer− Transforms data into the format required by the application layer (e.g., encryption, compression).
Application Layer− Interfaces with end-user applications (e.g. HTTP, FTP).
Each layer in the OSI model has its own set of protocols, each performing specific functions to facilitate communication.
Common Protocols and Their Functions
Transport Layer Protocols
TCP (Transmission Control Protocol)− TCP is connection-oriented, ensuring data is transmitted reliably by establishing a connection between sender and receiver. It uses error-checking mechanisms and ensures data arrives in order, making it ideal for applications requiring accuracy (e.g., web browsing, email).
UDP (User Datagram Protocol)− UDP is connectionless, which makes it faster than TCP. However, it does not guarantee the delivery of data, making it useful for time-sensitive applications like streaming, where speed is more important than perfect accuracy.
Internet Layer Protocols
IP (Internet Protocol)− IP is responsible for addressing and routing packets of data to ensure they reach the correct destination. It operates at the network layer and uses addresses to identify both the sender and receiver.
IPv4 vs. IPv6− IPv4 is the most widely used version, with a 32-bit address scheme. IPv6 is the successor to IPv4, using a 128-bit address to accommodate the growing number of devices on the internet.
Application Layer Protocols
HTTP/HTTPS− HTTP (Hypertext Transfer Protocol) is the foundation of data communication for the World Wide Web. HTTPS adds a layer of security through encryption, making it essential for secure communication on the web.
FTP (File Transfer Protocol)− Used for transferring files between computers. Though widely used, it has largely been replaced by more secure alternatives like SFTP and FTPS, which incorporate encryption.
SMTP (Simple Mail Transfer Protocol)− Facilitates the sending of emails. Often used in combination with IMAP or POP for retrieving emails from servers.
DNS (Domain Name System)− Translates human-readable domain names (e.g., www.example.com) into IP addresses that computers can understand.
Wireless Protocols
Wi-Fi (IEEE 802.11)− A set of standards for wireless local area networks (WLANs) that enable devices to communicate over wireless networks.
Bluetooth− Used for short-range communication between devices, such as connecting wireless headphones to a phone.
Security Protocols: Ensuring Safe Communication
With the rise of cyber threats, security protocols have become integral to maintaining data integrity, confidentiality, and authentication. Several protocols work to secure data in transit.
SSL/TLS (Secure Socket Layer / Transport Layer Security)− These protocols secure communication over networks, especially the internet, by encrypting data. SSL has been deprecated in favour of TLS due to vulnerabilities.
IPsec (Internet Protocol Security)− A suite of protocols used to secure Internet Protocol (IP) communications by authenticating and encrypting each IP packet in a communication session.
SSH (Secure Shell)− Provides a secure method for remote login and other secure network services over an unsecured network.
Future of Communication Protocols
As technology continues to evolve, the demand for faster, more secure, and reliable communication protocols grows. New protocols are being developed to accommodate emerging technologies, including the Internet of Things (IoT), 5G networks, and quantum computing.
5G Protocols− The fifth-generation mobile networks promise faster data transfer rates, reduced latency, and better support for IoT devices, requiring new protocols like 5G-NR (New Radio) and 5GC (5G Core Network).
IoT Communication Protocols− Protocols such as MQTT (Message Queuing Telemetry Transport) and CoAP (Constrained Application Protocol) are lightweight and ideal for the low-power, low-bandwidth requirements of IoT devices.
Quantum Communication Protocols− With the development of quantum computing, researchers are exploring new protocols that leverage quantum entanglement and superposition to create secure communication channels, potentially revolutionizing encryption and network security.
Conclusion
Communication and protocols form the backbone of modern networking, enabling devices and systems to communicate efficiently, reliably, and securely. As technology advances, so too do the protocols that govern data exchange, adapting to new requirements such as higher speeds, increased security, and the ability to handle more devices. The future holds exciting prospects, with advancements like 5G and quantum communication set to redefine the way we think about and use communication protocols.
Horizontal and Vertical Scaling in System Design
Introduction
As applications and systems grow in size and complexity, ensuring they remain efficient and responsive becomes a key challenge. This leads to the discussion of scalability, which is the system’s ability to handle increased load. Scalability can be achieved through two primary methods: horizontal scaling (scale-out) and vertical scaling (scale-up). Both approaches come with distinct advantages, challenges, and best-use cases. In this article, we'll explore the concepts of horizontal and vertical scaling in detail, discussing their respective architectures, benefits, and limitations, as well as how to choose the right scaling method for specific scenarios.
What is Scaling?
Before diving into the specifics of horizontal and vertical scaling, it is essential to understand what scaling entails.
Scaling refers to the process of adjusting resources—such as computing power, storage, or network capabilities—to ensure that an application can handle increased demand without sacrificing performance. As systems grow and face more users, more transactions, or increased data throughput, scaling ensures that the system maintains its efficiency and does not become a bottleneck.
There are two fundamental approaches to scaling: vertical and horizontal.
Vertical Scaling (Scale-Up)
Vertical scaling, or scaling up, involves enhancing the capacity of a single machine or server by adding more powerful resources to it. These resources may include−
Adding more CPU (Central Processing Units).
Increasing RAM (Random Access Memory).
Expanding storage capacity (SSD/HDD).
Increasing network bandwidth capacity.
Essentially, vertical scaling is about making a single machine more powerful by upgrading its components or replacing it with a stronger version.
Vertical Scaling
In vertical scaling, the application continues to run on the same physical machine, but the machine's capabilities are improved. For example, if an application hosted on a server becomes slow due to an increased number of requests, vertical scaling might involve replacing that server with a more powerful one (e.g., from a 16-core processor to a 32-core processor).
The architecture remains unchanged—there is still only one machine or node, albeit one that is much more powerful.
Benefits of Vertical Scaling
Simplicity− Vertical scaling is generally straightforward since it does not require major changes to the application architecture. You simply add more resources to the existing server.
Reduced Complexity− Managing a single server reduces the complexity of operations, including maintenance and monitoring.
Consistency− Since the system runs on a single machine, data consistency is easier to maintain, particularly in cases involving databases, where consistency guarantees are paramount.
Ideal for Monolithic Applications− Monolithic applications, which are tightly coupled and difficult to break down into smaller components, may benefit from vertical scaling since the entire application runs on one machine.
Limitations of Vertical Scaling
Single Point of Failure− With only one machine handling the entire application, it becomes a single point of failure. If the server crashes or faces hardware issues, the whole system may go down.
Resource Limits− Eventually, a physical server can only be upgraded so much. There is a limit to how much CPU, RAM, or storage can be added to a single machine. This "ceiling" may restrict long-term scalability.
Cost− High-end servers and components are expensive. Upgrading a server to the most advanced hardware options can result in substantial upfront costs.
Downtime During Upgrades− Depending on the system, upgrading hardware (e.g., adding RAM or storage) might require shutting down the server, which leads to downtime. In mission-critical systems, even brief downtime can be problematic.
Horizontal Scaling (Scale-Out)
Horizontal scaling, or scaling out, involves adding more machines or nodes to the system, effectively distributing the load across multiple devices. Instead of upgrading the power of a single machine, you add more machines to a cluster to share the load.
Horizontal Scaling Architecture
In horizontal scaling, the architecture is designed for a distributed system where multiple servers (or nodes) work together to handle the increased load.
For example, a website experiencing a surge in traffic might add more servers to handle the additional requests. A load balancer is typically used to distribute traffic evenly across these servers, ensuring that no single machine is overwhelmed. In a distributed database system, horizontal scaling means partitioning the data across multiple machines (sharding) to handle more transactions or larger datasets.
Benefits of Horizontal Scaling
No Theoretical Limit− One of the biggest advantages of horizontal scaling is that there is no theoretical limit to how many servers you can add. As demand grows, you can continue adding machines, thus providing potentially infinite scalability.
Fault Tolerance− Since multiple machines are involved, if one node fails, the system can continue to operate using the remaining nodes. This redundancy provides greater fault tolerance.
Cost Efficiency at Scale− Instead of investing in one high-end machine, horizontal scaling allows the use of many lower-end machines. This can be more cost-effective in the long run, especially in cloud environments where resources can be allocated dynamically.
Better for Cloud and Distributed Applications− Horizontal scaling is ideal for cloud-native and distributed systems like microservices architectures, where different parts of the application can run independently on different servers.
Limitations of Horizontal Scaling
Increased Complexity− Managing multiple servers is inherently more complex than managing a single server. It requires more sophisticated tools for orchestration, monitoring, and load balancing.
Data Consistency Issues− In distributed systems, maintaining data consistency across multiple nodes can be challenging, especially in applications where strong consistency is crucial (e.g., financial applications).
Network Overhead− With more servers, communication between nodes increases, potentially leading to network latency and overhead. Ensuring efficient communication between machines becomes a key concern.
Scaling the Entire Stack− For certain workloads, scaling horizontally might require that the entire application stack (e.g., databases, caches, and processing systems) be designed for horizontal distribution, which may require significant refactoring.
Horizontal vs. Vertical Scaling: A Comparison
| Sr.No. | Feature | Horizontal Scaling | Vertical Scaling |
|---|---|---|---|
| 1 | Definition | Adding more machines or nodes | Enhancing resources on a single machine |
| 2 | Cost | More cost-effective for long-term | Expensive upfront for powerful hardware |
| 3 | Fault Tolerance | High, due to multiple nodes | Low, due to a single point of failure |
| 4 | Complexity | Higher (requires orchestration) | Lower (single machine to manage) |
| 5 | Limits | No theoretical limit | Hardware limits |
| 6 | Downtime During Upgrades | Little to no downtime | May require downtime |
| 7 | Use Case | Cloud, distributed apps, microservices | Monolithic, single-machine systems |
Hybrid Approaches
In many cases, organizations use a combination of both horizontal and vertical scaling. For example, they may start with vertical scaling to meet initial needs and switch to horizontal scaling as demand increases. In cloud environments like AWS or Google Cloud, auto-scaling features allow companies to seamlessly switch between the two, depending on the load.
Some systems also employ hybrid architectures, using vertical scaling for certain components (e.g., databases) while horizontally scaling other components (e.g., web servers). This hybrid approach can offer the best of both worlds but comes at the cost of increased architectural complexity.
When to Choose Horizontal or Vertical Scaling
The choice between horizontal and vertical scaling depends on several factors−
Application Architecture− Distributed systems or microservices naturally lend themselves to horizontal scaling, whereas monolithic applications are easier to scale vertically.
Budget− Horizontal scaling may be more cost-effective in the cloud, where additional instances can be spun up as needed. Vertical scaling may result in high costs due to expensive hardware.
Consistency Requirements− Applications requiring strict data consistency (like banking systems) may favour vertical scaling due to simpler data management.
Expected Growth− If your application is expected to grow rapidly, horizontal scaling may be more appropriate since it offers theoretically unlimited scaling potential.
Conclusion
Both horizontal and vertical scaling are critical concepts in system architecture, each with unique strengths and challenges. Vertical scaling offers simplicity but is limited by hardware constraints, while horizontal scaling provides virtually limitless scalability at the cost of increased complexity. Understanding the nuances of these scaling methods is essential for building efficient, reliable, and scalable systems, especially as more applications migrate to cloud-native architectures.
Selecting the right scaling strategy depends on factors such as your application’s architecture, budget, and scalability needs. In today’s cloud-driven environment, a hybrid approach that leverages the benefits of both horizontal and vertical scaling may offer the most flexibility and cost-effectiveness.
Capacity Estimation in Systems Design
Introduction
Capacity estimation is essential in systems design, involving the process of predicting the required resources—such as server capacity, storage, network bandwidth, and database performance—necessary to handle expected workloads. Proper estimation prevents system bottlenecks, reduces operational costs, and ensures a smooth user experience. This article explores fundamental concepts, estimation methods, tools, and considerations involved in capacity estimation, especially within large-scale distributed systems.
Understanding Capacity Estimation
Definition and Importance: Explain capacity estimation as a planning strategy to ensure a system can handle expected and peak workloads without failure.
Key Metrics
Throughput− Transactions per second or requests per second.
Latency− Time to complete a transaction or request.
Response Time− The total time a user waits for a response.
Load and Concurrency− The number of concurrent users or operations.
Utilization− Percentage of capacity used.
Business Impact− Outline the cost implications of over-provisioning and the risk of under-provisioning.
Fundamental Concepts in Capacity Estimation
Capacity vs. Performance− Distinguish between capacity, focusing on the quantity of service (e.g., number of requests handled), and performance, emphasizing the quality of service (e.g., response time).
Scalability− Discuss how systems should be designed to scale horizontally (adding more instances) and vertically (upgrading resources).
System Bottlenecks− Types of bottlenecks (CPU, memory, I/O, network) and their impact on capacity.
Steps in Capacity Estimation
Define Requirements− Identify the expected workload, peak traffic, and availability needs.
Analyze Historical Data− Use historical system data to find patterns and identify trends.
Model the System−
Workload Modelling− Characterize the types and intensity of workloads (e.g., read-heavy vs. write-heavy operations).
Resource Consumption Modelling− Quantify resource usage for each workload (CPU, memory, disk I/O).
Concurrency and Scaling Factors− Include factors for concurrency and examine how each resource is affected.
Conduct Load Testing− Perform stress and load tests to validate models and identify bottlenecks.
Estimate Growth− Forecast workload growth based on business expectations.
Provision Resources− Calculate the required resources for the projected capacity with a margin for peak usage.
Capacity Estimation Techniques
Analytical Techniques
Queuing Theory− Used to predict performance under different load conditions.
Little’s Law− Applies to systems in steady state to estimate relationships among arrival rate, throughput, and response time.
Empirical Techniques
Load Testing− Simulating real-world load to identify the maximum handling capacity.
Simulation Modelling− Creating virtual models of systems to analyze resource utilization and traffic patterns.
Predictive Techniques−
Machine Learning Models− Leveraging historical data with predictive models to forecast capacity.
Time Series Analysis− Analyzing past workload patterns to predict future demand trends.
Tools for Capacity Estimation
Load Testing Tools
Apache JMeter− For simulating loads on networks and testing system performance.
Gatling− A high-performance load testing tool for web applications.
Monitoring and Analytics Tools
Prometheus & Grafana− Used for monitoring, alerting, and visualizing real-time metrics.
Datadog− Offers performance monitoring with real-time alerts for resource thresholds.
Capacity Planning and Forecasting Tools
Amazon CloudWatch− Provides monitoring and automatic scaling recommendations.
Google Stackdriver− Monitoring and logging for GCP, with resource-based capacity planning.
Custom Solutions− Building custom scripts and tools to collect, analyze, and forecast data specific to system needs.
Challenges in Capacity Estimation
Demand Uncertainty− Variability in demand and unpredictable spikes.
Changing System Architecture− Challenges when infrastructure or software changes.
Distributed Systems Complexity− Increased complexity when scaling distributed systems across regions or data centres.
Resource Dependencies− Complex interdependencies between resources that can lead to bottlenecks or scaling issues.
Cost-Benefit Balance− Balancing cost considerations against desired performance levels.
Best Practices for Effective Capacity Estimation
Regular Capacity Reviews− Conduct frequent reviews and updates to capacity plans based on evolving workloads.
Utilize Automation− Implement automated tools for load testing, monitoring, and scaling.
Build in Redundancy− Design systems with failover and redundancy to avoid single points of failure.
Monitor and Alert− Set up alerts for key metrics to catch bottlenecks early.
Collaborate with Stakeholders− Align capacity plans with business objectives, budget constraints, and expected growth.
Conclusion
Capacity estimation is a proactive step in systems design that ensures a balance between cost, performance, and user satisfaction. By understanding core concepts, employing effective estimation techniques, and using the right tools, system architects can forecast capacity needs and build robust, scalable systems. Capacity estimation is an ongoing process that, when done correctly, can yield cost savings, high performance, and optimal user experience.
Roles of Web Server and Proxies in Designing Systems
This article covers roles of web servers and proxies while preparing a system designs and architectures.
Understanding Web Servers
Definition
A web server is software or hardware that serves web content to clients over the internet.
Functionality
Handling HTTP requests and responses.
Storing and serving static content (HTML, CSS, JavaScript).
Running dynamic applications (e.g., through CGI, PHP, or frameworks like Spring Boot).
Examples of Web Servers
Apache Tomcat
Apache Http
Nginx
Microsoft IIS
Core Responsibilities of Web Servers
Content Delivery
Responding to requests for web pages and resources.
Serving static files and rendering dynamic content.
Resource Management
Managing connections and sessions.
Load balancing to handle multiple requests.
Security Features
HTTPS support through SSL/TLS.
Basic authentication and access control.
Understanding Proxies
Definition
A proxy server acts as an intermediary between a client and a destination server.
Types of Proxies
Forward proxies− Used by clients to access the internet.
Reverse proxies− Positioned in front of web servers to handle requests on their behalf.
Common Use Cases
Caching
Filtering
Content Delivery
Roles of Proxies
Performance Optimization
Caching frequently accessed content to reduce load times.
Reducing bandwidth usage by compressing content.
Security Enhancement
Hiding client IP addresses for anonymity.
Protecting against attacks (e.g., DDoS – Distributed Denial of Service).
Access Control
Filtering traffic based on rules (e.g., content filtering in organizations).
Enforcing company policies for web access.
Interplay Between Web Servers and Proxies
How They Work Together
Proxies forwarding requests to web servers and relaying responses back to clients.
Load balancing techniques involving multiple web servers behind a reverse proxy.
Real-world Example
You can discuss a scenario in which a proxy server is used to enhance the performance and security of a web server.
Challenges and Considerations
Web Server Challenges
Handling high traffic volumes.
Managing security vulnerabilities.
Proxy Challenges
Configuring proxies correctly for optimal performance.
Balancing anonymity and security with usability.
Best Practices
Regular updates and security patches for servers and proxies.
Implementing monitoring tools to track performance and security threats.
Advancements in Web Servers
Web servers are undergoing significant transformations driven by the need for speed and scalability. The rise of microservices architecture is pushing developers to adopt lightweight web servers that can efficiently handle numerous requests. Technologies such as Docker and Kubernetes facilitate containerization, allowing applications to run in isolated environments. This approach enhances resource utilization and simplifies deployment.
Moreover, the integration of serverless computing is revolutionizing the traditional web server model. Platforms like AWS Lambda and Azure Functions enable developers to run code in response to events without managing server infrastructure. This not only reduces operational overhead but also allows for automatic scaling based on demand.
Security remains a top priority, with advancements in TLS (Transport Layer Security) and HTTP/3 protocols enhancing data protection and reducing latency. The adoption of AI-driven security solutions is also on the rise, helping to identify and mitigate threats in real-time.
Clustering and Load Balancing
Introduction to Clustering and Load Balancing
Clustering and load balancing are essential for modern applications to ensure they are scalable, highly available, and perform well under varying loads. Here's why they are significant.
Clustering
High Availability− Clustering ensures that if one server goes down, others can take over, minimizing downtime and ensuring continuous availability.
Scalability− By adding more nodes to a cluster, applications can handle more users and more data without performance degradation.
Fault Tolerance− Clusters are designed to continue operating even when individual nodes fail, which enhances the resilience of the application.
Resource Management− Distributes workloads across multiple nodes, optimizing resource usage and preventing any single node from becoming a bottleneck.
Load Balancing
Efficient Resource Utilization− Load balancing distributes incoming traffic across multiple servers, ensuring that no single server is overwhelmed, which optimizes resource utilization.
Improved Performance− By balancing the load, applications can respond faster to user requests, enhancing the overall user experience.
Redundancy− Load balancing ensures that if one server fails, traffic can be redirected to other operational servers, providing redundancy.
Scalability− Easily scales by adding more servers to the pool, allowing applications to handle increasing traffic seamlessly.
Key Concepts of Clustering
Types of Clustering
High-Availability (HA) Clustering− For fault tolerance and minimal downtime.
Load Balancing Clustering− Distributing workloads to multiple nodes. If a node fails, the request is transferred to the next node.
Storage Clustering− For managing data in distributed systems.
Examples of clustering solutions− Kubernetes, Apache Kafka, Hadoop.
Key Concepts of Load Balancing
Objectives− Avoid overloading any single server, reduce response times, and optimize resource usage.
Types of Load Balancers
Hardware Load Balancers− Specialized devices.
Software Load Balancers− Run on commodity hardware or virtual instances.
DNS Load Balancing− Uses DNS (Domain Name System) to route requests to different servers.
Load Balancing Algorithms and Techniques
Round Robin− Requests are distributed sequentially across servers.
Least Connections− Directs traffic to the server with the fewest active connections.
Weighted Round Robin and Least Connections− Assigns weights to servers based on capacity.
IP Hashing− Routes requests based on the client’s IP address.
Random− Routes requests to random servers.
Dynamic Load Balancing− Adapts based on current server performance.
Tools and Technologies for Load Balancing
Nginx− A popular open-source reverse proxy and load balancer.
HAProxy− A fast and reliable load balancer for TCP and HTTP based applications.
AWS Elastic Load Balancing (ELB)− Load balancing for AWS resources, including EC2 and containers.
Azure Load Balancer− Manages traffic for applications on Microsoft Azure.
Traefik− A modern load balancer for microservices, with built-in support for Kubernetes.
Clustering Technologies and Architectures
Apache Kafka− A distributed streaming platform that supports clustering.
Kubernetes− Manages containerized applications and scales them automatically.
Apache Cassandra− A distributed NoSQL database designed for clustering and fault tolerance.
Active-Active vs. Active-Passive Clustering− In an active-active setup, all nodes (servers) in the cluster are actively processing requests simultaneously. In an active-passive setup, only one node (or a primary set of nodes) is actively handling requests at any time, while the other node(s) remain on standby.
Configuring Load Balancers for Different Applications
Web Applications− Using HTTP/HTTPS load balancing.
Database Load Balancing− Balancing read and write requests (e.g., with MySQL).
Microservices and APIs− Configuring API gateways with load balancing.
Real-time Applications− Configuring WebSocket load balancing for low latency.
Monitoring and Maintaining Clustering and Load Balancing Systems
Importance of Monitoring− Ensure uptime, performance, and detect issues.
Tools for Monitoring
Prometheus and Grafana− Metric collection and visualization.
Datadog and New Relic− End-to-end monitoring for cloud and on-premise environments.
ELK Stack− Logs analysis for load balancer and cluster events.
Common Maintenance Tasks− Updating configurations, scaling up/down, handling node failures.
Identifying and resolving common load balancing and clustering issues.
Here's a look at common issues that arise in load balancing and clustering, along with strategies to identify and resolve them. These issues often relate to misconfiguration, capacity limitations, and network constraints, and addressing them effectively helps maintain high availability and performance.
Uneven Load Distribution
Symptoms− Some servers experience high CPU or memory usage, while others remain underutilized.
Causes− This can be due to a poorly configured load balancing algorithm (e.g., Round Robin may not work well if servers have unequal processing capabilities) or an incorrect weighting setup in Weighted Round Robin or Least Connections algorithms.
Resolution
Adjust the load balancing algorithm to one that matches the application’s requirements. Use a Weighted Load Balancing approach to match server capacities.
For cloud-based solutions, consider auto-scaling policies to add resources automatically under high load conditions.
Session Persistence (Sticky Sessions) Issues
Sticky sessions, also known as session affinity, is a technique used in load balancing to ensure that a user's requests are always directed to the same server throughout a session.
Symptoms− Users are logged out unexpectedly or lose session data when redirected to different servers.
Causes− Load balancers may be configured without sticky sessions, leading to loss of session continuity if a user’s requests are routed to different servers.
Resolution
Enable session persistence (sticky sessions) on the load balancer to ensure that requests from a given client in the same session are routed to the same server.
For more scalable solutions, implement distributed session management (e.g., session data stored in a database or distributed cache like Redis) to avoid dependency on individual servers.
Configuration Drift
Symptoms− Inconsistent behaviour across nodes, such as different software versions or configurations.
Causes− Manual configuration changes lead to mismatches across cluster nodes.
Resolution
Use configuration management tools like Ansible, Puppet, or Chef to ensure consistent configurations across all nodes.
Implement infrastructure as code (IaC) practices, using tools like Terraform to enforce versioned and consistent configuration states.
DNS Caching Issues in DNS Load Balancing
Symptoms− Clients are directed to unhealthy nodes even after.
Causes− DNS caching at the client side or intermediary resolvers can keep IP mappings of decommissioned or faulty nodes.
Resolution
Reduce the Time-to-Live (TTL) on DNS records to ensure faster propagation of changes in DNS-based load balancers.
Use failover DNS records that redirect traffic to alternative nodes in case primary nodes are unreachable.
Logging and Monitoring Challenges
Symptoms− Lack of insight into traffic patterns, unbalanced loads, or delays in troubleshooting issues.
Causes− Inadequate monitoring or logging on the load balancer and clustering nodes.
Resolution
Integrate monitoring tools such as Prometheus, Grafana, or Datadog for real-time metrics.
Use centralized logging (e.g., ELK Stack or Fluentd) to aggregate logs from different nodes and provide unified access.
Set up alerting systems to notify administrators of unusual patterns, such as sudden traffic spikes, server failures, or high latencies.
Future of Clustering and Load Balancing
Trends in Clustering and Load Balancing
Edge Computing− Deploying clusters closer to data sources for latency reduction.
AI-driven Load Balancing− Using machine learning to optimize request routing.
Serverless Architectures− Impact of serverless on traditional load balancing.
Potential Challenges− Increased complexity in managing distributed systems, security concerns.
System Development Life Cycle
An effective System Development Life Cycle (SDLC) should result in a high quality system that meets customer expectations, reaches completion within time and cost evaluations, and works effectively and efficiently in the current and planned Information Technology infrastructure.
System Development Life Cycle (SDLC) is a conceptual model which includes policies and procedures for developing or altering systems throughout their life cycles.
SDLC is used by analysts to develop an information system. SDLC includes the following activities −
- requirements
- design
- implementation
- testing
- deployment
- operations
- maintenance
Phases of SDLC
Systems Development Life Cycle is a systematic approach which explicitly breaks down the work into phases that are required to implement either new or modified Information System.

Feasibility Study or Planning
Define the problem and scope of existing system.
Overview the new system and determine its objectives.
Confirm project feasibility and produce the project Schedule.
During this phase, threats, constraints, integration and security of system are also considered.
A feasibility report for the entire project is created at the end of this phase.
Analysis and Specification
Gather, analyze, and validate the information.
Define the requirements and prototypes for new system.
Evaluate the alternatives and prioritize the requirements.
Examine the information needs of end-user and enhances the system goal.
A Software Requirement Specification (SRS) document, which specifies the software, hardware, functional, and network requirements of the system is prepared at the end of this phase.
System Design
Includes the design of application, network, databases, user interfaces, and system interfaces.
Transform the SRS document into logical structure, which contains detailed and complete set of specifications that can be implemented in a programming language.
Create a contingency, training, maintenance, and operation plan.
Review the proposed design. Ensure that the final design must meet the requirements stated in SRS document.
Finally, prepare a design document which will be used during next phases.
Implementation
Implement the design into source code through coding.
Combine all the modules together into training environment that detects errors and defects.
A test report which contains errors is prepared through test plan that includes test related tasks such as test case generation, testing criteria, and resource allocation for testing.
Integrate the information system into its environment and install the new system.
Maintenance/Support
Include all the activities such as phone support or physical on-site support for users that is required once the system is installing.
Implement the changes that software might undergo over a period of time, or implement any new requirements after the software is deployed at the customer location.
It also includes handling the residual errors and resolve any issues that may exist in the system even after the testing phase.
Maintenance and support may be needed for a longer time for large systems and for a short time for smaller systems.
Life Cycle of System Analysis and Design
The following diagram shows the complete life cycle of the system during analysis and design phase.

Role of System Analyst
The system analyst is a person who is thoroughly aware of the system and guides the system development project by giving proper directions. He is an expert having technical and interpersonal skills to carry out development tasks required at each phase.
He pursues to match the objectives of information system with the organization goal.
Main Roles
Defining and understanding the requirement of user through various Fact finding techniques.
Prioritizing the requirements by obtaining user consensus.
Gathering the facts or information and acquires the opinions of users.
Maintains analysis and evaluation to arrive at appropriate system which is more user friendly.
Suggests many flexible alternative solutions, pick the best solution, and quantify cost and benefits.
Draw certain specifications which are easily understood by users and programmer in precise and detailed form.
Implemented the logical design of system which must be modular.
Plan the periodicity for evaluation after it has been used for some time, and modify the system as needed.
Attributes of a Systems Analyst
The following figure shows the attributes a systems analyst should possess −

Interpersonal Skills
- Interface with users and programmer.
- Facilitate groups and lead smaller teams.
- Managing expectations.
- Good understanding, communication, selling and teaching abilities.
- Motivator having the confidence to solve queries.
Analytical Skills
- System study and organizational knowledge
- Problem identification, problem analysis, and problem solving
- Sound commonsense
- Ability to access trade-off
- Curiosity to learn about new organization
Management Skills
- Understand users jargon and practices.
- Resource & project management.
- Change & risk management.
- Understand the management functions thoroughly.
Technical Skills
- Knowledge of computers and software.
- Keep abreast of modern development.
- Know of system design tools.
- Breadth knowledge about new technologies.
System Analysis and Design - Requirement Determination
Introduction
In the realm of systems analysis and design, requirement determination is a critical phase that sets the foundation for successful software development. It involves gathering, analyzing, and documenting the needs and expectations of stakeholders to ensure that the final system meets its intended purpose. This article explores the importance of requirement determination, its methodologies, challenges, and best practices, providing a comprehensive overview for both novice and experienced practitioners.
Importance of Requirement Determination
Requirement determination is essential for several reasons−
Clarity of Purpose− Clearly defined requirements help stakeholders understand the system's purpose and functionality, reducing ambiguity.
Stakeholder Satisfaction− Engaging stakeholders early and accurately capturing their needs leads to greater satisfaction with the final product.
Cost and Time Efficiency− Well-documented requirements minimize the risk of costly changes during later development stages, leading to a more efficient project lifecycle.
Risk Management− Identifying potential issues early allows teams to devise strategies to mitigate risks before they escalate.
Framework for Development− Requirements serve as a guide for system design, coding, testing, and implementation, ensuring alignment throughout the development process.
Methodologies for Requirement Determination
Several methodologies can be employed during the requirement determination phase, each with its strengths and weaknesses−
Interviews
Interviews involve direct discussions with stakeholders to elicit their needs and preferences. They can be structured, semi-structured, or unstructured, allowing for flexibility in gathering information.
Advantages
Direct insights from users.
Opportunity for follow-up questions and clarification.
Disadvantages
Time-consuming.
Potential for biased responses if not carefully managed.
Surveys and Questionnaires
Surveys allow for the collection of data from a larger group of stakeholders. They can be used to gather quantitative data, making it easier to analyse trends and common requirements.
Advantages
Reach a broad audience quickly.
Can provide statistical insights.
Disadvantages
Limited depth of information.
Potentially low response rates.
Workshops and Focus Groups
Workshops and focus groups gather stakeholders in a collaborative environment to discuss requirements. This method encourages interaction and can lead to creative solutions.
Advantages
Fosters collaboration and discussion.
Generates diverse ideas and perspectives.
Disadvantages
Dominant voices may overshadow quieter participants.
Requires skilled facilitation to be effective.
Observation
Observation involves studying users in their natural environment to understand how they interact with existing systems. This method can reveal hidden needs and workflows.
Advantages
Provides real-world context.
Can uncover issues that users may not articulate.
Disadvantages
Time-intensive.
Observer bias can affect findings.
Document Analysis
Reviewing existing documentation such as user manuals, system specifications, and business process diagrams can provide insights into current systems and inform new requirements.
Advantages
Leverages existing knowledge.
Identifies gaps in current systems.
Disadvantages
Documentation may be outdated or incomplete.
Requires expertise to interpret effectively.
Challenges in Requirement Determination
Despite its importance, requirement determination is fraught with challenges−
Changing Requirements− As projects evolve, stakeholders may change their minds about what they need, complicating the process.
Stakeholder Conflicts− Different stakeholders may have conflicting needs or priorities, making consensus difficult.
Communication Barriers− Misunderstandings can arise due to jargon, assumptions, or differing perspectives, leading to incomplete or incorrect requirements.
Incomplete Information− Stakeholders may not fully understand their needs, leading to gaps in the requirements.
Time Constraints− Tight project timelines can pressure teams to rush through the requirement determination phase, increasing the likelihood of errors.
Best Practices for Effective Requirement Determination
To overcome challenges and enhance the effectiveness of requirement determination, consider the following best practices−
Involve Stakeholders Early and Often− Engage users and stakeholders from the outset and maintain ongoing communication throughout the project.
Use Multiple Techniques− Employ a combination of methodologies to gather comprehensive insights and validate findings.
Document Requirements Clearly− Use clear, concise language and structured formats (e.g., use cases, user stories) to document requirements for easy reference.
Prioritize Requirements− Work with stakeholders to prioritize requirements based on business value, feasibility, and urgency, ensuring that critical needs are addressed first.
Conduct Regular Reviews− Schedule regular reviews of the requirements with stakeholders to validate and adjust as necessary, ensuring alignment throughout the project.
Leverage Prototyping− Use prototypes or wireframes to visualize requirements and gather feedback, helping stakeholders clarify their needs.
Maintain Traceability− Establish a traceability matrix to track requirements from initial gathering through design, development, and testing, ensuring that all requirements are met.
Conclusion
Requirement determination is a vital step in the systems analysis and design process. By understanding its importance, employing appropriate methodologies, addressing challenges, and following best practices, organizations can significantly enhance the likelihood of project success. A well-executed requirement determination phase not only leads to a system that meets user needs but also fosters collaboration, reduces risks, and ultimately contributes to stakeholder satisfaction and business success.
System Analysis and Design - Systems Implementation
Introduction
Definition and significance of systems implementation in project management and IT.
Role in bridging the gap between design and operation.
Overview of the key steps in implementing a new system.
Planning for Implementation
Defining Scope and Objectives
Understanding project goals.
Importance of aligning implementation with business strategy.
Resource Allocation
Identifying resources (human, technical, and financial).
Resource planning and timeline management.
Risk Assessment
Recognizing potential implementation risks.
Establishing contingency plans to mitigate risks.
Choosing the Right Implementation Approach
Big Bang Approach
Replacing old systems with new ones at once.
Pros and cons of immediate transition.
Phased Implementation
Gradual deployment in stages.
Benefits of controlling scope and user adaptation.
Parallel Implementation
Running old and new systems concurrently.
Advantages for validation and testing.
Pilot Implementation
Deploying the system in a limited area to assess performance.
Benefits in risk reduction before full-scale roll-out.
Preparing for Change
Change Management
Building a culture open to system changes.
Strategies for managing resistance to new systems.
Training Programs
Designing training to ensure users are proficient.
Role of continuous learning and support in successful implementation.
Communication Planning
Keeping stakeholders informed throughout implementation.
Techniques for clear, transparent communication.
Testing and Quality Assurance
Importance of Testing
Types of testing (e.g., unit testing, integration testing, user acceptance testing).
Ensuring reliability and performance before going live.
User Acceptance Testing (UAT)
Importance of user validation in real-world scenarios.
Collecting feedback and refining the system.
Quality Control Measures
Defining benchmarks for performance and user satisfaction.
Implementing feedback loops for continuous improvement.
System Go-Live and Rollout
Final Preparations
Verifying system functionality and security.
Setting up data migration and backup processes.
Executing the Rollout
Following a clear, documented go-live strategy.
Monitoring performance and managing user inquiries.
Post-Implementation Support
Helpdesk and technical support plans.
Importance of rapid response to issues post-rollout.
Evaluation and Monitoring
Assessing System Performance
Metrics to evaluate functionality, speed, and reliability.
Gathering quantitative and qualitative data.
User Feedback and Adaptations
Collecting user feedback to gauge satisfaction.
Planning updates or modifications based on real user needs.
Maintenance and Continuous Improvement
Establishing a maintenance schedule for ongoing reliability.
Identifying opportunities for system enhancement.
Case Studies and Best Practices
Examples of Successful Implementations
Brief case studies highlighting varied approaches (e.g., phased, pilot).
Lessons Learned
Common challenges and how to overcome them.
Best practices for seamless implementation.
Conclusion
Recap of the critical steps in systems implementation−
Emphasis on the strategic importance of careful planning and execution.
Final thoughts on the role of flexibility and adaptability in successful implementations.
System Analysis & Design - System Planning
What is Requirements Determination?
A requirement is a vital feature of a new system which may include processing or capturing of data, controlling the activities of business, producing information and supporting the management.
Requirements determination involves studying the existing system and gathering details to find out what are the requirements, how it works, and where improvements should be made.
Major Activities in requirement Determination
Requirements Anticipation
It predicts the characteristics of system based on previous experience which include certain problems or features and requirements for a new system.
It can lead to analysis of areas that would otherwise go unnoticed by inexperienced analyst. But if shortcuts are taken and bias is introduced in conducting the investigation, then requirement Anticipation can be half-baked.
Requirements Investigation
It is studying the current system and documenting its features for further analysis.
It is at the heart of system analysis where analyst documenting and describing system features using fact-finding techniques, prototyping, and computer assisted tools.
Requirements Specifications
It includes the analysis of data which determine the requirement specification, description of features for new system, and specifying what information requirements will be provided.
It includes analysis of factual data, identification of essential requirements, and selection of Requirement-fulfillment strategies.
Information Gathering Techniques
The main aim of fact finding techniques is to determine the information requirements of an organization used by analysts to prepare a precise SRS understood by user.
Ideal SRS Document should −
- be complete, Unambiguous, and Jargon-free.
- specify operational, tactical, and strategic information requirements.
- solve possible disputes between users and analyst.
- use graphical aids which simplify understanding and design.
There are various information gathering techniques −
Interviewing
Systems analyst collects information from individuals or groups by interviewing. The analyst can be formal, legalistic, play politics, or be informal; as the success of an interview depends on the skill of analyst as interviewer.
It can be done in two ways −
Unstructured Interview − The system analyst conducts question-answer session to acquire basic information of the system.
Structured Interview − It has standard questions which user need to respond in either close (objective) or open (descriptive) format.
Advantages of Interviewing
This method is frequently the best source of gathering qualitative information.
It is useful for them, who do not communicate effectively in writing or who may not have the time to complete questionnaire.
Information can easily be validated and cross checked immediately.
It can handle the complex subjects.
It is easy to discover key problem by seeking opinions.
It bridges the gaps in the areas of misunderstandings and minimizes future problems.
Questionnaires
This method is used by analyst to gather information about various issues of system from large number of persons.
There are two types of questionnaires −
Open-ended Questionnaires − It consists of questions that can be easily and correctly interpreted. They can explore a problem and lead to a specific direction of answer.
Closed-ended Questionnaires − It consists of questions that are used when the systems analyst effectively lists all possible responses, which are mutually exclusive.
Advantages of questionnaires
It is very effective in surveying interests, attitudes, feelings, and beliefs of users which are not co-located.
It is useful in situation to know what proportion of a given group approves or disapproves of a particular feature of the proposed system.
It is useful to determine the overall opinion before giving any specific direction to the system project.
It is more reliable and provides high confidentiality of honest responses.
It is appropriate for electing factual information and for statistical data collection which can be emailed and sent by post.
Review of Records, Procedures, and Forms
Review of existing records, procedures, and forms helps to seek insight into a system which describes the current system capabilities, its operations, or activities.
Advantages
It helps user to gain some knowledge about the organization or operations by themselves before they impose upon others.
It helps in documenting current operations within short span of time as the procedure manuals and forms describe the format and functions of present system.
It can provide a clear understanding about the transactions that are handled in the organization, identifying input for processing, and evaluating performance.
It can help an analyst to understand the system in terms of the operations that must be supported.
It describes the problem, its affected parts, and the proposed solution.
Observation
This is a method of gathering information by noticing and observing the people, events, and objects. The analyst visits the organization to observe the working of current system and understands the requirements of the system.
Advantages
It is a direct method for gleaning information.
It is useful in situation where authenticity of data collected is in question or when complexity of certain aspects of system prevents clear explanation by end-users.
It produces more accurate and reliable data.
It produces all the aspect of documentation that are incomplete and outdated.
Joint Application Development (JAD)
It is a new technique developed by IBM which brings owners, users, analysts, designers, and builders to define and design the system using organized and intensive workshops. JAD trained analyst act as facilitator for workshop who has some specialized skills.
Advantages of JAD
It saves time and cost by replacing months of traditional interviews and follow-up meetings.
It is useful in organizational culture which supports joint problem solving.
Fosters formal relationships among multiple levels of employees.
It can lead to development of design creatively.
It Allows rapid development and improves ownership of information system.
Secondary Research or Background Reading
This method is widely used for information gathering by accessing the gleaned information. It includes any previously gathered information used by the marketer from any internal or external source.
Advantages
It is more openly accessed with the availability of internet.
It provides valuable information with low cost and time.
It act as forerunner to primary research and aligns the focus of primary research.
It is used by the researcher to conclude if the research is worth it as it is available with procedures used and issues in collecting them.
Feasibility Study
Feasibility Study can be considered as preliminary investigation that helps the management to take decision about whether study of system should be feasible for development or not.
It identifies the possibility of improving an existing system, developing a new system, and produce refined estimates for further development of system.
It is used to obtain the outline of the problem and decide whether feasible or appropriate solution exists or not.
The main objective of a feasibility study is to acquire problem scope instead of solving the problem.
The output of a feasibility study is a formal system proposal act as decision document which includes the complete nature and scope of the proposed system.
Steps Involved in Feasibility Analysis
The following steps are to be followed while performing feasibility analysis −
Form a project team and appoint a project leader.
Develop system flowcharts.
Identify the deficiencies of current system and set goals.
Enumerate the alternative solution or potential candidate system to meet goals.
Determine the feasibility of each alternative such as technical feasibility, operational feasibility, etc.
Weight the performance and cost effectiveness of each candidate system.
Rank the other alternatives and select the best candidate system.
Prepare a system proposal of final project directive to management for approval.

Types of Feasibilities
Economic Feasibility
It is evaluating the effectiveness of candidate system by using cost/benefit analysis method.
It demonstrates the net benefit from the candidate system in terms of benefits and costs to the organization.
The main aim of Economic Feasibility Analysis (EFS) is to estimate the economic requirements of candidate system before investments funds are committed to proposal.
It prefers the alternative which will maximize the net worth of organization by earliest and highest return of funds along with lowest level of risk involved in developing the candidate system.
Technical Feasibility
It investigates the technical feasibility of each implementation alternative.
It analyzes and determines whether the solution can be supported by existing technology or not.
The analyst determines whether current technical resources be upgraded or added it that fulfill the new requirements.
It ensures that the candidate system provides appropriate responses to what extent it can support the technical enhancement.
Operational Feasibility
It determines whether the system is operating effectively once it is developed and implemented.
It ensures that the management should support the proposed system and its working feasible in the current organizational environment.
It analyzes whether the users will be affected and they accept the modified or new business methods that affect the possible system benefits.
It also ensures that the computer resources and network architecture of candidate system are workable.
Behavioral Feasibility
It evaluates and estimates the user attitude or behavior towards the development of new system.
It helps in determining if the system requires special effort to educate, retrain, transfer, and changes in employee’s job status on new ways of conducting business.
Schedule Feasibility
It ensures that the project should be completed within given time constraint or schedule.
It also verifies and validates whether the deadlines of project are reasonable or not.
Structured Analysis
Analysts use various tools to understand and describe the information system. One of the ways is using structured analysis.
What is Structured Analysis?
Structured Analysis is a development method that allows the analyst to understand the system and its activities in a logical way.
It is a systematic approach, which uses graphical tools that analyze and refine the objectives of an existing system and develop a new system specification which can be easily understandable by user.
It has following attributes −
It is graphic which specifies the presentation of application.
It divides the processes so that it gives a clear picture of system flow.
It is logical rather than physical i.e., the elements of system do not depend on vendor or hardware.
It is an approach that works from high-level overviews to lower-level details.
Structured Analysis Tools
During Structured Analysis, various tools and techniques are used for system development. They are −
- Data Flow Diagrams
- Data Dictionary
- Decision Trees
- Decision Tables
- Structured English
- Pseudocode

Data Flow Diagrams (DFD) or Bubble Chart
It is a technique developed by Larry Constantine to express the requirements of system in a graphical form.
It shows the flow of data between various functions of system and specifies how the current system is implemented.
It is an initial stage of design phase that functionally divides the requirement specifications down to the lowest level of detail.
Its graphical nature makes it a good communication tool between user and analyst or analyst and system designer.
It gives an overview of what data a system processes, what transformations are performed, what data are stored, what results are produced and where they flow.
Basic Elements of DFD
DFD is easy to understand and quite effective when the required design is not clear and the user wants a notational language for communication. However, it requires a large number of iterations for obtaining the most accurate and complete solution.
The following table shows the symbols used in designing a DFD and their significance −
| Symbol Name | Symbol | Meaning |
|---|---|---|
| Square |  |
Source or Destination of Data |
| Arrow | Data flow | |
| Circle |  |
Process transforming data flow |
| Open Rectangle |  |
Data Store |
Types of DFD
DFDs are of two types: Physical DFD and Logical DFD. The following table lists the points that differentiate a physical DFD from a logical DFD.
| Physical DFD | Logical DFD |
|---|---|
| It is implementation dependent. It shows which functions are performed. | It is implementation independent. It focuses only on the flow of data between processes. |
| It provides low level details of hardware, software, files, and people. | It explains events of systems and data required by each event. |
| It depicts how the current system operates and how a system will be implemented. | It shows how business operates; not how the system can be implemented. |
Context Diagram
A context diagram helps in understanding the entire system by one DFD which gives the overview of a system. It starts with mentioning major processes with little details and then goes onto giving more details of the processes with the top-down approach.
The context diagram of mess management is shown below.
Data Dictionary
A data dictionary is a structured repository of data elements in the system. It stores the descriptions of all DFD data elements that is, details and definitions of data flows, data stores, data stored in data stores, and the processes.
A data dictionary improves the communication between the analyst and the user. It plays an important role in building a database. Most DBMSs have a data dictionary as a standard feature. For example, refer the following table −
| Sr.No. | Data Name | Description | No. of Characters |
|---|---|---|---|
| 1 | ISBN | ISBN Number | 10 |
| 2 | TITLE | title | 60 |
| 3 | SUB | Book Subjects | 80 |
| 4 | ANAME | Author Name | 15 |
Decision Trees
Decision trees are a method for defining complex relationships by describing decisions and avoiding the problems in communication. A decision tree is a diagram that shows alternative actions and conditions within horizontal tree framework. Thus, it depicts which conditions to consider first, second, and so on.
Decision trees depict the relationship of each condition and their permissible actions. A square node indicates an action and a circle indicates a condition. It forces analysts to consider the sequence of decisions and identifies the actual decision that must be made.
The major limitation of a decision tree is that it lacks information in its format to describe what other combinations of conditions you can take for testing. It is a single representation of the relationships between conditions and actions.
For example, refer the following decision tree −

Decision Tables
Decision tables are a method of describing the complex logical relationship in a precise manner which is easily understandable.
It is useful in situations where the resulting actions depend on the occurrence of one or several combinations of independent conditions.
It is a matrix containing row or columns for defining a problem and the actions.
Components of a Decision Table
Condition Stub − It is in the upper left quadrant which lists all the condition to be checked.
Action Stub − It is in the lower left quadrant which outlines all the action to be carried out to meet such condition.
Condition Entry − It is in upper right quadrant which provides answers to questions asked in condition stub quadrant.
Action Entry − It is in lower right quadrant which indicates the appropriate action resulting from the answers to the conditions in the condition entry quadrant.
The entries in decision table are given by Decision Rules which define the relationships between combinations of conditions and courses of action. In rules section,
- Y shows the existence of a condition.
- N represents the condition, which is not satisfied.
- A blank - against action states it is to be ignored.
- X (or a check mark will do) against action states it is to be carried out.
For example, refer the following table −
| CONDITIONS | Rule 1 | Rule 2 | Rule 3 | Rule 4 |
|---|---|---|---|---|
| Advance payment made | Y | N | N | N |
| Purchase amount = Rs 10,000/- | - | Y | Y | N |
| Regular Customer | - | Y | N | - |
| ACTIONS | ||||
| Give 5% discount | X | X | - | - |
| Give no discount | - | - | X | X |
Structured English
Structure English is derived from structured programming language which gives more understandable and precise description of process. It is based on procedural logic that uses construction and imperative sentences designed to perform operation for action.
It is best used when sequences and loops in a program must be considered and the problem needs sequences of actions with decisions.
It does not have strict syntax rule. It expresses all logic in terms of sequential decision structures and iterations.
For example, see the following sequence of actions −
if customer pays advance
then
Give 5% Discount
else
if purchase amount >=10,000
then
if the customer is a regular customer
then Give 5% Discount
else No Discount
end if
else No Discount
end if
end if
Pseudocode
A pseudocode does not conform to any programming language and expresses logic in plain English.
It may specify the physical programming logic without actual coding during and after the physical design.
It is used in conjunction with structured programming.
It replaces the flowcharts of a program.
Guidelines for Selecting Appropriate Tools
Use the following guidelines for selecting the most appropriate tool that would suit your requirements −
Use DFD at high or low level analysis for providing good system documentations.
Use data dictionary to simplify the structure for meeting the data requirement of the system.
Use structured English if there are many loops and actions are complex.
Use decision tables when there are a large number of conditions to check and logic is complex.
Use decision trees when sequencing of conditions is important and if there are few conditions to be tested.
System Analysis & Design - System Design
System design is the phase that bridges the gap between problem domain and the existing system in a manageable way. This phase focuses on the solution domain, i.e. “how to implement?”
It is the phase where the SRS document is converted into a format that can be implemented and decides how the system will operate.
In this phase, the complex activity of system development is divided into several smaller sub-activities, which coordinate with each other to achieve the main objective of system development.

Inputs to System Design
System design takes the following inputs −
Statement of work
Requirement determination plan
Current situation analysis
Proposed system requirements including a conceptual data model, modified DFDs, and Metadata (data about data).
Outputs for System Design
System design gives the following outputs −
Infrastructure and organizational changes for the proposed system.
A data schema, often a relational schema.
Metadata to define the tables/files and columns/data-items.
A function hierarchy diagram or web page map that graphically describes the program structure.
Actual or pseudocode for each module in the program.
A prototype for the proposed system.
Types of System Design
Logical Design
Logical design pertains to an abstract representation of the data flow, inputs, and outputs of the system. It describes the inputs (sources), outputs (destinations), databases (data stores), procedures (data flows) all in a format that meets the user requirements.
While preparing the logical design of a system, the system analyst specifies the user needs at level of detail that virtually determines the information flow into and out of the system and the required data sources. Data flow diagram, E-R diagram modeling are used.
Physical Design
Physical design relates to the actual input and output processes of the system. It focuses on how data is entered into a system, verified, processed, and displayed as output.
It produces the working system by defining the design specification that specifies exactly what the candidate system does. It is concerned with user interface design, process design, and data design.
It consists of the following steps −
Specifying the input/output media, designing the database, and specifying backup procedures.
Planning system implementation.
Devising a test and implementation plan, and specifying any new hardware and software.
Updating costs, benefits, conversion dates, and system constraints.
Architectural Design
It is also known as high level design that focuses on the design of system architecture. It describes the structure and behavior of the system. It defines the structure and relationship between various modules of system development process.
Detailed Design
It follows Architectural design and focuses on development of each module.
Conceptual Data Modeling
It is representation of organizational data which includes all the major entities and relationship. System analysts develop a conceptual data model for the current system that supports the scope and requirement for the proposed system.
The main aim of conceptual data modeling is to capture as much meaning of data as possible. Most organization today use conceptual data modeling using E-R model which uses special notation to represent as much meaning about data as possible.
Entity Relationship Model
It is a technique used in database design that helps describe the relationship between various entities of an organization.
Terms used in E-R model
ENTITY − It specifies distinct real world items in an application. For example: vendor, item, student, course, teachers, etc.
RELATIONSHIP − They are the meaningful dependencies between entities. For example, vendor supplies items, teacher teaches courses, then supplies and course are relationship.
ATTRIBUTES − It specifies the properties of relationships. For example, vendor code, student name. Symbols used in E-R model and their respective meanings −
The following table shows the symbols used in E-R model and their significance −
| Symbol | Meaning |
|---|---|
 |
Entity |
 |
Weak Entity |
 |
Relationship |
 |
Identity Relationship |
 |
Attributes |
 |
Key Attributes |
 |
Multivalued |
 |
Composite Attribute |
 |
Derived Attributes |
 |
Total Participation of E2 in R |
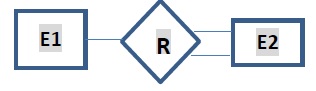 |
Cardinality Ratio 1:N for E1:E2 in R |
Three types of relationships can exist between two sets of data: one-to-one, one-to-many, and many-to-many.
File Organization
It describes how records are stored within a file.
There are four file organization methods −
Serial − Records are stored in chronological order (in order as they are input or occur). Examples − Recording of telephone charges, ATM transactions, Telephone queues.
Sequential − Records are stored in order based on a key field which contains a value that uniquely identifies a record. Examples − Phone directories.
Direct (relative) − Each record is stored based on a physical address or location on the device. Address is calculated from the value stored in the record’s key field. Randomizing routine or hashing algorithm does the conversion.
Indexed − Records can be processed both sequentially and non-sequentially using indexes.
Comparision

File Access
One can access a file using either Sequential Access or Random Access. File Access methods allow computer programs read or write records in a file.
Sequential Access
Every record on the file is processed starting with the first record until End of File (EOF) is reached. It is efficient when a large number of the records on the file need to be accessed at any given time. Data stored on a tape (sequential access) can be accessed only sequentially.
Direct (Random) Access
Records are located by knowing their physical locations or addresses on the device rather than their positions relative to other records. Data stored on a CD device (direct-access) can be accessed either sequentially or randomly.
Types of Files used in an Organization System
Following are the types of files used in an organization system −
Master file − It contains the current information for a system. For example, customer file, student file, telephone directory.
Table file − It is a type of master file that changes infrequently and stored in a tabular format. For example, storing Zipcode.
Transaction file − It contains the day-to-day information generated from business activities. It is used to update or process the master file. For example, Addresses of the employees.
Temporary file − It is created and used whenever needed by a system.
Mirror file − They are the exact duplicates of other files. Help minimize the risk of downtime in cases when the original becomes unusable. They must be modified each time the original file is changed.
Log files − They contain copies of master and transaction records in order to chronicle any changes that are made to the master file. It facilitates auditing and provides mechanism for recovery in case of system failure.
Archive files − Backup files that contain historical versions of other files.
Documentation Control
Documentation is a process of recording the information for any reference or operational purpose. It helps users, managers, and IT staff, who require it. It is important that prepared document must be updated on regular basis to trace the progress of the system easily.
After the implementation of system if the system is working improperly, then documentation helps the administrator to understand the flow of data in the system to correct the flaws and get the system working.
Programmers or systems analysts usually create program and system documentation. Systems analysts usually are responsible for preparing documentation to help users learn the system. In large companies, a technical support team that includes technical writers might assist in the preparation of user documentation and training materials.
Advantages
It can reduce system downtime, cut costs, and speed up maintenance tasks.
It provides the clear description of formal flow of present system and helps to understand the type of input data and how the output can be produced.
It provides effective and efficient way of communication between technical and nontechnical users about system.
It facilitates the training of new user so that he can easily understand the flow of system.
It helps the user to solve the problems such as troubleshooting and helps the manager to take better final decisions of the organization system.
It provides better control to the internal or external working of the system.
Types of Documentations
When it comes to System Design, there are following four main documentations −
- Program documentation
- System documentation
- Operations documentation
- User documentation
Program Documentation
It describes inputs, outputs, and processing logic for all the program modules.
The program documentation process starts in the system analysis phase and continues during implementation.
This documentation guides programmers, who construct modules that are well supported by internal and external comments and descriptions that can be understood and maintained easily.
Operations Documentation
Operations documentation contains all the information needed for processing and distributing online and printed output. Operations documentation should be clear, concise, and available online if possible.
It includes the following information −
Program, systems analyst, programmer, and system identification.
Scheduling information for printed output, such as report, execution frequency, and deadlines.
Input files, their source, output files, and their destinations.
E-mail and report distribution lists.
Special forms required, including online forms.
Error and informational messages to operators and restart procedures.
Special instructions, such as security requirements.
User Documentation
It includes instructions and information to the users who will interact with the system. For example, user manuals, help guides, and tutorials. User documentation is valuable in training users and for reference purpose. It must be clear, understandable, and readily accessible to users at all levels.
The users, system owners, analysts, and programmers, all put combined efforts to develop a user’s guide.
A user documentation should include −
A system overview that clearly describes all major system features, capabilities, and limitations.
Description of source document content, preparation, processing, and, samples.
Overview of menu and data entry screen options, contents, and processing instructions.
Examples of reports that are produced regularly or available at the user’s request, including samples.
Security and audit trail information.
Explanation of responsibility for specific input, output, or processing requirements.
Procedures for requesting changes and reporting problems.
Examples of exceptions and error situations.
Frequently asked questions (FAQs).
Explanation of how to get help and procedures for updating the user manual.
System Documentation
System documentation serves as the technical specifications for the IS and how the objectives of the IS are accomplished. Users, managers and IS owners need never reference system documentation. System documentation provides the basis for understanding the technical aspects of the IS when modifications are made.
It describes each program within the IS and the entire IS itself.
It describes the system’s functions, the way they are implemented, each program's purpose within the entire IS with respect to the order of execution, information passed to and from programs, and overall system flow.
It includes data dictionary entries, data flow diagrams, object models, screen layouts, source documents, and the systems request that initiated the project.
Most of the system documentation is prepared during the system analysis and system design phases.
During systems implementation, an analyst must review system documentation to verify that it is complete, accurate, and up-to-date, and including any changes made during the implementation process.
Design Strategies
Top-Down Strategy
The top-down strategy uses the modular approach to develop the design of a system. It is called so because it starts from the top or the highest-level module and moves towards the lowest level modules.
In this technique, the highest-level module or main module for developing the software is identified. The main module is divided into several smaller and simpler submodules or segments based on the task performed by each module. Then, each submodule is further subdivided into several submodules of next lower level. This process of dividing each module into several submodules continues until the lowest level modules, which cannot be further subdivided, are not identified.

Bottom-Up Strategy
Bottom-Up Strategy follows the modular approach to develop the design of the system. It is called so because it starts from the bottom or the most basic level modules and moves towards the highest level modules.
In this technique,
The modules at the most basic or the lowest level are identified.
These modules are then grouped together based on the function performed by each module to form the next higher-level modules.
Then, these modules are further combined to form the next higher-level modules.
This process of grouping several simpler modules to form higher level modules continues until the main module of system development process is achieved.
Structured Design
Structured design is a data-flow based methodology that helps in identifying the input and output of the developing system. The main objective of structured design is to minimize the complexity and increase the modularity of a program. Structured design also helps in describing the functional aspects of the system.
In structured designing, the system specifications act as a basis for graphically representing the flow of data and sequence of processes involved in a software development with the help of DFDs. After developing the DFDs for the software system, the next step is to develop the structure chart.

Modularization
Structured design partitions the program into small and independent modules. These are organized in top down manner with the details shown in bottom.
Thus, structured design uses an approach called Modularization or decomposition to minimize the complexity and to manage the problem by subdividing it into smaller segments.
Advantages
- Critical interfaces are tested first.
- It provide abstraction.
- It allows multiple programmers to work simultaneously.
- It allows code reuse.
- It provides control and improves morale.
- It makes identifying structure easier.
Structured Charts
Structured charts are a recommended tool for designing a modular, top down systems which define the various modules of system development and the relationship between each module. It shows the system module and their relationship between them.
It consists of diagram consisting of rectangular boxes that represent the modules, connecting arrows, or lines.
Control Module − It is a higher-level module that directs lower-level modules, called subordinate modules.
Library Module − It is a reusable module and can be invoked from more than one point in the chart.
We have two different approaches to design a structured chart −
Transform-Centered Structured Charts − They are used when all the transactions follow same path.
Transaction–Centered Structured Charts − They are used when all the transactions do not follow the same path.
Objectives of Using Structure Flowcharts
To encourage a top-down design.
To support the concept of modules and identify the appropriate modules.
To show the size and complexity of the system.
To identify the number of readily identifiable functions and modules within each function.
To depict whether each identifiable function is a manageable entity or should be broken down into smaller components.
Factors Affecting System Complexity
To develop good quality of system software, it is necessary to develop a good design. Therefore, the main focus on while developing the design of the system is the quality of the software design. A good quality software design is the one, which minimizes the complexity and cost expenditure in software development.
The two important concepts related to the system development that help in determining the complexity of a system are coupling and cohesion.
Coupling
Coupling is the measure of the independence of components. It defines the degree of dependency of each module of system development on the other. In practice, this means the stronger the coupling between the modules in a system, the more difficult it is to implement and maintain the system.
Each module should have simple, clean interface with other modules, and that the minimum number of data elements should be shared between modules.
High Coupling
These type of systems have interconnections with program units dependent on each other. Changes to one subsystem leads to high impact on the other subsystem.

Low Coupling
These type of systems are made up of components which are independent or almost independent. A change in one subsystem does not affect any other subsystem.
Coupling Measures
Content Coupling − When one component actually modifies another,then the modified component is completely dependent on modifying one.
Common Coupling − When amount of coupling is reduced somewhat by organizing system design so that data are accessible from a common data store.
Control Coupling − When one component passes parameters to control the activity of another component.
Stamp Coupling − When data structures is used to pass information from one component to another.
Data Coupling − When only data is passed then components are connected by this coupling.
Cohesion
Cohesion is the measure of closeness of the relationship between its components. It defines the amount of dependency of the components of a module on one another. In practice, this means the systems designer must ensure that −
They do not split essential processes into fragmented modules.
They do not gather together unrelated processes represented as processes on the DFD into meaningless modules.
The best modules are those that are functionally cohesive. The worst modules are those that are coincidentally cohesive.
The worst degree of cohesion
Coincidental cohesion is found in a component whose parts are unrelated to another.
Logical Cohesion − It is where several logically related functions or data elements are placed in same component.
Temporal Cohesion − It is when a component that is used to initialize a system or set variables performs several functions in sequence, but the functions are related by timing involved.
Procedurally Cohesion − It is when functions are grouped together in a component just to ensure this order.
Sequential Cohesion − It is when the output from one part of a component is the input to the next part of it.
System Analysis and Design - Software Deployment
Introduction
Software deployment is the process of releasing and installing software applications or updates onto target environments, such as production servers, user devices, or cloud infrastructure, to make them available for end-users or customers. It encompasses several stages, including preparation, installation, configuration, testing, and sometimes post-deployment support.
In the Software Development Life Cycle (SDLC), deployment is a critical phase that enables the transition of software from development to a live, operational state, delivering its value to users. The deployment process can vary based on the project's complexity and the organizational approach to software management (such as agile or DevOps practices).
Here's an overview of its importance within the SDLC−
Realizing Value for Users
Objective of the SDLC− Each phase in the SDLC (like planning, design, development, and testing) is aimed at building a product that meets user needs. However, deployment is where this work is actually realized and presented to end-users, making it the culmination of all previous phases.
Impact on Business− Deployment is essential for delivering new features, resolving bugs, and applying improvements, which directly impacts customer satisfaction and business value.
Ensuring Stability and Reliability in Production
Risk Management− Controlled deployment allows organizations to manage risks associated with changes in live environments. By using methods like staged rollouts or blue-green deployments, issues are minimized, leading to higher stability.
Quality Assurance− Even though testing is completed before deployment, the deployment process often includes final checks, environment-specific configurations, and monitoring, ensuring the application is stable in the production environment.
Supporting Continuous Integration and Delivery (CI/CD)
Agility and Responsiveness− In modern SDLC practices, particularly agile and DevOps, deployment is closely tied to CI/CD pipelines, where code changes are automatically tested and deployed. This allows frequent updates, helping businesses respond quickly to user feedback and market demands.
Automation Benefits− Automation in deployment minimizes human error, improves consistency, and speeds up the deployment process, aligning with the goals of CI/CD.
Enhancing Security and Compliance
Security Patches and Updates− Deployment is crucial for ensuring that applications are secure and up-to-date. Timely deployment of security patches prevents vulnerabilities from being exploited.
Compliance− For many industries, compliance standards require specific deployment practices and documentation, which are integral to achieving regulatory compliance.
Optimizing Resource Utilization and Cost Efficiency
Efficient Use of Resources− Automated and well-planned deployment pipelines help reduce downtime, freeing up resources for other development and operational tasks.
Cost Savings− Deployment optimizations—like zero-downtime strategies or containerization—can reduce costs by minimizing disruptions and maximizing resource efficiency in production.
Facilitating Feedback for Improvement
Post-Deployment Monitoring− Deployment also sets the stage for observing application performance and gathering user feedback in real-world conditions. This feedback loop is essential for continuous improvement and planning for future development cycles.
Issue Identification− Issues that may not be evident in a testing environment can surface during deployment, providing insights for refining both the software and the SDLC process itself.
Types of Software Deployment Models
On-Premises Deployment− Traditional model where software is deployed within an organization’s infrastructure.
Cloud Deployment− Using cloud providers like AWS, Azure, Google Cloud.
Hybrid Deployment− Combination of on-premises and cloud solutions.
Continuous Deployment (CD)− Introduction to CI/CD pipelines and automated deployment.
Containerized Deployment− Use of Docker, Kubernetes, and other containerization tools.
Deployment Strategies and Approaches
Blue-Green Deployment− Running two identical environments to reduce downtime.
Canary Release− Gradually rolling out updates to a subset of users.
Rolling Deployment− Incrementally deploying to parts of a system to reduce risk.
A/B Testing− Deploying different versions to measure performance and user response.
Feature Toggles− Enabling features for certain users without full deployment.
Key Components of the Deployment Process
Build Automation− Tools and practices for automating builds (e.g., Jenkins, GitLab CI).
Configuration Management− Managing software environments (e.g., Ansible, Chef).
Testing in Deployment− Types of testing (e.g., smoke testing, regression testing).
Release Management− Tracking versions, documentation, and release notes.
Monitoring and Logging− Tools and strategies for tracking application health (e.g., Prometheus, Grafana, ELK Stack comprising of Elastic search, Logstash, Kibana and lastly Datadog)
Tools and Technologies in Software Deployment
CI/CD Tools− Jenkins, CircleCI, GitLab CI/CD, etc.
Configuration Management Tools− Ansible, Puppet, Chef.
Containerization Tools− Docker, Kubernetes, Helm.
Cloud Platforms− AWS, Azure, Google Cloud for deployment automation.
Monitoring Tools− Grafana, Prometheus, ELK stack for observability.
Version Control Systems− Git, SVN to manage deployment code versions.
Challenges in Software Deployment
Environment Parity− Differences between development, testing, and production environments.
Rollbacks and Failures− Handling deployment failures and ensuring system stability.
Security Concerns− Securing deployment pipelines and managing sensitive data.
Dependency Management− Dealing with version conflicts and library dependencies.
Scaling and Load Management− Challenges of deploying updates to scalable systems.
Best Practices for Effective Deployment
Automation− Importance of automating repetitive deployment tasks.
Testing− Continuous integration and testing before deployment.
Documentation− Keeping clear, up-to-date deployment documentation.
Monitoring− Establishing robust monitoring and alerting systems.
Rollback Plans− Preparing strategies for quick rollback if needed.
Future of Software Deployment
Edge Computing and Deployment− Deploying software close to data sources for reduced latency.
Serverless Deployment− Using FaaS (Functions as a Service) and serverless platforms.
Artificial Intelligence in Deployment− Predictive analytics for deployment optimization.
Evolution of CI/CD− Continuous everything (CI/CD/CT) and its role in deployment.
Conclusion
In essence, deployment is where the software fulfils its intended purpose, delivering its benefits to end-users and enabling businesses to gain from their investment. A smooth, reliable deployment process is crucial for aligning development efforts with user expectations, maintaining operational continuity, and supporting the continuous evolution of the software product.
Example Deployment Workflow Using Docker
Set Up the Project
Define Dockerfiles for each service in your application (e.g., web app, database).
Write Docker Compose files (e.g., 'docker-compose.yml') if you’re working with multiple services that need to be managed together.
Example Dockerfile for a Spring Boot application
# Start with an official Java runtime as the base image FROM openjdk:17-jdk-alpine # Set the working directory WORKDIR /app # Copy the application jar file into the image COPY target/myapp.jar myapp.jar # Expose the port the app will run on EXPOSE 8080 # Run the application ENTRYPOINT ["java", "-jar", "myapp.jar"]
Build Docker Images
docker build -t myapp:latest .
Tag images properly to manage different versions in registries (e.g., 'myapp:v1.0').
Run Local Tests in Containers
Use Docker Compose or individual Docker containers to run tests in an isolated environment.
docker-compose up -d docker-compose exec webapp ./run-tests.sh
Ensure all services are running and passing their tests.
Push Images to a Docker Registry
Push your Docker images to a container registry (e.g., Docker Hub, Amazon ECR, or a private registry) to make them accessible to the deployment environment.
Log in and push images−
docker login -u username -p password docker tag myapp:latest username/myapp:v1.0 docker push username/myapp:v1.0
Deploy to a Staging Environment
Pull images from the registry onto the staging server−
docker pull username/myapp:v1.0
Deploy using Docker Compose or Kubernetes, depending on the staging environment setup.
Run any additional integration or acceptance tests in staging.
Monitor Logs and Metrics
Use Docker commands to check logs and application health.
docker logs -f container_name
If using monitoring tools (e.g., Grafana, Prometheus), confirm that the application metrics are within acceptable thresholds.
Approve and Deploy to Production
Once tests pass in staging, deploy the images to the production environment by pulling them from the registry.
Run Docker Compose or Kubernetes commands to start services in production−
docker pull username/myapp:v1.0 docker run -d -p 8080:8080 username/myapp:v1.0
Implement Rollback Mechanism
Ensure that you have the previous version's image stored. If issues arise, re-deploy the last stable version−
docker pull username/myapp:v0.9 docker run -d -p 8080:8080 username/myapp:v0.9
Automate Workflow with CI/CD Pipeline
Set up a CI/CD pipeline (e.g., GitHub Actions, GitLab CI, Jenkins) that automates this workflow, including build, test, push, and deployment stages.
Example of a CI/CD pipeline script (GitHub Actions)−
name: Docker CI/CD
on:
push:
branches:
- main
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Build Docker image
run: docker build -t username/myapp:${{ github.sha }} .
- name: Log in to Docker Hub
run: echo "${{ secrets.DOCKER_PASSWORD }}" | docker login -u ${{ secrets.DOCKER_USERNAME }} --password-stdin
Summary
This workflow automates the build, test, and deployment stages for a Dockerized application, providing both local and remote testing, a rollback strategy, and an automated CI/CD pipeline to streamline the process.
Functional Vs. Non-functional Requirements
Introduction to Requirements in Software Development
Functional Requirements
Define what the system should do. They define specific behaviours, features, and functionalities that the system must have to meet user needs. These requirements are usually expressed as actions or tasks the system should perform.
Examples
User Authentication− The system must allow users to log in with a username and password.
Data Processing− The system must process and validate user inputs in real-time.
Reporting− The system must generate sales reports on a monthly basis.
Non-Functional Requirements
Define how the system should perform. They define the quality attributes, performance standards, and constraints that the system must adhere to. These requirements focus on aspects such as usability, reliability, security, and scalability.
Examples
Performance− The system must handle up to 1000 concurrent users with response times of less than 2 seconds.
Security− The system must ensure data encryption for all sensitive information.
Usability− The system must be user-friendly and accessible to users with disabilities.
Types of Functional Requirements
User Interface Requirements− Requirements related to UI components, layout, and design (e.g., a search bar).
Business Requirements− Describe business rules and policies (e.g., the system should apply a tax rate based on location).
Data Management Requirements− Define how the system should handle data input, storage, and processing.
Administrative Requirements− Features for system administration, like user role management or access control.
Example Use Case
Describe a sample functional requirement and how it helps meet business objectives.
Types of Non-Functional Requirements
Performance Requirements
Response times− the amount of time it takes for a system to react to a given input or request.
Throughput− refers to the rate at which a system can process data or complete tasks within a given period of time.
Latency− refers to the time delay between a user's action and the corresponding response from the system.
Examples
Response Time− The page should load in under 2 seconds for 93% of users.
Scalability Requirements
The system’s ability to handle growth in data volume, users, or transactions.
Example− The system should support up to 10,000 concurrent users.
Security Requirements
Requirements for data protection, encryption, and access control.
Example− Passwords must be hashed and salted before storage.
Usability Requirements
Requirements related to the ease of use and learnability of the system.
Example− All core functions should be accessible with no more than three clicks.
Reliability and Availability Requirements
Defines the system’s expected uptime and error tolerance.
Example− The system should have 99.9% uptime.
Maintainability and Portability
Requirements for the ease of maintenance, debugging, and migration.
Example− Code should follow documented standards to ensure maintainability.
Legal and Compliance Requirements
Regulations and standards the system must adhere to (e.g., GDPR – General Data Protection Regulation)
Example− Users must consent to data usage in compliance with GDPR.
Techniques for Gathering Requirements
Interviews with stakeholders and users to capture expectations.
Surveys and Questionnaires for collecting feedback from a large audience.
Workshops and Brainstorming Sessions for collaborative requirement gathering.
Observation and Job Shadowing to understand real-world user interactions.
Document Analysis of existing systems and policies.
Prototyping and Mock-ups to visualize requirements and gather feedback.
Documenting Functional and Non-Functional Requirements
Requirements Documentation
Software Requirements Specification (SRS) Documents− Used to capture both functional and non-functional requirements in detail.
Agile User Stories and Acceptance Criteria− Defining "done" for each requirement.
Using Diagrams
Use Case Diagrams− Visualizing functional requirements.
Flowcharts and Sequence Diagrams− For process flows and system interactions.
Non-Functional Documentation
Quality Attribute Scenarios− Describing non-functional requirements in scenarios (e.g., "In case of a server failure, the system should recover within 3 minutes").
Best Practices− Ensuring requirements are clear, testable, and prioritized.
Challenges in Managing Functional and Non-Functional Requirements
Ambiguity and Misinterpretation− Vague requirements lead to misunderstandings. Use clear, specific language. Changing Requirements: Requirements may change frequently; use Agile methodologies for flexibility.
Conflict between Functional and Non-Functional Goals− Trade-offs may be required (e.g., security vs. usability).
Prioritization Issues− High-priority non-functional requirements (like security) may be overlooked.
Stakeholder Alignment− Ensuring all stakeholders agree on priorities and definitions.
Best Practices for Managing and Validating Requirements
Involve Stakeholders− Regular stakeholder feedback ensures requirements align with expectations.
Prioritize Requirements− Rank functional and non-functional requirements based on importance to the business.
Tests for Non-Functional Requirements
Load Testing for performance requirements.
Usability Testing for user experience.
Security Audits for security and compliance requirements.
Iterative Review and Refinement, Regularly revisit requirements for completeness and relevancy.
Use Automation, Track requirements in real-time, using tools like JIRA, Confluence, and Trello for traceability.
Summary
A balanced approach to functional and non-functional requirements is essential for building robust, user-centred software systems. This article highlights the definitions, types, and methods for gathering, documenting, and validating these requirements, ensuring software projects align with both user expectations and technical standards.
What is a Data Flow Diagram?
Introduction to Data Flow Diagrams
Definition of DFD
DFD can be explained as a graphical representation of the flow of data through a system.
Purpose and Importance
Used to visualize the movement of data and interactions within a system.
Helps developers, business analysts, and stakeholders understand the process without technical complexities.
Key Benefits
Simplifies complex processes.
Provides clarity in communication between technical and non-technical stakeholders.
DFD Components and Symbols
Processes− Represented by circles or rounded rectangles. Describe how each process transforms inputs into outputs.
Data Stores− Represented by open-ended rectangles, symbolizing where data is stored within the system.
Data Flows− Arrows indicate data movement between components, labelled with the type of data being transferred.
External Entities (Sources/Sinks)− Represented by squares, indicating external systems or users interacting with the system.
Example DFD with simple use case

Types and Levels of Data Flow Diagrams
Context Diagram (Level 0)− High-level DFD showing the entire system as a single process with external entities.
Level 1 DFD− Breaks down the main process into sub-processes with data flows and stores.
Level 2 and Beyond− Further decomposition for more detailed views, typically for large or complex systems.
Creating a Data Flow Diagram - Step-by-Step Guide
Step 1− Identify external entities (who/what interacts with the system).
Step 2− Define main processes (primary system functions).
Step 3− Map data flows between entities and processes.
Step 4− Identify data stores where information is stored for processing.
Step 5− Refine and add details by decomposing higher-level diagrams into lower levels if needed.
Tips− Use consistent labelling, avoid crossing lines where possible, and ensure all components have clear labels.
Examples of DFDs for Different Systems
Example 1− Online Retail System: Context diagram illustrating basic data flows (user, payment gateway, inventory). Level 1 DFD with processes like "Place Order," "Process Payment," "Manage Inventory.".
Example 2− Library Management System: Context diagram showing library staff, member, and database as entities. Level 1 DFD with processes like "Issue Book," "Return Book,", "Update Member Info.".
Example 3− Banking System: Context diagram illustrating customer, bank, and ATM as Level 1 DFD with processes such as "Deposit Funds", "Withdraw Funds", "Check Balance".
Use Cases of Data Flow Diagrams in Different Industries
Healthcare− Visualize patient data flow through different departments (e.g., admission, diagnostics, billing).
E-commerce− Illustrate customer journey from browsing to checkout and fulfilment.
Banking and Finance− Show data flow across ATMs, branches, and online platforms for transactions and account management.
Education− Depict the student lifecycle from registration to graduation, including course management and record keeping.
Case Study Example− Sample use case diagram for patient data management in a hospital.
Best Practices for Creating and Using Data Flow Diagrams
Keep it Simple− Avoid over-complicating; use hierarchical DFD levels for clarity.
Use Consistent Symbols and Labels− Standardize symbols for readability and clarity.
Avoid Overlapping Lines− Minimize visual clutter by arranging components clearly.
Validate with Stakeholders− Confirm with users and stakeholders to ensure accuracy.
Iterate and Refine− Revise as the system evolves, especially with complex projects.
Example Tips− Show a cluttered DFD vs. a well-organized DFD to highlight best practices.
Common Mistakes and How to Avoid Them
Undefined or Ambiguous Labels− Using clear, descriptive labels for all data flows and processes.
Too Much Detail in High-Level DFDs− Reserve finer details for lower levels to avoid clutter.
Missing Data Stores or Data Flows− Ensure all required data storage and movement are included.
Incorrect Placement of External Entities− Keep external entities at the periphery of the system.
Unconnected Processes− Ensure that each process has incoming and outgoing data flows.
Advanced Concepts and Future of Data Flow Diagrams
Extended DFDs
Using DFDs to illustrate event-based or real-time data flows.
Automated Tools for DFD Creation
Microsoft Visio, Lucidchart, and online DFD generators.
Benefits of automated tools
Quicker updates, easy sharing, and standardization.
Integrating DFDs with Other Diagrams
Combining DFDs with entity-relationship diagrams (ERDs) or use case diagrams for a holistic view.
Future of DFDs in Agile Environments
Potential for quick iterations, integration with user stories, and continued relevance in complex system designs.
Summary
This guide provides an in-depth understanding of DFDs, their purpose, structure, and best practices for creation and usage. DFDs remain valuable for system analysis and design, offering a straightforward way to understand data flows and system architecture.
Data Flow Diagram - Types and Components
Purpose of Data Flow Diagrams (DFDs)
A Data Flow Diagram (DFD) is a graphical representation that illustrates how data flows within a system, highlighting the processes, data stores, and external entities that interact with one another. DFDs are instrumental in understanding, designing, and documenting the way data moves through systems. By showing where information comes from, where it goes, and how it’s transformed along the way, DFDs help analysts, designers, and stakeholders clearly see the system’s functionality and structure without needing to dive into complex technical details.
Key Concepts and Benefits
Key Concepts
Key elements− data flows, processes, data stores, and external entities.
Benefits of Using DFDs
Clarity and simplicity in visualization.
Helps in requirement analysis, design phase, and troubleshooting.
Types of Data Flow Diagrams
Data Flow Diagrams (DFDs) are hierarchical diagrams used to visualize the flow of information within a system. They are divided into different levels, where each level provides an increasing amount of detail.
Level 0 DFD− Context Diagram
The Level 0 DFD is also known as a context diagram and represents the system's highest-level view.
Purpose− It provides a broad overview of the system, showing the major entities (or external systems) that interact with it and the primary flow of information.
Components
Single Process− Usually represented as a single circle or rectangle with a label indicating the system's overall purpose (e.g., "Order Processing System").
External Entities− Squares representing entities that interact with the system, such as "Customer" and "Warehouse."
Data Flows− Arrows showing the main flow of data between external entities and the system.
Level 1 DFD− Decomposition of the Main System
The Level 1 DFD expands the Level 0 DFD, breaking down the main system process into sub-processes. It shows a bit more detail on how the system handles data.
Purpose− To break down the main process into smaller sub-processes, showing how the system functions internally.
Components
Multiple Processes− Each main activity in the system, such as "Process Order," "Manage Inventory," "Process Payment," and "Fulfil Order," is shown as a separate process.
Data Stores− Represented by open-ended rectangles, data stores like "Order Data Store" or "Inventory Data Store" show where data is stored within the system.
Data Flows− More specific data flows indicate what data is passed between processes and to/from data stores and entities.
Example− In an order processing system, Level 1 DFD would show processes like "Process Order," "Check Inventory," "Process Payment," and "Ship Order" connected by data flows. Each process would interact with data stores and external entities, showing more specific interactions than the Level 0 diagram.
Level 2 DFD− Detailed Process Breakdown
The Level 2 DFD provides a deeper dive into one of the processes in the Level 1 DFD. It represents an even finer level of detail.
Purpose− To show detailed steps within a single process, indicating precise actions taken to complete a part of the system's functionality.
Components
Sub-Processes− Each sub-process is a more granular step within one of the processes from Level 1. For example, "Check Inventory" might include steps like "Update Inventory" and "Check Stock Availability."
Additional Data Stores− If necessary, additional data stores specific to these finer steps may be included.
Data Flows− Detailed data flows show the exact movement of information within the chosen Level 1 process.
Example− For the "Process Order" process in an order processing system, the Level 2 DFD might break it down into steps like "Validate Order," "Check Inventory," "Authorize Payment," and "Confirm Order." Data flows would specify the data being checked, stored, or modified in each step, providing a clear picture of the workflow.
| Sr.No. | DFD Level | Purpose Detail | Level | Typical Components |
|---|---|---|---|---|
| 1 | Level 0 | Broad overview (context) | High-level | Single process, external entities, data flows |
| 2 | Level 1 | Main system decomposition | Medium | Multiple processes, data stores, specific data flows |
| 3 | Level 2 | Detailed process breakdown | Low-level (granular) | Sub-processes, additional data stores, detailed data flows |
Each DFD level provides a progressively more detailed view of the system, making it easier to understand and analyze complex workflows systematically.
Components of Data Flow Diagrams
Processes
Define processes as transformations of data within the system.
Illustrate with symbols and examples, e.g., "Order Processing" in an e-commerce DFD.
Data Stores
Define data stores as repositories where data is held within the system.
Discuss naming conventions and examples like "Customer Data" or "Inventory". Make the names easy to understand.
Data Flows
Define data flows as routes data takes between processes, data stores, and external entities.
Illustrate with labelled arrows and emphasize clarity in naming data flows.
External Entities
Define external entities as sources or destinations of data outside the system’s control.
Numbering process of DFD’s
In Data Flow Diagrams (DFDs), numbering processes is a structured way to show the hierarchical relationships between different levels of processes. This numbering method helps make DFDs more readable and organized, allowing viewers to trace a process’s origins and connections within the system. Here’s an explanation of numbering processes across the DFD levels−
Level 0 DFD (Context Diagram)
Single Process Numbering− Since Level 0 provides a high-level overview of the system, it is represented as a single process without any sub-processes. This process is often numbered as "0" (e.g., "Order Processing System (0)").
Purpose− The "0" label denotes that this is the main system, containing all further processes.
Level 1 DFD
Breaking Down the Main Process− In Level 1, the main process (Process 0) is decomposed into sub-processes that represent core functions of the system.
Numbering Convention− Each sub-process within Level 1 is numbered as 1, 2, 3, etc., based on its position in the process flow.
For example, in an Order Processing System−
Process 1− "Process Order"
Process 2− "Manage Inventory"
Process 3− "Process Payment"
Process 4− "Fulfill Order"
Purpose− This numbering indicates that each process is a primary function within the main system.
Level 2 DFD (and further levels)
Breaking Down Each Level 1 Process− In Level 2, each Level 1 process is broken down further into smaller steps or sub-processes.
Numbering Convention− The Level 2 sub-processes use decimal notation to indicate they are part of a Level 1 process.
For example, breaking down "Process Order (Process 1)"−
Process 1.1− "Validate Order"
Process 1.2− "Check Inventory"
Process 1.3− "Authorize Payment"
Process 1.4− "Confirm Order"
If another Level 1 process like "Manage Inventory (Process 2)" is broken down−
Process 2.1− "Check Stock Availability"
Process 2.2− "Update Inventory"
Further Levels− If required, Level 2 sub-processes can be broken down further in a Level 3 DFD, which would use numbering like 1.1.1, 1.1.2, and so on.
Benefits of DFD Process Numbering
Clarity− Numbering helps users quickly identify and trace processes and sub-processes across different levels.
Organization− It shows the hierarchical structure of processes, indicating how high-level processes break down into finer tasks.
Easy Reference− Each process has a unique identifier, making it easy to discuss and analyze specific steps within the system.
Developing Data Flow Diagram (DFD) Model of System
Introduction
This article provides a comprehensive guide to Data Flow Diagrams (DFDs), focusing on the development process, types, benefits, and challenges involved. It covers practical techniques, tools, and best practices that aid in creating efficient DFDs. This guide is designed for system analysts, project managers, and students.
Data Flow Diagrams (DFDs) are a popular method in system analysis and design, helping visualize how data flows within a system, its processing points, and storage locations. By defining and representing the data flow from sources to destinations, DFDs help in understanding the functionality of complex systems.
Importance of DFD’s
Simplifies complex systems into manageable parts.
Improves system requirements understanding.
Helps identify potential system inefficiencies or bottlenecks.
Benefits of Using Data Flow Diagrams
DFDs offer several benefits for both technical and non-technical stakeholders−
Enhanced Communication− Provides a common visual language across teams.
Clarity on System Requirements− Identifies inputs, processes, and outputs.
Efficient System Analysis− Facilitates the identification of redundancies or bottlenecks.
Improved Design Quality− Lays the foundation for optimized database and system design.
The Development Process of Data Flow Diagrams
Step 1: Define System Boundaries and Scope
Identify all external entities interacting with the system.
Define what lies within and outside the scope of the DFD.
Step 2: Identify Core Processes
Pinpoint the main processes that handle data.
Consider breaking down complex processes to increase clarity.
Step 3: Identify Data Stores
Determine where the data will be stored within the system.
Classify these stores based on how data is managed.
Step 4: Identify Data Flows
Establish the data flows between entities, processes, and stores.
Verify that all necessary inputs and outputs are represented.
Step 5: Construct Context Diagram (Level 0 DFD)
Create the highest-level DFD showing a single process and external entities.
Connect entities with the main process through data flows.
Step 6: Develop Detailed Levels (Level 1, Level 2)
Break down the main process in the context diagram into sub-processes.
Add detail with each level, ensuring accuracy in data flows and connections.
Step 7: Validation and Review
Validate the DFD with stakeholders to ensure completeness.
Adjust the diagram based on feedback to address any gaps.
Tools for Creating Data Flow Diagrams
Lucidchart− Offers a range of DFD symbols and collaboration features.
Microsoft Visio− Commonly used for DFD creation in organizations.
Draw.io− Free tool for creating DFDs and other types of diagrams.
SmartDraw− Provides templates and easy-to-use DFD tools.
Visual Paradigm− Supports all levels of DFDs and advanced features.
Each tool provides unique features that support specific needs, such as collaboration, template availability, and export options.
Example: E-commerce Order Processing System DFD
Context Diagram
The E-commerce system includes external entities like Customers and Payment Gateway, represented in a single high-level process labeled “Order Processing.”
Level 0 DFD
Order Management− Receives and processes orders.
Inventory System− Manages product availability.
Payment Processing− Processes payments from the payment gateway.
Customer Database− Stores customer information and order history.
Challenges in Developing DFDs
Ambiguous Requirements− Incomplete or unclear requirements can result in an inaccurate DFD.
Complex Systems− Large systems can become overly complex, leading to difficult-to-interpret DFDs.
Changing Requirements− DFDs require updates with evolving requirements.
Stakeholder Misalignment− Lack of consensus on DFD accuracy or level of detail can delay approval.
Best Practices for DFD Development
Keep It Simple− Avoid unnecessary complexity at higher DFD levels.
Involve Stakeholders− Collaborate with all relevant parties early on.
Use Consistent Naming− Clearly label entities, processes, and data stores.
Regularly Review and Refine− Ensure DFD accuracy through iterative reviews.
Limit Diagram Levels− Restrict the depth of detail to avoid excessive complexity.
Conclusion
Data Flow Diagrams are invaluable tools for system analysis, design, and communication. They enable a better understanding of system functions and data movement, providing clarity to both technical and non-technical stakeholders. With proper development and best practices, DFDs facilitate effective design, analysis, and ongoing system improvement.
Data Flow Diagram - Balancing
Introduction to Data Flow Diagrams and Balancing
What Are Data Flow Diagrams (DFDs)?
Data Flow Diagrams (DFDs) visually represent the flow of data within a system, showing processes, data stores, external entities, and data flows. DFDs are structured hierarchically−
Context Diagram− High-level overview of the system as a single process.
Level 0 DFD− Breaks down the single process into major functions.
Level 1 and Beyond− Further decomposes processes into sub-processes.
What Is Balancing in DFDs?
Balancing refers to maintaining consistency in data flow between various levels of a DFD. When decomposing processes into lower levels, all data flows entering or exiting a higher-level process should match the data flows in the lower-level DFD for that process.
Balancing is an essential concept in DFDs, ensuring that data at different levels of the diagram maintains consistency and clarity.
Importance of Balancing in Data Flow Diagrams
Balancing plays a crucial role in DFDs by−
Ensuring Data Consistency− Prevents data mismatches between levels.
Improving Accuracy− Maintains the integrity of information in system analysis.
Enhancing Clarity− Helps stakeholders understand system functionality without confusion.
Supporting Effective System Design− Assists developers and analysts in keeping designs reliable and easy to interpret.
Consequences of Poor Balancing
Data inconsistencies
Misinterpretation of system requirements
Increased errors in system design and implementation
Principles of DFD Balancing
Balancing requires following these principles when moving from one DFD level to another−
Consistency in Data Flow− Each input or output at a higher level must be reflected at lower levels.
Data Flow Alignment− The names and purposes of data flows should match across levels.
Process Correlation− Ensure that processes in a decomposed DFD align logically with the parent process.
Techniques for Balancing Data Flow Diagrams
Technique 1: Using Level Balancing
When decomposing a process−
Maintain the same external data flows between parent and child DFDs.
For example, if a "Sales Processing" process at Level 0 has data flows for "Customer Order" and "Order Confirmation," Level 1 must reflect these flows either directly or through sub-processes.
Technique 2: Matching Data Stores
Data stores must be consistent across levels. If a data store appears in a higher level DFD, it should appear in the corresponding lower levels when relevant to the decomposed processes.
Technique 3: Consistent Data Flow Naming
Use consistent naming conventions for data flows across all levels of the DFD to reduce ambiguity and improve clarity.
Example: Balancing in DFDs
Consider an online library management system.
Level 0 DFD
The library system includes−
Processes− Borrow Book, Return Book, Update Catalog.
Data Flows− Book Request, Book Return Confirmation, Catalog Update
Level 1 DFD (Decomposing "Borrow Book")
Sub-processes− Verify Membership, Check Book Availability, Issue Book.
Data Flows− Book Request, Member Validation, Book Issuance Confirmation.
For balance, all data flows related to "Borrow Book" in Level 0 must appear in the Level 1 diagram. This includes−
Book Request (from the user to the system)
Book Issuance Confirmation (from the system to the user)
Explanation
Balancing here ensures that any data flow into or out of "Borrow Book" at Level 0 is preserved at Level 1. This consistency avoids data being "lost" in the decomposition.
Tools for DFD Balancing
Lucidchart− Offers templates and tools to visualize hierarchical DFDs, with features that support multi-level balancing.
Microsoft Visio− A powerful tool for creating structured DFDs, with built-in support for aligning and balancing flows.
SmartDraw− Provides easy-to-use DFD templates that aid in the creation of balanced diagrams.
Visual Paradigm− Offers automated checking for balanced DFDs, helping analysts avoid inconsistencies.
Draw.io− A free tool that supports multiple DFD levels, making balancing easier for beginners.
Challenges in Balancing Data Flow Diagrams
Inconsistent Data Flows− A common issue arises when data flows are inconsistently named or described across DFD levels, leading to misalignment.
Complex Processes− For complex systems, breaking down processes while keeping data flows consistent can be difficult and time-consuming.
Scope Creep− As systems evolve, new requirements may change data flows, leading to unbalanced diagrams that require re-evaluation.
Stakeholder Misunderstandings− Balancing can be difficult to explain to stakeholders unfamiliar with technical diagramming, causing confusion over data flow consistency requirements.
Best Practices for Effective DFD Balancing
Maintain a Single Source of Truth− Use a master list for data flows and update it as the DFD evolves.
Iterative Verification− Frequently review each level to ensure consistent flows.
Standardize Naming Conventions− Clear, descriptive names for each data flow make balancing simpler.
Limit Levels− Avoid over-decomposition to prevent unmanageable DFD complexity.
Stakeholder Engagement− Involve stakeholders early to align expectations and ensure accurate representation of system flows.
Conclusion
Balancing is a critical component of Data Flow Diagramming, ensuring data flow integrity and consistency across various levels. Mastery of balancing techniques allows system analysts and developers to produce reliable and comprehensible DFDs that accurately reflect system functionality. Adhering to best practices and leveraging suitable tools can simplify the balancing process, helping maintain the clarity and reliability of system models.
Data Flow Diagram - Decomposition
Introduction
Data Flow Diagrams (DFDs) are an essential tool in systems analysis and design, enabling stakeholders to visualize the flow of information within a system. Among the many principles of DFDs, decomposition stands out as a critical concept for breaking down complex systems into manageable components. This article explores decomposition in the context of DFDs, its importance, techniques, and real-world applications.
Understanding Decomposition in DFDs
Decomposition is the process of breaking down a large, complex system into smaller, more manageable components. In DFDs, this involves progressively detailing high-level processes into sub-processes, each with its data flows and interactions.
Why Decompose?
Simplifies complex systems for analysis.
Enhances clarity for stakeholders.
Allows detailed documentation for specific parts of a system.
Identifies inefficiencies, redundancies, or bottlenecks in processes.
Levels of DFD Decomposition
Decomposition in DFDs follows a hierarchical approach, starting from the most abstract representation of a system and progressively delving into finer details.
Context Diagram
The Context Diagram represents the highest abstraction level. It portrays the entire system as a single process and focuses on−
External entities
Major data flows between the system and its environment
Example− A library management system's context diagram may show processes like borrowing books and returning books without detailing how these tasks are managed internally.
Level-1 DFD
The Level-1 DFD breaks the single process in the context diagram into major sub-processes. It shows−
Internal data flows between processes
Data stores interacting with these processes
Example− Borrowing books might be decomposed into−
Checking user credentials
Retrieving book details
Updating the database
Level-n DFDs
Higher-level DFDs (Level-2, Level-3, etc.) provide further decomposition of processes into more granular tasks. This iterative detailing continues until each process is simple enough for direct implementation.
Steps to Decompose a DFD
Decomposition requires systematic steps to ensure accuracy and coherence−
Step 1− Identify Key Processes
Start with high-level processes (from the context diagram) that need detailing. Choose processes that involve multiple tasks or significant interactions.
Step 2− Define Sub-processes
For each high-level process, identify sub-processes that perform specific tasks. Ensure sub-processes align with system objectives.
Step 3− Map Data Flows
Detail how data moves between sub-processes, data stores, and external entities. Use clear and consistent labelling.
Step 4− Validate with Stakeholders
Review the decomposed diagrams with stakeholders to ensure completeness and accuracy. This prevents misinterpretations and captures feedback.
Step 5− Iterate as Needed
Further refine sub-processes based on complexity or stakeholder requirements.
Best Practices in DFD Decomposition
To achieve effective decomposition, consider these best practices−
Adhere to Consistency
Maintain consistent notations, labels, and naming conventions across levels.
Avoid Over-decomposition
Too many levels can complicate understanding. Stop when processes are simple enough for implementation.
Focus on Functionality
Break down processes based on functionality, not arbitrary divisions.
Use Modular Design
Ensure sub-processes can function independently wherever possible.
Document Every Level
Accompany each DFD level with documentation explaining its elements and relationships.
Common Challenges and Solutions
Challenge 1− Overlapping Data Flows
Solution− Clearly define boundaries between processes and ensure proper labelling.
Challenge 2− Lack of Stakeholder Input
Solution− Involve stakeholders in the review and validation phases.
Challenge 3− Scope Creep
Solution− Limit decomposition to the project scope. Define clear boundaries at the outset.
Challenge 4− Misrepresentation of Processes
Solution− Collaborate with domain experts to accurately depict processes.
Applications of Decomposition in Real-world Scenarios
Decomposition is widely used in various fields to design and optimize systems. Some examples include−
Software Development
Decomposition helps break down system functionalities into modules, guiding developers in building scalable and maintainable software.
Business Process Reengineering
By visualizing workflows, organizations can identify bottlenecks, redundancies, or inefficiencies in their processes.
Healthcare Systems
Decomposed DFDs help map patient data flows, ensuring secure and efficient management of medical records.
E-commerce Platforms
E-commerce systems use decomposition to define key processes like order management, inventory tracking, and payment processing.
Conclusion
Decomposition is an indispensable aspect of Data Flow Diagrams, enabling system analysts and designers to unravel complexities and create efficient systems. By systematically breaking down high-level processes, decomposition fosters clarity, enhances collaboration, and ensures better system design. As organizations increasingly rely on structured methodologies for system development, mastering DFD decomposition remains a vital skill for analysts and stakeholders alike.
System Design - Databases
Introduction to System Design and Databases
System design is a critical aspect of building scalable, efficient, and robust software solutions. At the core of system design lies the database, a structured repository that stores, organizes, and retrieves data essential for system operations.
The role of databases in system design cannot be overstated. They ensure data consistency, support concurrent operations, and underpin business logic. This section will explore foundational concepts, including the importance of databases in system design and an overview of their purpose.
Types of Databases
Databases come in various forms, each suited for specific use cases. Understanding their types is essential for selecting the right database for a given system.
Relational Databases (RDBMS)− Stores data in relational format through the use of foreign key. Examples include MySQL, PostgreSQL, and Oracle. These databases use structured query language (SQL) to manage data in predefined schemas.
NoSQL Databases− Non-relational database. Including document stores like MongoDB, key-value stores like Redis, and columnar databases like Cassandra. These are optimized for flexibility and horizontal scaling.
NewSQL Databases− A hybrid of RDBMS and NoSQL databases, offering scalability while maintaining ACID (Atomicity, Consistency, Isolation, Durability) compliance. Examples: CockroachDB, VoltDB, Google Spanner.
In-Memory Databases− Stores data in RAM or disk, such as H2, Redis and Memcached, which prioritize speed by storing data in RAM.
Graph Databases− They use graph structures with nodes, edges, and properties to represent and store data. Examples include Neo4j and ArangoDB, suitable for relationship-heavy data like social networks.
Key Components of Database System Design
Database system design is not just about selecting a type of database. It encompasses several components−
Schema Design− Blueprint of the data structure.
Indexing− To enhance query performance.
Sharding− Partitioning databases for scalability.
Replication− Ensuring high availability and fault tolerance.
Consistency Models−
Strong Consistency− Immediate data consistency across nodes.
Eventual Consistency− Favoured in distributed systems for performance.
Database Normalization and Schema Design
Schema design is at the heart of system efficiency and involves organizing data into tables and defining relationships. This section will explore−
Normalization− A process to eliminate data redundancy and improve consistency by dividing tables into smaller units.
Denormalization− Opposite of normalization, used in systems requiring faster read operations.
Best Practices−
Understand data access patterns.
Choose the right balance between normalization and denormalization.
Use tools like ER diagrams to design schemas.
Real-world scenarios and step-by-step schema examples will illustrate these concepts.
Database Scalability and Performance Optimization
Modern systems demand highly scalable and performant databases. Key strategies include−
Vertical Scaling− Adding more resources to a single server.
Horizontal Scaling− Distributing the load across multiple servers.
Caching− Using tools like Redis or Memcached to store frequently accessed data.
Query Optimization− Writing efficient queries and using indexing.
Load Balancing− Distributing database queries evenly.
NoSQL vs. SQL in System Design
The choice between NoSQL and SQL is pivotal in system design. This section compares the two paradigms−
SQL Databases
Pros− Data integrity, ACID compliance, robust querying capabilities.
Cons− Limited flexibility for unstructured data.
NoSQL Databases
Pros− Scalability, schema-less design, optimized for big data.
Cons− Weaker consistency guarantees (e.g., eventual consistency).
Challenges in Database System Design
Designing a database system is fraught with challenges−
Handling High Concurrent Traffic− Managing millions of queries per second.
Consistency vs. Availability− High availability refers to systems that are designed to operate continuously without failure for a long period. Trade-offs highlighted by the CAP theorem. The theorem states that it is impossible for a distributed data store to simultaneously provide all three of the following guarantees: consistency, availability and partition tolerance.
Data Security− Ensuring compliance with standards like GDPR (General Data Protection Regulation).
Backup and Recovery− Implementing failover strategies.
Future Trends in Database System Design
The future of databases is being shaped by technological advancements such as−
AI-Driven Databases− Leveraging machine learning for query optimization.
Blockchain Databases− Decentralized systems for data integrity.
Edge Databases− Optimized for IoT and edge computing.
Conclusion
Databases are fundamental to system design. From schema planning to scalability, a well-designed database ensures that a system can grow and adapt to changing requirements. By understanding the principles discussed in this article, developers and architects can build systems that are both robust and scalable.
System Design - Database Sharding
Introduction to Database Sharding
In modern application development, databases play a crucial role in managing and processing large volumes of data. As businesses scale, their databases often encounter performance bottlenecks, leading to slow response times and reduced user satisfaction. Database sharding is a powerful architectural solution that addresses this challenge by distributing data across multiple servers.
What is Database Sharding?
Database sharding is a type of horizontal partitioning that splits a large database into smaller, more manageable pieces called shards. Each shard operates as an independent database containing a subset of the overall data. The distribution of data ensures that no single server becomes a bottleneck, enabling applications to handle higher traffic and larger datasets efficiently.
Why is Sharding Important?
As businesses grow, data volumes increase exponentially. A single database server may struggle to meet the demands of millions of users simultaneously querying data. Sharding helps by distributing the load across multiple servers, improving system performance, and ensuring high availability. For example, social media platforms like Instagram and e-commerce platforms like Amazon rely on sharding to maintain seamless user experiences.
Challenges in Scaling Databases
As applications scale, database systems face challenges in managing increasing traffic and data volumes. Understanding these challenges highlights the need for database sharding as an effective solution.
Vertical Scaling vs. Horizontal Scaling
Scaling a database can be approached in two ways−
Vertical Scaling− Involves upgrading the existing server with more CPU, memory, and storage. While this method is straightforward, it has physical and cost limitations. A single server can only be enhanced to a certain extent before reaching its maximum capacity.
Horizontal Scaling− Adds more servers to the system, distributing data and workloads among them. This approach offers virtually unlimited scalability but comes with complexity in terms of data management.
The Necessity of Sharding
Horizontal scaling often necessitates database sharding to efficiently manage distributed data. For example: In an online gaming platform, millions of users’ data need to be processed simultaneously. Without sharding, the system might collapse under the load.
E-commerce websites must manage product catalogues, user accounts, and order histories in real-time across multiple geographies.
Without effective sharding, scaling horizontally can still lead to inefficiencies due to uneven data distribution and bottlenecks.
How Database Sharding Works
Database sharding involves splitting a large dataset into smaller parts and distributing them across multiple servers. This process involves several key components and considerations.
Key Concepts
Partitioning Data− The first step in sharding is dividing the database into smaller chunks, each representing a subset of the overall data.
Data Distribution− Shards are stored on different servers, allowing the system to process queries in parallel. This reduces the load on any single server and improves overall performance.
The Role of Shard Key
A shard key is a field within the database that determines how data is distributed across shards.
Choosing the Right Shard Key
A well-chosen shard key ensures even data distribution, reducing the risk of hot spots where one shard handles disproportionately high traffic.
Impact of a Poor Shard Key
An inefficient shard key can lead to uneven distribution and degraded system performance, negating the benefits of sharding.
For example, in a user database, choosing "user ID" as the shard key ensures that data related to each user is stored in the same shard, simplifying query handling.
Sharding Architectures
Database sharding can be implemented using various architectures, each with its strengths and weaknesses.
Types of Sharding
Range-Based Sharding
Divides data based on a specific range of values.
Example− User IDs 1-1000 in Shard A, 1001-2000 in Shard B.
Pros− Simple to implement and understand.
Cons− Uneven data distribution if certain ranges have significantly more data.
Hash-Based Sharding
Uses a hash function to assign data to shards.
Example− Hash(User ID) % Number of Shards` determines the shard.
Pros− Ensures even data distribution.
Cons− Rebalancing data when adding or removing shards can be complex.
Directory-Based Sharding
Maintains a lookup table mapping data to its corresponding shard.
Pros− Flexible and supports custom sharding logic.
Cons− Introduces additional management overhead.
Choosing the Right Architecture
The choice depends on the specific requirements of the application, such as data distribution patterns and query types.
Challenges and Trade-offs in Sharding
While sharding offers significant benefits, it also introduces complexities that must be carefully managed.
Complexity in Management
Data Distribution and Rebalancing− As the database grows, shards may become unbalanced, requiring redistribution of data, which is a resource-intensive process.
Operational Overhead− Maintaining multiple shards and ensuring their availability increases the complexity of the system.
Performance Bottlenecks
Query Inefficiencies− Cross-shard queries, where data spans multiple shards, can result in higher latency and increased computation costs.
Data Consistency− Maintaining consistency across shards, especially during updates, poses challenges. This is particularly critical for transactional systems.
Despite these challenges, adopting best practices can help mitigate the trade-offs and maximize the benefits of sharding.
Tools and Technologies for Sharding
Modern database systems and middleware solutions provide robust support for implementing sharding.
Database Management Systems with Sharding Capabilities
MongoDB−
Provides native support for sharding using a configurable shard key.
Widely used for applications with dynamic schemas.
Cassandra−
Implements sharding as part of its distributed architecture.
Ideal for write-heavy workloads.
MySQL−
Relies on manual implementation of sharding or third-party tools like ProxySQL.
Middleware Solutions
Vitess−
Popular for sharding MySQL databases.
ProxySQL−
Helps manage query routing in sharded environments.
These tools simplify the process of implementing sharding, allowing developers to focus on application logic.
Case Studies
Real-world implementations of sharding provide valuable insights into its applications and challenges.
Facebook Messenger
Shards conversations based on user IDs to ensure scalability.
Employs hash-based sharding to achieve even data distribution.
Instagram Post Storage
Uses a combination of range-based and hash-based sharding.
Optimizes read and write performance for user-generated content.
Best Practices in Database Sharding
Selecting the Right Shard Key
Analyze data access patterns to choose a key that ensures even distribution and minimizes cross-shard queries.
Monitoring and Maintenance
Implement monitoring tools to identify and resolve imbalances early.
Planning for Growth
Design the architecture to allow for seamless addition of new shards.
Conclusion
Database sharding is a cornerstone of modern system design, enabling applications to handle massive data volumes and high traffic. While it comes with complexities, adopting the right strategies and leveraging robust tools ensures its success. As distributed database technologies evolve, sharding will continue to play a pivotal role in scaling next-generation systems.
System Design - Database Replication
Introduction to Database Replication
Database replication is a foundational concept in modern system design, playing a pivotal role in enhancing data availability, fault tolerance, and performance in distributed systems. As businesses grow, so do their demands for reliable, high-performing databases. Replication addresses these demands by creating and maintaining multiple copies of the same dataset across different locations.
What is Database Replication?
Replication is the process of copying data from one database (the primary) to one or more other databases (replicas). These replicas can be located on the same server, different servers, or even across geographic locations.
Why is Replication Important?
High Availability− Ensures continuous operation even during hardware failures or maintenance.
Improved Performance− By directing read traffic to replicas, replication reduces load on the primary database.
Data Redundancy− Minimizes risk of data loss in case of unexpected failures.
In this article, we’ll dive deep into the mechanics of database replication, its architectures, benefits, challenges, and use cases.
Types of Database Replication
Database replication can be implemented in various ways, each catering to specific requirements and use cases.
Master-Slave Replication
A single primary database (master) handles all write operations, and replicas (slaves) handle read operations.
Use Case− Applications with a high read-to-write ratio, like news websites or content platforms.
Pros− Simplifies scaling read operations.
Cons− Slaves may lag behind the master, causing stale data.
Master-Master Replication
Allows multiple databases to accept write operations, syncing changes across all nodes.
Use Case− Systems requiring high availability and scalability, like financial applications.
Pros− Ensures no single point of failure for write operations.
Cons− Risk of conflicts during data synchronization.
Peer-to-Peer Replication
All nodes are equal, and each can act as both a master and a replica.
Use Case− Distributed systems like content delivery networks.
Pros− High fault tolerance and redundancy.
Cons− Complexity in conflict resolution.
Log-Based Replication
Uses database logs to replicate changes.
Use Case− Event-driven architectures and real-time analytics.
Pros− Low latency and high efficiency.
Cons− Requires careful management of logs.
Benefits of Database Replication
Replication offers numerous benefits that make it indispensable for large-scale systems.
Enhanced Data Availability
Replication ensures that data is accessible even during planned maintenance or unexpected failures. If one node goes down, others can continue serving requests.
Improved Performance
By offloading read operations to replicas, replication reduces latency and enhances performance. This is especially useful for applications with global user bases, as geographically distributed replicas minimize network latency.
Fault Tolerance and Disaster Recovery
Replication provides a safety net for disaster recovery by maintaining multiple copies of the data. In case of data corruption or server failure, replicas can be used to restore operations quickly.
Scalability
Replication facilitates horizontal scaling by enabling the addition of replicas to accommodate growing read workloads without overloading the primary database.
Load Balancing
By distributing traffic across replicas, replication ensures better utilization of resources and prevents bottlenecks.
Replication Architectures
The choice of replication architecture significantly impacts system performance, consistency, and reliability.
Synchronous vs. Asynchronous Replication
Synchronous Replication−
Changes to the master are instantly propagated to replicas.
Guarantees consistency at the cost of higher latency.
Use Case− Financial systems requiring strong consistency.
Asynchronous Replication−
Changes are propagated with a delay, prioritizing performance over immediate consistency.
Use Case− Social media platforms where eventual consistency is acceptable.
Multi-Region Replication
Replicates data across different geographic regions.
Pros− Improves performance for globally distributed users and provides resilience against regional failures.
Cons− Increases latency for write operations due to network delays.
Cascading Replication
Replicas themselves act as sources for additional replicas.
Pros− Reduces load on the primary database.
Cons− Increases complexity in managing replication chains.
Challenges in Database Replication
While replication is powerful, it introduces several challenges that require careful consideration.
Data Consistency
In asynchronous replication, replicas may lag behind the master, leading to stale data.
Managing conflicts in master-master replication is complex.
Network Latency
Geographically distributed replicas can experience high latency during synchronization.
Storage Overhead
Replicas require additional storage, increasing infrastructure costs.
Write Amplification
Replicating data to multiple nodes can amplify write operations, affecting performance.
Failover Complexity
Switching traffic to a replica during master failure requires careful coordination to prevent data loss or inconsistencies.
Addressing these challenges involves using robust replication tools and designing systems with resilience in mind.
Tools and Technologies for Database Replication
Modern databases and tools provide extensive support for implementing replication effectively.
Relational Databases
MySQL−
Supports master-slave and master-master replication.
Offers tools like Replication Lag Monitor for managing delays.
PostgreSQL−
Provides streaming replication and logical replication for flexibility.
NoSQL Databases
MongoDB−
Built-in support for replica sets with automatic failover.
Cassandra−
Peer-to-peer replication with tuneable consistency levels.
Middleware Solutions
Tools like Debezium and Apache Kafka enable real-time data replication across heterogeneous systems.
These technologies simplify implementation and provide features for monitoring, conflict resolution, and failover management.
Case Studies
Replication’s practical impact can be understood through real-world use cases.
Netflix
Utilizes Cassandra’s peer-to-peer replication to ensure global availability of content.
Employs multi-region replication to serve users worldwide with low latency.
Amazon Aurora
Supports synchronous replication for read replicas, ensuring high availability.
Employs automated failover mechanisms for seamless recovery.
Google Spanner
Implements synchronous replication across multiple regions to maintain strong consistency.
Uses Paxos-based consensus algorithms for conflict resolution.
Lessons Learned
Balancing consistency, availability, and performance is crucial in replication design.
Monitoring tools are essential for identifying and addressing replication lags.
Best Practices in Database Replication
Choose the Right Replication Strategy
Evaluate application needs to decide between synchronous and asynchronous replication.
Monitor and Optimize Replication Lag
Use tools like Prometheus and Grafana to track replication metrics.
Implement Failover Mechanisms
Automate failover processes to minimize downtime.
Plan for Growth
Design systems to accommodate future scalability needs.
Conclusion
Database replication is indispensable for building scalable, resilient, and high-performing systems. By distributing data across multiple locations, replication not only enhances availability but also improves performance for global applications. However, the challenges of consistency, latency, and failover must be carefully managed. As businesses continue to scale, replication will remain a critical component of system design, empowering applications to meet the demands of an increasingly data-driven world.
System Design - Database Federation
Introduction to Database Federation
In an era of rapid digital transformation, organizations increasingly rely on diverse data sources for analytics, decision-making, and operational efficiency. Database federation emerges as a powerful solution for integrating and querying data from multiple, disparate databases without centralizing it into a single repository.
What is Database Federation?
Database federation is a technique in which multiple databases are virtually integrated into a unified interface, allowing users to query them as if they were a single database. Unlike data warehousing, federation focuses on real-time access and does not involve copying or transforming data.
Importance of Database Federation
Data Diversity− Integrates heterogeneous data sources like SQL databases, NoSQL databases, and APIs.
Real-Time Access− Enables on-demand queries without requiring pre-aggregation.
Cost Efficiency− Reduces the need for large-scale ETL (Extract, Transform, Load) processes.
This article explores the mechanics, benefits, challenges, architectures, and real-world use cases of database federation.
Database Federation vs. Other Integration Techniques
To understand the unique value of database federation, it’s essential to compare it with other data integration approaches.
Database Federation vs. Data Warehousing
Data Federation−
Provides real-time data access.
No physical storage of data; queries are executed on source databases.
Data Warehousing−
Consolidates data into a central repository.
Requires ETL processes for transformation and storage.
Database Federation vs. Data Virtualization
Federation is a subset of data virtualization, which encompasses more advanced capabilities like caching, transformation, and semantic layers.
Database Federation vs. Distributed Databases
Distributed databases manage a single dataset split across nodes, while federation unifies independent databases without altering their structures.
How Database Federation Works
Database federation enables seamless querying across disparate systems using a central interface. Here's how it functions−
Query Parsing and Optimization
A user submits a query through a federated query engine.
The engine parses the query and identifies the target databases involved.
Optimization techniques ensure efficient execution by pushing down operations to source databases whenever possible.
Data Retrieval
The engine retrieves results from source databases and combines them.
Results are presented as if they came from a single, unified database.
Middleware
The federation layer acts as middleware, connecting various databases with differing schemas, query languages, and data models.
Key Components of Federation
Federated Query Engine: Processes and optimizes queries.
Adapters/Connectors: Translate queries into formats compatible with each source database.
Schema Mapping: Ensures compatibility between different database schemas.
Benefits of Database Federation
Database federation offers several advantages, making it a go-to solution for organizations with diverse data ecosystems.
Real-Time Data Access
Federation allows querying live data, ensuring users work with the most current information. This is particularly valuable for time-sensitive applications like fraud detection and inventory management.
Cost Savings
By eliminating the need for data duplication, federation reduces infrastructure and storage costs associated with traditional data warehousing.
Flexibility and Scalability
Federation supports heterogeneous data sources, including relational databases (e.g., MySQL, PostgreSQL), NoSQL databases (e.g., MongoDB, Cassandra), and cloud storage (e.g., AWS S3).
Faster Integration
Since federation doesn’t involve data transformation or movement, integration timelines are significantly reduced.
Simplified Data Governance
Data remains in its original location, preserving source-specific security, compliance, and access controls.
Challenges of Database Federation
Despite its advantages, database federation presents several challenges that must be addressed for successful implementation.
Performance Issues
Queries spanning multiple databases can suffer from high latency, especially when sources are geographically dispersed.
Complex joins and aggregations across systems may overload the federated query engine.
Schema and Data Model Differences
Integrating databases with differing schemas, data types, and query languages requires significant schema mapping and transformation effort.
Limited Caching
Unlike data warehouses, federated systems typically lack caching mechanisms, which can impact query performance for frequently accessed data.
Security and Compliance Risks
Querying multiple databases in real-time can expose vulnerabilities in underlying systems.
Managing varying compliance requirements (e.g., GDPR, HIPAA) across sources can be complex.
Dependency on Middleware
The federation layer becomes a critical dependency. Any failure or misconfiguration in this layer can disrupt access to all connected databases.
Architectures of Database Federation
Database federation can be implemented using different architectural models, depending on organizational requirements.
Tight Federation
Offers a closely integrated system with high-level schema mapping.
Pros− Supports advanced query optimization and complex queries.
Cons− Requires significant upfront configuration and ongoing maintenance.
Loose Federation
Provides a more lightweight integration with minimal schema mapping.
Pros− Easier to implement and maintain.
Cons− Limited support for complex queries and optimizations.
Hybrid Federation
Combines tight and loose federation models, balancing flexibility and performance.
Example− Some data sources may have detailed schema mapping, while others are loosely integrated.
Cloud-Based Federation
Federation engines deployed in the cloud interact with on-premise and cloud databases.
Example Tools− AWS Athena, Google BigQuery.
Tools and Technologies for Database Federation
Several tools and technologies facilitate the implementation of database federation.
Apache Drill− An open-source, schema-free SQL query engine that supports diverse data sources, including relational databases, Hadoop, and NoSQL.
Dremio− A self-service data platform enabling data federation with advanced query acceleration and transformation features.
Presto− A distributed SQL query engine capable of querying data across various databases and object stores.
Amazon Athena− A serverless federated query engine integrated with AWS data sources, supporting SQL queries on S3 and other services.
Google BigQuery− Offers cross-database query capabilities with a focus on performance and scalability.
IBM Db2 Federation− Specialized for enterprise-grade database federation, supporting relational and non-relational databases.
Key Considerations When Choosing a Tool
Supported data sources and connectors.
Query optimization capabilities.
Scalability and cost.
Use Cases, Best Practices
Use Cases of Database Federation
Business Intelligence (BI)− Integrate data from CRM systems, ERP databases, and web analytics tools for real-time reporting.
Healthcare− Query patient data across hospitals while maintaining compliance with regulations like HIPAA.
E-commerce− Combine inventory data from multiple suppliers for unified stock visibility.
Finance− Access transactional and market data in real time for risk analysis.
Best Practices in Database Federation
Optimize Queries− Minimize cross-database joins and use push-down processing to delegate computations to source systems.
Monitor Performance− Implement monitoring tools to track query execution times and identify bottlenecks.
Maintain Security− Use secure connections and adhere to compliance requirements for each data source.
Plan for Failures− Design fallback mechanisms to handle failures in source databases or the federation layer.
Conclusion
Database federation bridges the gap between disparate data systems, enabling real-time access to unified information without the overhead of data consolidation. While it introduces complexities in query optimization and security, the benefits of flexibility, cost savings, and real-time insights make it a compelling solution for modern enterprises. As businesses embrace hybrid and multi-cloud environments, database federation will continue to play a pivotal role in simplifying data access and enabling smarter decision-making.
System Design - Designing Authentication System
Introduction
Databases are critical repositories of sensitive data for businesses, making their security paramount. Database authentication is the first line of defense in protecting these resources, ensuring that only authorized users or systems can access the database.
What is Database Authentication?
Database authentication is the process of verifying the identity of a user or application attempting to access a database. It establishes trust and allows the database to enforce policies based on roles and privileges.
Why is Database Authentication Important?
Protects Sensitive Data− Prevents unauthorized access to personal, financial, or proprietary information.
Ensures Compliance− Meets legal and regulatory requirements such as GDPR, HIPAA, or PCI DSS.
Prevents Data Breaches− Limits the risk of malicious access through strong identity verification mechanisms.
In this article, we will explore various aspects of database authentication, including mechanisms, best practices, common challenges, and real-world examples.
Types of Database Authentication
Database authentication can be categorized into several types, each tailored to specific use cases and security needs.
Password-Based Authentication
The most common method where users provide a username and password.
Advantages− Simple and widely supported.
Challenges− Vulnerable to brute-force attacks and phishing if not secured.
Token-Based Authentication
Uses tokens issued by an authentication server (e.g., OAuth tokens) to validate access.
Advantages− Tokens are temporary and reduce the risks associated with password sharing.
Use Case− Web applications and APIs accessing databases.
Certificate-Based Authentication
Relies on digital certificates issued by a trusted Certificate Authority (CA).
Advantages− Strong security through cryptographic validation.
Use Case− Enterprise environments with stringent security policies.
Multi-Factor Authentication (MFA)
Combines multiple methods, such as passwords and OTPs (One-Time Passwords).
Advantages− Enhanced security by requiring multiple forms of verification.
Use Case− Systems handling critical data like banking or healthcare.
Biometric Authentication
Uses fingerprints, facial recognition, or voice patterns for access.
Advantages− High security and convenience.
Challenges− Requires advanced hardware and raises privacy concerns.
Authentication Protocols and Standards
Several protocols and standards underpin secure database authentication.
LDAP (Lightweight Directory Access Protocol)
Provides centralized authentication using directory services like Active Directory.
Use Case− Corporate environments for managing user access.
Kerberos
A ticket-based authentication protocol that prevents the need for direct password transmission.
Advantages− Strong against replay attacks and credential theft.
OAuth and OpenID Connect
OAuth provides token-based authentication, while OpenID Connect enables identity verification.
Use Case− Federated systems and single sign-on (SSO) solutions.
TLS (Transport Layer Security)
Ensures encrypted connections, often used alongside other authentication methods.
Use Case− Securing communications between clients and databases.
SCRAM (Salted Challenge Response Authentication Mechanism)
A password-based mechanism with salting and hashing to mitigate brute-force attacks.
Use Case− MongoDB and PostgreSQL support SCRAM for secure user authentication.
Designing Secure Authentication Mechanisms
When designing database authentication, security must be integrated into every aspect of the system.
Use Strong Credentials
Enforce policies for complex passwords (length, special characters, etc.).
Avoid default credentials like "admin/admin" to minimize attack surfaces.
Implement Role-Based Access Control (RBAC)
Assign roles and privileges based on the principle of least privilege.
Ensure each user has only the necessary permissions for their tasks.
Secure Communication Channels
Always use encrypted connections such as TLS/SSL to protect credentials in transit.
Use VPNs for added security in accessing database servers remotely.
Enable MFA
Enhance security by requiring users to provide additional forms of authentication, such as hardware tokens or mobile-based OTPs.
Audit and Monitor Authentication Events
Maintain logs of login attempts and authentication failures.
Use anomaly detection tools to identify suspicious activity.
Challenges in Database Authentication
Designing a robust authentication mechanism involves addressing several challenges.
Balancing Security and Usability
Complex authentication mechanisms can frustrate users, leading to reduced productivity.
Designing intuitive workflows without compromising security is critical.
Managing Credential Storage
Securely storing passwords requires robust hashing algorithms like bcrypt or Argon2.
Improper storage mechanisms (e.g., plaintext passwords) can lead to catastrophic breaches.
Integrating with Legacy Systems
Older databases may not support modern authentication protocols, requiring additional tools or middleware.
Protecting Against Insider Threats
Malicious employees with access credentials pose a significant risk.
Implementing access controls and periodic reviews can mitigate these risks.
Ensuring Compliance
Meeting the requirements of regulations like GDPR, HIPAA, and PCI DSS can be challenging in distributed and multi-cloud environments.
Tools and Technologies for Database Authentication
Modern tools and frameworks streamline database authentication design and implementation.
Built-In Database Authentication Systems
MySQL− Offers native authentication methods and supports plugins for external authentication.
PostgreSQL− Supports SCRAM, LDAP, and certificate-based authentication.
MongoDB− Provides native support for role-based access and SCRAM.
Third-Party Authentication Platforms
Okta− Provides identity management and MFA capabilities.
Auth0− Supports OAuth, SSO, and custom authentication solutions.
Identity and Access Management (IAM) Tools
AWS IAM− Enables fine-grained control over database access in AWS environments.
Azure Active Directory− Provides SSO and centralized access management.
Password Managers and Secrets Management
HashiCorp Vault− Manages credentials and automates secret rotation.
AWS Secrets Manager− Secures and rotates database credentials.
Case Studies
Examining real-world implementations of database authentication provides valuable insights.
Banking Industry (Multi-Factor Authentication)
Scenario− A bank implemented MFA for customer database access to comply with PCI DSS.
Outcome− Reduced fraudulent access incidents and improved customer trust.
E-Commerce Platform (OAuth and Token-Based Authentication)
Scenario− An e-commerce giant used OAuth tokens to authenticate API requests between services and databases.
Outcome− Enhanced scalability and secured API interactions.
Healthcare Sector (Certificate-Based Authentication)
Scenario− A hospital implemented certificate-based authentication for secure database access.
Outcome− Achieved HIPAA compliance while ensuring seamless data access for medical staff.
Best Practices for Database Authentication
To design effective database authentication mechanisms, follow these best practices−
Regularly Rotate Credentials
Implement automatic rotation for passwords, certificates, and tokens to limit exposure risks.
Use Federated Authentication for Scalability
Leverage federated identity systems like SAML and OpenID Connect to streamline access for large user bases.
Apply Zero Trust Principles
Never trust any user or system by default; verify every access attempt regardless of location or previous trust.
Conduct Penetration Testing
Regularly test the authentication system for vulnerabilities and rectify them promptly.
Educate Users
Train users to recognize phishing attempts and follow best practices for secure password management.
Conclusion
Database authentication is a cornerstone of modern system security, protecting sensitive data from unauthorized access while ensuring compliance with regulatory standards. By adopting robust authentication mechanisms, leveraging modern tools, and adhering to best practices, organizations can safeguard their databases against evolving threats.
Future Outlook
As the cyber threat landscape evolves, database authentication will increasingly incorporate advanced technologies like AI-based anomaly detection and passwordless authentication methods, ensuring stronger and more user-friendly security.
By prioritizing database authentication in system design, organizations can build secure, resilient, and compliant systems for the future.
Database Design Vs. Database Architecture
Introduction
Databases are central to modern technology, underpinning systems ranging from small-scale applications to global enterprises. The terms "database design" and "database architecture" often surface in discussions about creating and managing databases. While they are closely related, they serve distinct purposes. This article delves into the differences, synergies, and best practices of database design and database architecture.
Understanding Database Design
Definition and Goals
Database design involves creating a blueprint for how data will be stored, organized, and managed. It focuses on the logical and physical structuring of data to ensure optimal efficiency, reliability, and scalability.
Key Components
Data Modelling− Creating logical and physical data models to represent data relationships. Tools like ER diagrams are commonly used.
Normalization− Ensuring data is stored efficiently by removing redundancies.
Schema Definition− Structuring tables, columns, indexes, and constraints.
Data Integrity and Security− Designing mechanisms to enforce data accuracy and access control.
Exploring Database Architecture
Definition and Objectives
Database architecture refers to the overarching framework that dictates how a database system interacts with applications, users, and other systems. It encompasses the technical and structural components of the database's operation.
Major Elements
Layers of Architecture−
Internal Layer− Physical storage and access mechanisms.
Conceptual Layer− Abstract representation of the database structure.
External Layer− User views and interaction mechanisms.
System Components−
Query processors, transaction managers, and storage engines.
Middleware enabling distributed and cloud architectures.
Infrastructure−
Servers, storage solutions, and networks supporting the database system.
Database Design v/s Database Architecture
Key Differences
| Sr.No. | Aspect | Database Design | Database Architecture |
|---|---|---|---|
| 1 | Focus | Structure and organization of data. | Framework for database operations and integration. |
| 2 | Scope | Micro-level (schemas, tables). | Macro-level (infrastructure, software layers). |
| 3 | Primary Users | Database designers, developers. | Architects, system administrators. |
| 4 | Tools Used | ER modelling tools, schema editors. | Infrastructure design tools, system design software. |
Roles and Responsibilities
Database Designers− Responsible for schema creation and optimization.
Database Architects− Oversee the system’s integration with other technologies, scalability, and performance.
The Interplay Between Database Design and Architecture
Database design and architecture are interdependent. Effective database systems require a solid design foundation and a well-thought-out architecture. For instance−
A well-designed schema must align with the architectural goals (e.g., scalability).
Architectural decisions, such as choosing distributed databases, influence design choices like sharding.
Example− In a cloud-based database, architecture dictates the distributed nature, requiring a schema design optimized for partitioning.
Best Practices for Effective Database Design and Architecture
For Database Design
Begin with comprehensive requirements gathering.
Prioritize normalization, but balance it with performance needs.
Incorporate indexing for faster query performance.
Regularly update and optimize the schema.
For Database Architecture
Use modular and scalable architectures (e.g., microservices, cloud integration).
Implement robust security measures, including encryption and access controls.
Ensure redundancy and backups to prevent data loss.
Use automation for monitoring and maintenance.
Case Studies Illustrating the Differences and Interplay
Case Study 1: E-Commerce Platform
Database Design Focus− Creating normalized schemas for products, customers, and orders.
Database Architecture Focus− Supporting high-traffic scenarios using a distributed database setup.
Case Study 2: Financial Application
Database Design Focus− Ensuring data accuracy through constraints and validations.
Database Architecture Focus− Implementing multi-layer security and disaster recovery mechanisms.
Challenges and Solutions in Database Design and Architecture
Challenges in Database Design
Balancing normalization with performance.
Adapting schemas for evolving requirements.
Solutions
Use hybrid design approaches, such as denormalization for read-heavy applications.
Incorporate agile methodologies to iterate designs.
Challenges in Database Architecture
Integrating legacy systems with modern architectures.
Ensuring scalability without compromising performance.
Solutions
Use middleware solutions for seamless integration.
Leverage cloud platforms for on-demand scalability.
Conclusion
Database design and architecture, while distinct, are complementary disciplines critical to creating robust, efficient, and scalable database systems. By understanding their unique roles and interdependencies, organizations can better manage their data and support growing technological demands. The synergy between design and architecture is the cornerstone of modern database solutions, ensuring that both data and systems evolve seamlessly with changing business needs.
Database Federation vs. Database Sharding
Introduction
Modern businesses deal with massive amounts of data distributed across diverse locations and systems. Efficient management of this data is critical for operational performance, scalability, and user satisfaction. Two popular strategies for handling large and distributed datasets are database federation and database sharding.
While both approaches enable efficient data management, they serve different purposes and are suited to distinct scenarios. This article explores the concepts of database federation and database sharding, highlighting their differences, advantages, challenges, and use cases to help organizations make informed decisions.
Understanding Database Federation
Database federation refers to a system where multiple independent databases are connected to form a unified interface or a single virtual database. In a federated database, each participating database retains its autonomy, meaning it operates independently while allowing cross-database queries.
Key Features
A federated database system acts as a mediator, enabling unified access to disparate databases without physically merging their data.
Centralized query processing translates a global query into subqueries executed on individual databases.
The federated architecture supports diverse database technologies (e.g., relational, NoSQL) and structures.
Advantages
Data Autonomy− Participating databases maintain independence, allowing administrators to manage them without overarching restrictions.
Cross-Database Queries− Facilitates querying data from multiple sources without moving or duplicating it.
Scalability− Simplifies adding new databases to the federation.
Heterogeneity− Supports integration of databases with different formats, schemas, and management systems.
Challenges
Performance Overhead− Querying multiple databases can lead to increased latency.
Complex Query Optimization− Translating global queries into efficient subqueries for diverse databases is challenging.
Data Consistency− Ensuring consistency across independent systems can be difficult.
Exploring Database Sharding
Database sharding involves partitioning a large dataset into smaller, more manageable segments called shards, which are distributed across multiple servers or nodes. Each shard contains a subset of the data and operates as an independent database.
Key Features
Sharding divides data horizontally, with each shard containing complete rows or records based on predefined criteria (e.g., customer ID, region).
Applications access specific shards based on the sharding key, reducing the volume of data processed per query.
Shards are typically identical in structure but differ in content.
Advantages
Improved Performance− Sharding distributes the workload across servers, reducing bottlenecks.
Scalability− Adding new shards allows seamless scaling to accommodate growing datasets.
Fault Tolerance− Shard independence reduces the risk of a complete system failure.
Challenges
Complex Management− Maintaining shard configurations and balancing loads across servers requires significant effort.
Query Complexity− Cross-shard queries are more complex and may require aggregation across shards.
Data Rebalancing− Adding new shards or changing shard keys necessitates redistribution, which can disrupt operations.
Key Differences Between Database Federation and Database Sharding
| Sr.No. | Aspect | Database Federation | Database Sharding |
|---|---|---|---|
| 1 | Definition | Unified access to multiple independent databases. | Horizontal partitioning of data into smaller shards. |
| 2 | Structure | Independent databases with a unified virtual layer. | Shards are interdependent parts of a larger dataset. |
| 3 | Data Distribution | Data remains in original databases. | Data is divided and distributed across shards. |
| 4 | Scalability | Adds databases to the federation. | Adds shards to distribute data and workload. |
| 5 | Query Handling | Translates global queries into subqueries. | Queries are directed to specific shards based on the shard key. |
| 6 | Performance | May experience latency for complex queries. | Optimized for high performance with isolated shards. |
| 7 | Use Cases | Integration of heterogeneous databases. | High-throughput systems with large datasets. |
Use Cases for Database Federation
Scenario 1: Integrating Diverse Databases
Large organizations often have multiple databases for various departments (e.g., sales, HR, logistics). Federation enables unified access to these systems for cross-departmental reporting and analytics.
Scenario 2: Multi-Cloud or Hybrid Cloud Systems
Federation facilitates seamless querying across on-premise and cloud-based databases, ensuring operational flexibility without significant migration efforts.
Scenario 3: Data Aggregation
Federated systems are ideal for businesses that rely on aggregating data from partners, vendors, or external sources without centralizing it.
Use Cases for Database Sharding
Scenario 1: High-Traffic Applications
Applications with millions of users, such as e-commerce platforms, benefit from sharding to handle high query loads without degrading performance.
Scenario 2: Geographically Distributed Users
Sharding based on geographic regions improves latency by storing data closer to users, reducing query response times.
Scenario 3: Large-Scale Data Systems
Data-intensive industries like social media or streaming services use sharding to store massive datasets efficiently across distributed servers.
Factors to Consider When Choosing Between Federation and Sharding
System Complexity
If the goal is to integrate existing, independent databases, federation is a better choice.
For systems requiring distributed datasets to improve performance, sharding is more suitable.
Scalability Needs
Federation scales by adding more databases, making it ideal for heterogeneous and distributed environments.
Sharding scales by adding more shards, ideal for homogeneous data growth.
Query Complexity
Federation excels in environments where cross-database queries are necessary.
Sharding is optimal for systems with localized queries targeting specific shards.
Performance Considerations
Federation may encounter performance bottlenecks due to cross-database operations.
Sharding improves query performance by isolating data access to specific shards.
Data Consistency
Federation may face challenges in synchronizing data across independent databases.
Sharding ensures consistency within shards but complicates cross-shard consistency.
Conclusion
Database federation and database sharding are powerful strategies for managing distributed data, but their applications differ significantly. Federation focuses on unifying disparate databases while preserving their independence, making it ideal for multi-system integrations. Sharding, on the other hand, emphasizes partitioning datasets for performance and scalability, suiting high-volume applications.
Organizations must carefully assess their data structure, scalability requirements, query patterns, and operational goals to choose the most appropriate approach. By leveraging the strengths of each strategy, businesses can ensure robust and efficient data management tailored to their unique needs.
System Design - High Level Design
Introduction
System Design is an essential phase of software development where a blueprint is created for building a robust, scalable, and maintainable system. It has two major components−
High-Level Design (HLD)− Focuses on the system's architecture, major components, and their interactions.
Low-Level Design (LLD)− Delves into the detailed implementation of the components defined in HLD.
This article focuses on High-Level Design, explaining its role in system design, key components, tools, techniques, and challenges.
In modern software engineering, systems must meet growing demands for scalability, reliability, and usability. High-Level Design lays the groundwork for creating systems that fulfill these criteria, ensuring smooth development and operations.
What is High-Level Design in System Design?
Definition
High-Level Design (HLD) provides a macro view of the system. It outlines the architecture, subsystems, modules, and how they interact. Unlike Low-Level Design, which deals with specific implementations, HLD focuses on−
The system's major components.
Communication protocols between components.
Scalability and performance considerations.
HLD often represents the "what" of a system, while LLD answers the "how."
Goals of High-Level Design
Clarity− Provide a clear and shared understanding of the system's architecture.
Direction− Guide developers by offering an architectural roadmap.
Scalability− Anticipate future growth and design for it.
Alignment− Ensure that technical decisions align with business objectives.
Key Components of High-Level Design
A well-defined High-Level Design typically includes−
System Architecture
This defines the overall structure, including−Architectural pattern− Monolithic, Microservices, Event-driven, or Serverless.
Core layers− Presentation layer, business logic layer, and data layer.
Deployment model− On-premises, cloud, or hybrid.
Subsystems and Modules
HLD breaks down the system into logical subsystems or modules. For example−E-commerce system− Modules like User Management, Order Management, and Inventory.
Data Flow
Describes how data flows across components and external systems. This includes−Input/Output specifications.
Communication protocols (e.g., HTTP, gRPC).
External integrations (e.g., APIs, message queues).
Database Design
Defines high-level database structures, such as−Choice of databases− Relational (MySQL) or NoSQL (MongoDB).
Partitioning and sharding strategies for scalability.
Non-Functional Requirements (NFRs)
Addresses aspects like−Scalability− Handle increasing load efficiently.
Availability− Minimize downtime (e.g., 99.99% uptime).
Security− Protect sensitive data.
Performance− Optimize for latency and throughput.
Interfaces and APIs
Defines interaction points between internal and external systems. For example−RESTful APIs or GraphQL endpoints.
Data formats like JSON or XML.
Principles of High-Level Design
High-Level Design must adhere to key principles to ensure a robust system−
Modularity− Divide the system into independent, loosely coupled modules to improve maintainability.
Scalability− Design to handle future growth in users, traffic, or data.
Performance− Optimize response times and minimize resource usage.
Security− Ensure components are protected from potential vulnerabilities.
Reusability− Design modules that can be reused across multiple projects.
Reliability and Fault Tolerance− Create fail-safe mechanisms to handle errors or outages gracefully.
Simplicity− Avoid over-engineering; keep the design easy to understand and implement.
The Process of High-Level Design
Creating a High-Level Design involves several steps−
Gather Requirements
Collect functional and non-functional requirements from stakeholders. For example−
Functional− User authentication, product recommendations.
Non-functional− 99.99% uptime, 200ms response time.
Choose an Architecture
Decide on an architectural pattern that best suits the requirements−
Monolithic− Suitable for small, simple systems.
Microservices− Ideal for scalability and modularity.
Event-Driven− For real-time applications like IoT.
Serverless− For event-based, cost-efficient systems.
Define Major Components
Identify and define the system's major components, such as−
Application servers.
Databases.
Load balancers.
Specify Data Flow
Map how data travels between components and external systems.
Document and Visualize
Use diagrams to represent the system design, such as−
UML diagrams (Class, Sequence, and Deployment diagrams).
Data flow diagrams.
Component diagrams.
Tools and Techniques for High-Level Design
Tools
Lucidchart− Ideal for flowcharts and architecture diagrams.
Draw.io− Free tool for creating component and data flow diagrams.
Microsoft Visio− Professional diagramming software.
Enterprise Architect− Advanced tool for UML and system modelling.
Techniques
Unified Modelling Language (UML)− Standardized visual representations.
Data Flow Modelling− Illustrate how data moves within the system.
Component-Based Design− Focus on defining reusable components.
Examples of High-Level Design
Example 1: E-Commerce Platform
Components−
Presentation Layer− Angular-based frontend.
Backend Services− Microservices using Spring Boot.
Database− Relational database for transactions, NoSQL for caching.
Load Balancer− Ensures high availability.
Data Flow−
User requests → API Gateway → Microservices → Database → Response.
Example 2: Video Streaming Service
Components−
Content Delivery− CDN for streaming content.
Recommendation Engine− Machine Learning-based personalization.
Authentication Service− OAuth2 for secure login.
Data Flow−
Video request → CDN → Backend services → Database → Response.
Common Challenges in High-Level Design
Requirement Ambiguity− Incomplete or vague requirements can lead to incorrect designs.
Scalability Trade-offs− Balancing scalability with cost and complexity.
Integration Complexity− Ensuring seamless communication between heterogeneous systems.
Over-Engineering− Avoiding unnecessary complexity in the design.
Evolving Requirements− Adapting the design to accommodate changes in requirements.
Conclusion
High-Level Design is a critical phase in system design, providing a roadmap for creating scalable, secure, and maintainable systems. By focusing on architecture, data flow, and NFRs, it ensures that the development team has a clear and shared understanding of the system.
Adhering to principles like modularity, scalability, and simplicity, while leveraging tools like UML and diagramming software, can significantly enhance the quality of your High-Level Design. A well-crafted HLD lays the foundation for a system that meets both current and future demands.
System Design - Availability
Introduction
In the digital era, users expect systems to be available 24/7 without interruptions. Availability is one of the critical pillars of system design, especially for systems that serve millions of users worldwide, such as e-commerce platforms, cloud services, and financial systems.
This article explores the concept of availability, its importance, and strategies for designing highly available systems. It also examines the trade-offs and challenges associated with achieving high availability.
What is Availability in System Design?
Availability refers to the ability of a system to perform its intended function at any given time. It measures the proportion of time a system is operational and accessible to users, despite failures or maintenance activities.
Formula for Availability
Availability is calculated using the following formula−
Availability (%) = [ Uptime / (Uptime + Downtime) ] × 100
For example−
A system with 99.9% availability means it is down for approximately 8.76 hours per year.
Key Characteristics of High Availability
Minimal downtime.
Fault tolerance to handle hardware/software failures.
Quick recovery mechanisms.
Importance of Availability
Availability is vital for−
User Experience− Downtime can frustrate users, leading to loss of trust and revenue.
Business Continuity− Downtime disrupts operations and can result in financial losses.
Reputation− High availability enhances a company's reputation and reliability.
Legal and Compliance− Some industries, such as healthcare and finance, have strict availability requirements.
Measuring Availability
Availability Levels
Availability is often expressed using nines−
99% Availability (Two Nines)− 3.65 days of downtime per year.
99.9% Availability (Three Nines)− 8.76 hours of downtime per year.
99.99% Availability (Four Nines)− 52.56 minutes of downtime per year.
99.999% Availability (Five Nines)− 5.26 minutes of downtime per year.
Key Metrics
Mean Time Between Failures (MTBF)− Average time between system failures.
Mean Time to Repair (MTTR)− Average time taken to recover from a failure.
Strategies to Improve System Availability
Achieving high availability requires a combination of design strategies and operational practices−
Achieving high availability requires a combination of design strategies and operational practices−
Redundancy
Redundancy ensures that even if one component fails, another can take over seamlessly. Types of redundancy−
Hardware Redundancy− Multiple servers, storage systems, or power supplies.
Network Redundancy− Backup routes or duplicate network interfaces.
Data Redundancy− Replicated databases across multiple regions.
Failover Mechanisms
Failover is the process of switching to a backup system when the primary system fails. Key techniques−Active-Passive− A standby system remains inactive until the primary fails.
Active-Active− Both systems handle traffic simultaneously, improving performance.
Load Balancing
Distributes traffic across multiple servers to ensure no single server becomes a point of failure.
DNS Load Balancing− Distributes traffic using domain name resolution.
Application Load Balancers− Distribute requests at the application level.
Global Load Balancers− Distribute traffic across multiple regions.
Backup and Recovery
Regular backups ensure data recovery during failures. Types−
Full Backups− Copies all data.
Incremental Backups− Copies only changes since the last backup.
Snapshot Backups− Captures the system state at a specific point in time.
Monitoring and Alerting
Monitoring tools help detect failures and trigger alerts. Examples−
Tools− Prometheus, Grafana, AWS CloudWatch.
Metrics− Uptime, latency, error rates, and resource utilization.
Trade-offs in Achieving High Availability
Achieving high availability often requires balancing trade-offs−
Cost vs. Availability
Redundancy and failover mechanisms can be expensive. Businesses must evaluate the cost of downtime versus the investment in availability.
Complexity
High-availability systems can be complex to design, implement, and maintain.
Performance vs. Consistency
Replication for redundancy can introduce latency or lead to inconsistent data.
Architectural Patterns for High Availability
Multi-Region Deployment
Deploying systems in multiple geographic regions ensures availability even if one region fails.
Example− AWS or Azure regions.
Replication
Database replication ensures availability and reliability.
Types−
Synchronous Replication− Ensures data consistency but adds latency.
Asynchronous Replication− Improves performance but may result in eventual consistency.
Circuit Breaker Pattern
Prevents cascading failures by temporarily blocking access to a failing component.
Example− Netflix's Hystrix library.
Event-Driven Architecture
Decouples components using message queues, allowing the system to remain operational even if one component fails.
Tools− Kafka, RabbitMQ.
Real-World Examples
Example 1: E-Commerce Platform
An e-commerce platform ensures high availability by−
Using auto-scaling groups to handle traffic spikes.
Implementing global load balancers for regional traffic distribution.
Replicating databases across multiple data centers.
Example 2: Video Streaming Service
A video streaming service ensures high availability by−
Utilizing CDNs (Content Delivery Networks) to serve content quickly.
Implementing microservices architecture to isolate failures.
Monitoring system health with real-time alerts.
Conclusion
Availability is a cornerstone of system design that directly impacts user experience, business continuity, and reputation. Designing highly available systems requires careful planning, robust architecture, and effective monitoring.
By implementing strategies like redundancy, failover mechanisms, load balancing, and backup systems, organizations can ensure their systems meet high availability requirements. While achieving 100% availability is impossible, striving for "five nines" (99.999%) availability is the goal for mission-critical systems.
In conclusion, high availability is not a one-time effort but an ongoing process of optimization and improvement, ensuring that systems remain reliable in the face of evolving challenges.
System Design - Consistency
Introduction
Consistency is a fundamental concept in system design, particularly in distributed systems. It determines how data remains uniform and reliable across multiple nodes in a system. Ensuring consistency is critical for systems where users expect accurate, predictable behavior, such as financial systems, e-commerce platforms, or collaborative applications.
This article delves into the concept of consistency, its types, and the strategies to achieve it. We will also discuss the challenges and trade-offs in maintaining consistency while balancing other system requirements like availability and performance.
What is Consistency in System Design?
system see the same state of data at any given time. For example, if a bank account has a balance of $500, two users accessing the account from different locations should see the same balance.Consistency in Distributed Systems
In system design, consistency refers to the property of ensuring that all clients or nodes in a system see the same state of data at any given time. For example, if a bank account has a balance of $500, two users accessing the account from different locations should see the same balance.
Consistency in Distributed Systems
In distributed systems, consistency involves synchronizing data across multiple servers or nodes to ensure correctness. However, achieving perfect consistency in such systems can be challenging due to factors like network latency, partitioning, and concurrent updates.
The Importance of Consistency
Consistency plays a crucial role in system design because−
Data Integrity− Prevents errors caused by stale or incorrect data.
Predictability− Ensures users receive accurate, predictable outcomes.
Trust and Reliability− Builds user trust by maintaining accurate records.
Business Logic− Supports critical operations, such as financial transactions or stock management, that depend on correct data.
CAP Theorem and Consistency
What is the CAP Theorem?
The CAP theorem, proposed by Eric Brewer, states that a distributed system can only achieve two of the following three properties simultaneously−
Consistency (C)− All nodes have the same data at the same time.
Availability (A)− The system is operational and responsive to requests.
Partition Tolerance (P)− The system continues to function despite network partitions.
Consistency in CAP
In systems prioritizing consistency (C), every read operation reflects the most recent write. However, this may come at the cost of availability during network partitions.
Types of Consistency Models
Consistency models define how and when updates to a distributed system become visible to users. They include−
Strong Consistency
Ensures that all clients see the most recent data after a write operation.
Example− Traditional relational databases like MySQL.
Eventual Consistency
Guarantees that all nodes will converge to the same state eventually, though not immediately.
Example− DNS systems or NoSQL databases like Cassandra.
Causal Consistency
Guarantees that causally related operations are seen by all nodes in the same order.
Example− Collaborative editing tools.
Read-Your-Writes Consistency
Ensures that after a user writes data, they will see their own updates in subsequent reads.
Example− User profile updates on social media.
Challenges in Achieving Consistency
Maintaining consistency in distributed systems presents several challenges−
Network Latency− Delays in communication between nodes can lead to stale data.
Partitioning− Network partitions can disrupt data synchronization.
Concurrency− Concurrent updates from multiple clients can lead to conflicts.
Scalability− Ensuring consistency across a large number of nodes can reduce system performance.
Cost− Consistency mechanisms, such as consensus algorithms, can be resource-intensive.
Techniques for Ensuring Consistency
Two-Phase Commit (2PC)
A protocol for coordinating transactions across multiple nodes−
Prepare Phase− Nodes vote on whether to commit the transaction.
Commit Phase− If all nodes agree, the transaction is committed.
Drawback− 2PC can block nodes during failures, impacting availability.
Quorum-Based Replication
In this method−
A quorum is a majority of nodes required to acknowledge a write or read.
Example−
Write Quorum− Data is written to W nodes.
Read Quorum− Data is read from R nodes.
Ensures consistency if R+W > NR + W > N (total nodes).
Consensus Algorithms
These algorithms help nodes agree on a single source of truth.
Paxos− Guarantees consensus in the presence of node failures.
Raft− Simpler and easier-to-understand alternative to Paxos.
Conflict Resolution Strategies
When concurrent updates conflict, strategies include−
Last Write Wins (LWW)− The most recent update overwrites older ones.
Custom Application Logic− Application-specific rules for resolving conflicts.
Vector Clocks− Track causality to identify conflicts.
Trade-offs in Consistency
Designing for consistency often involves trade-offs with other system properties−
Consistency vs. Availability
Systems prioritizing availability may sacrifice consistency during failures (e.g., eventual consistency).
Consistency vs. Performance
Strong consistency requires synchronization across nodes, increasing latency.
Consistency vs. Scalability
Maintaining consistency in highly scalable systems can lead to bottlenecks.
Real-World Examples
Example 1: Banking Systems
Strong consistency ensures that a user's bank balance is always accurate, even with concurrent transactions.
Techniques− Distributed transactions, 2PC.
Example 2: Social Media Platforms
Eventual consistency is often sufficient for non-critical operations like post visibility.
Techniques− Replication with conflict resolution.
Example 3: E-Commerce Websites
Product inventory must maintain strong consistency to prevent overselling.
Techniques− Consensus algorithms or locking mechanisms.
Conclusion
Consistency is a critical aspect of system design, ensuring data integrity, reliability, and predictability. While strong consistency guarantees correctness, eventual consistency offers better performance and scalability in certain use cases.
Understanding the trade-offs between consistency, availability, and performance is key to designing effective distributed systems. By leveraging techniques like quorum-based replication, consensus algorithms, and conflict resolution strategies, architects can strike a balance that meets the system’s functional and non-functional requirements.
In conclusion, consistency in system design is not a one-size-fits-all solution. It requires careful consideration of the system’s goals, user expectations, and operational constraints.
System Design - Reliability
Introduction
In today’s digital world, users expect systems to perform their intended functions without failure, regardless of environmental conditions or usage spikes. Reliability is a critical aspect of system design, ensuring that systems meet these expectations.
This article explores the concept of reliability, its importance, and how to design reliable systems. It also discusses the challenges and trade-offs associated with reliability in system design, along with real-world examples.
What is Reliability in System Design?
Reliability in system design refers to the ability of a system to function as expected under predefined conditions for a specified period. A reliable system−
Operates without failure.
Handles errors gracefully.
Ensures data integrity and correctness.
For instance, in a reliable banking system, a user’s transaction should be processed accurately even during high traffic or partial system failures.
Importance of Reliability
Reliability is crucial for several reasons−
User Satisfaction− Unreliable systems frustrate users, leading to loss of trust.
Business Continuity− Ensures uninterrupted operations, reducing revenue loss.
Brand Reputation− Reliable systems enhance the reputation of a business.
Compliance− Some industries require strict adherence to reliability standards, e.g., healthcare and finance.
Reliability vs. Availability
Although related, reliability and availability are distinct concepts−
Reliability− Focuses on a system’s ability to perform without failure.
Availability− Measures the proportion of time the system is operational and accessible.
For example
A system with 99.99% availability may still be unreliable if frequent but brief failures occur.
Key Metrics for Reliability
Reliability is quantified using several key metrics−
Mean Time Between Failures (MTBF)
The average time between system failures.
MTBF = Total Operational Time / Number of Failures
A high MTBF indicates better reliability.
Mean Time to Repair (MTTR)
The average time taken to restore a system after a failure.
MTTR = Total Downtime / Number of Failures
Lower MTTR improves reliability by minimizing downtime.
Failure Rate
The frequency of failures over a specific period.
Failure Rate = Number of Failures / Time
Service Level Objectives (SLOs)
Defines reliability goals, such as 99.9% uptime or 95% success rates for API calls.
Factors Affecting System Reliability
Several factors influence reliability, including−
Hardware Failures− Faulty hardware components can cause outages.
Software Bugs− Coding errors can lead to system crashes or incorrect results.
Network Issues− Latency, packet loss, or disconnections reduce reliability.
Scaling Challenges− Systems may fail under unexpected traffic spikes.
Operational Errors− Human errors during system maintenance or updates.
Strategies for Building Reliable Systems
Achieving high reliability requires a combination of architectural choices, operational strategies, and testing practices.
Redundancy
Adding redundant components ensures that a system continues to operate even if one component fails. Types include−
Hardware Redundancy− Multiple servers, power supplies, or storage devices.
Data Redundancy− Replicating databases or files across multiple locations.
Fault Tolerance
Fault tolerance enables systems to handle failures without affecting user experience.
Active-Active Architecture− All components handle traffic, so failure in one does not impact availability.
Active-Passive Architecture− A standby component activates only during a failure.
Monitoring and Alerting
Proactive monitoring detects issues before they impact users.
Tools− Prometheus, Grafana, Datadog.
Metrics− Latency, error rates, system health indicators.
Failover Mechanisms
Failover redirects traffic from a failing component to a backup.
DNS Failover− Redirects traffic to a backup server.
Database Failover− Switches to a replica database.
Testing for Reliability
Testing helps identify and fix potential failure points−
Chaos Engineering− Introduces random failures to test system resilience (e.g., Netflix’s Chaos Monkey).
Load Testing− Simulates high traffic to assess performance under stress.
Recovery Testing− Verifies how quickly a system recovers from failures.
Trade-offs in Achieving Reliability
Reliability often involves trade-offs with other system properties−
Reliability vs. Cost− Redundancy and fault-tolerant mechanisms can be expensive.
Reliability vs. Complexity− Adding reliability features can make the system more complex to design and maintain.
Reliability vs. Performance− Techniques like replication can introduce latency, affecting performance.
Reliability in Real-World Systems
Example 1: Banking Systems
Reliability ensures accurate transaction processing.
Strategies Distributed databases, two-phase commit protocols.
Example 2: Content Delivery Networks (CDNs)
Reliability ensures uninterrupted content delivery even during server outages.
Strategies− Data replication, global load balancing.
Example 3: E-commerce Platforms
Reliability ensures orders are processed accurately, even during traffic spikes.
Strategies− Auto-scaling, database partitioning, caching mechanisms.
Conclusion
Reliability is a cornerstone of system design, directly impacting user experience, business operations, and trust. By focusing on strategies such as redundancy, fault tolerance, and proactive monitoring, architects can design systems that are resilient to failures.
However, achieving reliability is not without challenges. It requires careful consideration of trade-offs between cost, complexity, and performance. Real-world systems demonstrate how a balanced approach can ensure reliability while meeting other business goals.
In conclusion, reliability is an ongoing process that involves continuous testing, monitoring, and optimization to meet ever-evolving user expectations and operational demands.
System Design - CAP Theorem
Introduction
In the world of distributed systems, the CAP theorem is a fundamental concept that shapes the design of modern databases and applications. First introduced by Eric Brewer in 2000, the CAP theorem highlights the inherent trade-offs that distributed systems face when balancing consistency, availability, and partition tolerance.
Understanding the CAP theorem is crucial for designing scalable and fault-tolerant systems. This article will provide an in-depth explanation of the theorem, its implications, and its applications in real-world scenarios.
What is the CAP Theorem?
The CAP theorem states that a distributed system can only guarantee two out of the following three properties at any given time−
Consistency (C)− Every read receives the most recent write or an error.
Availability (A)− Every request receives a response, even if it is not the most recent data.
Partition Tolerance (P)− The system continues to function despite network partitions.
In essence, no distributed system can achieve all three properties simultaneously. This constraint forces system designers to make trade-offs based on their use case and requirements.
The Components of CAP Theorem
Consistency (C)
Consistency ensures that all nodes in a distributed system reflect the same data at any given time. For example−
If one node updates a value, other nodes in the system should reflect that updated value immediately.
Example− Traditional relational databases like MySQL prioritize consistency.
Availability (A)
Availability ensures that the system always provides a response to user requests, regardless of the state of individual nodes. However, the response may not always reflect the most recent data.
Example− Systems like DNS ensure high availability even at the expense of providing slightly outdated data.
Partition Tolerance (P)
Partition tolerance ensures that the system continues to operate despite communication failures between nodes. Network partitions, caused by hardware failures or connectivity issues, are unavoidable in distributed systems.
Example− Modern distributed databases like Cassandra and MongoDB prioritize partition tolerance.
Partition Tolerance (P)
Partition tolerance ensures that the system continues to operate despite communication failures between nodes. Network partitions, caused by hardware failures or connectivity issues, are unavoidable in distributed systems.
Example− Modern distributed databases like Cassandra and MongoDB prioritize partition tolerance.
The Implications of CAP Theorem
The CAP theorem implies that designers must make trade-offs between consistency, availability, and partition tolerance−
CP (Consistency, Partition tolerance) Systems− Focus on consistency and partition tolerance but sacrifice availability.
AP (Availability, Partition tolerance) Systems− Focus on availability and partition tolerance but sacrifice consistency.
CA (Consistency, Availability) Systems− Focus on consistency and availability but cannot handle network partitions.
In reality, partition tolerance is often a requirement for distributed systems, forcing a choice between consistency and availability.
Trade-offs in CAP Theorem
Choosing Between Consistency and Availability
The decision to prioritize consistency or availability depends on the use case−
Consistency-Centric Systems (CP)−
Used in systems requiring strict correctness, such as financial transactions or inventory management.
Trade-off− May be unavailable during network partitions.
Availability-Centric Systems (AP)−
Used in systems prioritizing uptime over strict correctness, such as social media feeds or caching layers.
Trade-off− May serve outdated data during network partitions.
Partition Tolerance as a Requirement
Partition tolerance is critical in distributed systems due to−
Network failures, latency, or disconnections.
Scalability requirements across geographically distributed nodes.
Since network partitions are inevitable, the CAP theorem forces designers to choose between consistency and availability during these events.
Consistency Models in CAP
Consistency models define how and when updates to data become visible in a distributed system. Key models include−
Strong Consistency
Guarantees that all clients see the same data after an update.
Ensures correctness but can increase latency.
Example− Traditional databases using ACID transactions.
Eventual Consistency
Ensures that all nodes converge to the same state eventually, though not immediately.
Prioritizes availability and performance.
Example− NoSQL databases like DynamoDB or Cassandra.
Weak Consistency
Provides no guarantees about when data updates will be visible.
Example− Systems with eventual synchronization during low-priority tasks.
Real-World Applications of CAP
Relational Databases (CP Systems)
Relational databases prioritize consistency and partition tolerance−
Use Cases− Financial systems, e-commerce transactions.
Example− MySQL, PostgreSQL.
NoSQL Databases (AP Systems)
NoSQL databases prioritize availability and partition tolerance−
Use Cases− Content delivery, social media, IoT systems.
Example− Cassandra, MongoDB.
Distributed Caches (CA Systems)
Distributed caching systems prioritize fast responses−
Use Cases− Web page loading, search results.
Example− Redis, Memcached.
Challenges of CAP Theorem in Modern Systems
While CAP theorem provides a useful framework, it has limitations−
Binary Choices− In practice, systems often achieve a balance between consistency and availability rather than strict adherence to one.
Latency Issues− Strong consistency models can introduce significant delays.
Evolving Architectures− Modern systems often employ hybrid strategies to mitigate CAP constraints.
Beyond CAP Theorem
Modern systems address CAP limitations using techniques like−
BASE Model (Basically Available, Soft state, Eventual consistency)− Focuses on availability and eventual consistency over strong guarantees.
Multi-Leader Replication− Ensures high availability while maintaining a degree of consistency.
Global Consensus Algorithms− Algorithms like Raft and Paxos address consistency in distributed environments.
Hybrid Models− Systems like Spanner achieve global consistency while maintaining high availability using techniques like TrueTime (Google’s proprietary clock synchronization).
Conclusion
The CAP theorem remains a cornerstone of distributed system design, guiding architects in making informed decisions about trade-offs. While it simplifies the understanding of consistency, availability, and partition tolerance, real-world systems often employ hybrid strategies to balance these properties.
Understanding CAP is essential for designing systems that align with specific business needs and technical constraints. By recognizing the inherent trade-offs and leveraging modern techniques, architects can create scalable, fault-tolerant, and efficient distributed systems.
System Design - API Gateway
Introduction
As modern software architectures embrace microservices, managing and exposing APIs has become increasingly complex. This is where an API Gateway comes into play. Acting as a single-entry point for client requests, an API Gateway simplifies communication between clients and backend services, enabling seamless interactions while handling common concerns like security, scalability, and performance.
This article dives into the concept of API Gateways, their features, design considerations, and real-world applications, emphasizing their importance in scalable system designs.
What is an API Gateway?
An API Gateway is a server that acts as an intermediary between clients (e.g., mobile apps, browsers) and backend services in a system. It manages and routes requests from clients to appropriate microservices, performing tasks like authentication, load balancing, and response transformation.
In essence, it:
Simplifies client-service interaction by providing a unified API interface.
Decouples clients from backend services, enabling flexibility and scalability.
Analogy− Think of an API Gateway as a receptionist in an office. Instead of clients reaching out to individual employees (services), the receptionist (API Gateway) routes their requests to the appropriate person.
Core Responsibilities of an API Gateway
An API Gateway provides several essential functionalities to streamline and secure communication between clients and services−
Routing Requests
The API Gateway determines which backend service should handle a client request based on routing rules. These rules can depend on−
URL patterns
HTTP methods (e.g., GET, POST)
Request headers
For Example
/user routes to the User Service.
/order routes to the Order Service.
Authentication and Authorization
API Gateways handle authentication (verifying user identity) and authorization (checking permissions) for incoming requests. By centralizing these processes, they ensure consistent enforcement of security policies.
Examples
Token-based authentication (JWT, OAuth).
API key validation.
Rate Limiting and Throttling
Rate limiting controls the number of requests a client can make in a given time frame, preventing abuse or overuse of resources. Throttling temporarily delays excessive requests.
Use Cases
Protecting backend services from traffic spikes.
Ensuring fair resource usage among clients.
Load Balancing
An API Gateway distributes incoming traffic across multiple instances of a service to prevent overloading and ensure high availability.Example− If the Product Service has three instances, the API Gateway balances requests among them.
Response Transformation
API Gateways can modify responses from backend services before sending them to clients. This includes−
Aggregating responses from multiple services.
Converting data formats (e.g., XML to JSON).
Removing sensitive information.
Why Use an API Gateway?
Using an API Gateway offers numerous benefits−
Centralized Management− All APIs are managed and monitored from a single-entry point.
Simplified Client-Side Development− Clients interact with a unified API instead of managing multiple service endpoints.
Enhanced Security− Security concerns like authentication, authorization, and rate limiting are centralized.
Scalability− API Gateways enable load balancing and traffic management for backend services.
Decoupling− Decouples clients from services, allowing independent evolution of APIs and microservices.
Key Features of an API Gateway
An effective API Gateway offers several key features−
Protocol Translation− Converts between protocols (e.g., REST to gRPC or HTTP to WebSocket).
Service Discovery Integration− Works with service discovery tools (e.g., Consul, Eureka) to locate services dynamically.
Caching− Temporarily stores responses to reduce load on backend services and improve response times.
Logging and Monitoring− Tracks API usage, errors, and performance metrics.
Custom Policies− Enables custom routing, transformation, and security policies.
Challenges and Considerations
Scalability
As the single-entry point for all traffic, the API Gateway can become a bottleneck. Proper scaling and failover mechanisms are critical.
Latency
Adding an API Gateway introduces an additional layer in the request path, potentially increasing latency. Minimizing this impact is essential.
Security
While API Gateways improve security, they can also become a single point of failure or target for attacks. Measures like rate limiting, WAFs (Web Application Firewalls), and monitoring help mitigate risks.
API Gateway vs. Service Mesh
API Gateway
Focuses on managing external client-to-service communication.
Handles API-specific features like routing, authentication, and rate limiting.
Service Mesh
Manages internal service-to-service communication within a microservices architecture.
Focuses on observability, security, and reliability of inter-service traffic.
In some systems, both tools are used together, with the API Gateway handling external traffic and the Service Mesh managing internal interactions.
Popular API Gateway Tools
Several tools and platforms provide robust API Gateway functionalities−
AWS API Gateway
Fully managed service by AWS.
Supports REST, HTTP, and WebSocket APIs.
Integration with AWS Lambda and other AWS services.
Kong
Open-source and highly customizable.
Built on NGINX for high performance.
Offers plugins for authentication, caching, and rate limiting.
Apigee
Enterprise-grade API management platform by Google.
Provides analytics, developer portals, and advanced security features.
NGINX
Lightweight, high-performance gateway solution.
Often used for routing and load balancing.
Best Practices for Designing an API Gateway
Use Stateless Design− Ensure the API Gateway doesn’t maintain state between requests, enabling easier scaling.
Enable Monitoring and Logging− Track API usage, latency, and errors to detect and resolve issues quickly.
Minimize Latency− Optimize routing and caching to reduce added overhead.
Implement Security Measures− Use encryption (TLS), authentication, and DDoS protection.
Ensure High Availability− Deploy API Gateways in a fault-tolerant setup across multiple regions.
Conclusion
API Gateways are a critical component of modern distributed systems, particularly in microservices architectures. They simplify client-service communication, enhance security, and enable scalability while centralizing API management.
However, designing an effective API Gateway requires careful consideration of performance, security, and scalability challenges. By leveraging best practices and appropriate tools, developers can create systems that meet the demands of today's dynamic environments.
From routing requests to ensuring reliability, the API Gateway is the backbone of seamless API communication, bridging the gap between clients and backend services effectively.
System Design - Low Level Design
Introduction
In system design, the focus is often split into two main areas: High-Level Design (HLD), which outlines the system's architecture and overall structure, and Low-Level Design (LLD), which delves into the detailed blueprint of the system. While HLD provides a bird's-eye view, LLD offers a zoomed-in perspective, focusing on individual components and their interactions.
This article explores the concept of Low-Level Design, its importance, and the steps involved in crafting it. It also highlights principles, challenges, and best practices to build robust and maintainable systems.
What is Low-Level Design (LLD)?
Low-Level Design refers to the process of designing the internal workings of individual components in a software system. It breaks down the abstract architectural ideas from HLD into concrete, implementable details.
Key characteristics of LLD
Detailed documentation of classes, methods, and interactions.
Definitions of how system components communicate internally.
Inclusion of diagrams like UML (Unified Modeling Language) to represent relationships and workflows.
LLD is typically created after HLD and is meant for developers who will implement the system. It bridges the gap between system architecture and actual code.
Importance of Low-Level Design in System Design
Bridges the Gap Between HLD and Code− LLD acts as a guideline for developers to implement the high-level architecture in code.
Improves Code Quality− By defining relationships, dependencies, and workflows beforehand, LLD ensures that the codebase adheres to design principles, making it maintainable and efficient.
Reduces Development Errors− With detailed specifications in place, developers are less likely to misinterpret the system requirements.
Facilitates Team Collaboration− LLD provides a common language (diagrams, patterns, and principles) for teams to discuss and refine system behavior.
Supports Testing and Debugging− A well-structured LLD makes it easier to identify and resolve issues during testing.
Key Components of Low-Level Design
To create an effective LLD, designers use various components, each serving a specific purpose in illustrating system details.
Class Diagrams
Show the relationships between classes, their attributes, and methods.
Provide a blueprint for object-oriented implementation.
Include associations like inheritance, composition, and aggregation.
Example: A class diagram for an e-commerce system may depict classes like Product, Order, Customer, and their relationships.
Sequence Diagrams
Illustrate how objects interact in a sequence of events.
Useful for understanding the flow of a specific use case.
Represent objects, messages, and lifelines.
Example A sequence diagram for the "Add to Cart" feature in an online store might detail how the User, Cart, and Inventory classes interact.
Activity Diagrams
Represent the workflow of a system process.
Highlight decision points and actions in a process.
Example An activity diagram for a login feature might show:
User inputting credentials.
System validating credentials.
Login success or failure.
State Diagrams
Capture the state transitions of an object over time.
Useful for systems with complex states (e.g., order states in e-commerce).
Example An order might transition through states like:
Created → Processed → Shipped → Delivered.
Low-Level Design Principles
Low-Level Design relies on several principles to ensure the resulting system is clean, maintainable, and scalable.
SOLID Principles
Single Responsibility− A class should have one and only one reason to change.
Open/Closed− Classes should be open for extension but closed for modification.
Liskov Substitution− Subtypes must be substitutable for their base types.
Interface Segregation− Interfaces should be specific to the client.
Dependency Inversion− High-level modules should not depend on low-level modules.
Design Patterns
Design patterns are reusable solutions to common problems in software design. Examples include−
Creational Patterns− Singleton, Factory.
Structural Patterns− Adapter, Decorator.
Behavioral Patterns− Observer, Strategy.
Dependency Injection
This principle encourages loosely coupled code by injecting dependencies rather than hardcoding them.
Steps to Create a Low-Level Design
Understand Requirements− Analyze use cases and break them into smaller tasks.
Identify Components− Determine the classes, interfaces, and methods needed.
Define Relationships− Establish associations like inheritance and composition.
Design Workflows− Create sequence and activity diagrams for key workflows.
Document Details− Include method signatures, input/output parameters, and pseudocode.
Review and Refine− Ensure the design adheres to principles and patterns.
Example of Low-Level Design
Consider a Library Management System. One feature is "Borrow a Book."
Class Diagram
Classes− User, Book, BorrowTransaction.
Relationships−
User borrows a Book.
BorrowTransaction keeps track of borrow details.

Relationships
User can borrow multiple Books.
A BorrowTransaction records which User borrowed which Book.
Sequence Diagram
User requests to borrow a book.
System checks book availability.
System creates a transaction record.
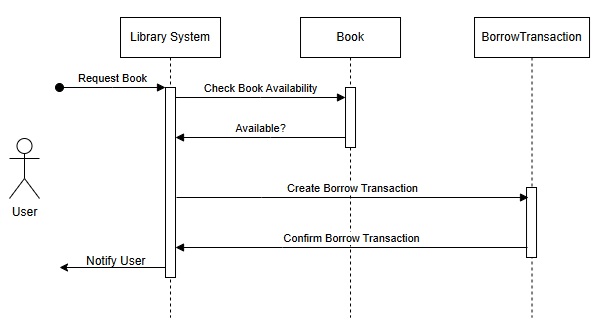
Steps
User requests to borrow a book.
LibrarySystem checks book availability.
If available, LibrarySystem creates a BorrowTransaction.
LibrarySystem confirms the borrowing and notifies the User.
Best Practices in Low-Level Design
Follow Design Principles− Adhere to SOLID principles and use design patterns judiciously.
Document Extensively− Ensure all details are clear for developers to implement.
Ensure Scalability− Design for future growth by anticipating changes.
Minimize Coupling− Reduce dependencies between components to improve maintainability.
Peer Review− Collaborate with teammates to validate the design.
Challenges in Low-Level Design
Over-Engineering− Adding unnecessary complexity can hinder development.
Time Constraints− Detailed LLDs can take time, especially for large systems.
Evolving Requirements− Frequent changes can render designs obsolete.
Skill Dependency− LLD creation requires experienced designers who understand design principles.
Conclusion
Low-Level Design is a critical phase in system design that translates architectural blueprints into actionable plans for development. By focusing on classes, workflows, and design principles, it ensures a robust and maintainable codebase. Although challenging, investing in detailed LLD saves time and resources during development and maintenance, making it an essential skill for system designers and developers.
Difference between Authentication and Authorization in LLD
Introduction
In system design, authentication and authorization are two critical concepts that play a pivotal role in securing systems and controlling access to sensitive resources. Although they are closely related and often implemented together, they serve distinct purposes.
Authentication answers the question, "Who are you?";
Authorization answers the question, "What are you allowed to do?";
This article explores the differences, mechanisms, and best practices for implementing authentication and authorization in system design, highlighting their importance in modern distributed systems.
What is Authentication?
Definition
Authentication is the process of verifying the identity of a user, system, or entity attempting to access a resource. It ensures that only legitimate users are granted access.
Authentication is the act of establishing the same claim as users identify on a computer system. As opposed to identification, authenticity is the process of verifying a person's or thing's identification. Personal identification must be validated, the website's validity must be validated with a digital certificate, the relic must be carbon dated, and the product or document must not be counterfeit.
The process of determining the claimed user is known as authentication. This is the first stage of the security procedure. Completing the authentication procedure in less than or equal to −
The password− The most popular authentication factors are usernames and passwords. When the user provides the correct information, the system validates the ID and authorizes access.
Pin is a one-time use item− Allow just one session or transaction to be accessed.
An app for authentication− Generate a security code that permits access through an external party.
Biometric identification− To gain access to the system, users must give fingerprints and eye scans.
Before providing access, the system may need to validate numerous factors correctly. This multi-factor authentication (MFA) requirement frequently allows for additional protection beyond what passwords alone would give.
Types of Authentication
Password-Based Authentication−
Users provide a username and password to verify their identity.
Examples− Login forms, SSH access.
Biometric Authentication−
Uses biological traits like fingerprints, facial recognition, or retina scans.
Examples− Smartphone fingerprint unlock, airport biometric verification.
Token-Based Authentication−
Involves generating a secure token (e.g., JWT) after successful login.
Tokens are sent with subsequent requests to verify identity.
Multi-Factor Authentication (MFA)−
Combines two or more authentication factors (e.g., password + OTP).
Certificate-Based Authentication−
Uses digital certificates to authenticate users or systems.
Common in enterprise systems and secure APIs.
What is Authorization?
Definition
Authorization is the process of determining what actions or resources a user is permitted to access after they have been authenticated. It enforces policies to control access.
Authorization is the capacity to assign privileges/privileges to a resource, and it pertains to information security in general and computer security, in particular, access control. In a more formal sense, "authorization" refers to the process of creating an access policy. In system security, authorization is the process of giving access to a specified resource or function. This phrase is frequently used interchangeably with access control and client permission.
Permission can allow someone to download specific files from a server or provide particular users administrative access to a program.
Certification is always required for approval in a secure setting. Before the organization administrator gives access to the requested resources, users must first confirm their identification.
Types of Authorization
Role-Based Access Control (RBAC)−
Permissions are assigned based on user roles.
Example− An admin role has more privileges than a regular user.
Attribute-Based Access Control (ABAC)−
Access is granted based on user attributes (e.g., department, location).
Example− Employees in "HR" can access payroll systems.
Policy-Based Access Control (PBAC)−
Centralized policies define access rules, often using external policy engines.
Discretionary Access Control (DAC)−
Resource owners control access.
Example− File permissions on a Linux server.
Mandatory Access Control (MAC)−
Access is strictly controlled by the system, not by resource owners.
Authentication vs Authorization
Authentication and authorization are separate phases in the login process. To correctly implement an IAM solution, you must understand the difference between the two.
Consider a person approaching a closed door to care for a pet while the family is away on vacation. The following items are required for the individual −
Key type authentication was obtained − Like how a door lock system only allows access to users with the proper credentials, it only provides users with the appropriate key.
Authorization in the form of a permit − Once inside, the individual has access to the kitchen and the authority to unlock a cabinet containing pet food. The individual may not have the authorization to enter the bedroom for a bit of wink.
Authentication and authorization are used jointly in this example. You have the authority to enter the pet nanny house (authentication), which grants you access to specific places (authentication).
Key Differences Between Authentication and Authorization
| Sr.No. | Aspect | Authentication | Authorization |
|---|---|---|---|
| 1 | Purpose | Verifies identity. | Determines access rights. |
| 2 | Question Answered | "Who are you?" | "What can you do?" |
| 3 | Process | First step in access control. | Second step after authentication. |
| 4 | Focus | User identity. | User permissions. |
| 5 | Examples | Password login, biometric scan. | Accessing admin dashboard, editing a file. |
| 6 | Dependencies | Independent of authorization. | Dependent on successful authentication. |
Importance of Authentication and Authorization in System Design
Security−
Prevents unauthorized access to sensitive data.
Protects against attacks like credential stuffing or privilege escalation.
Compliance−
Meets regulatory requirements (e.g., GDPR, HIPAA).
Scalability−
Ensures secure access as systems scale to support more users.
User Experience−
Properly implemented authentication and authorization provide seamless and secure user interactions.
Authentication Mechanisms in System Design
Password-Based Authentication
Users provide credentials stored securely (e.g., hashed with bcrypt).
Risks− Susceptible to brute-force attacks, weak passwords.
Token-Based Authentication
After login, a token (e.g., JSON Web Token) is issued to the user.
Tokens are sent with subsequent requests for verification.
Benefits−
Stateless.
Ideal for distributed systems.
Examples− OAuth2, OpenID Connect.
Multi-Factor Authentication (MFA)
Combines−
Knowledge (e.g., password).
Possession (e.g., phone for OTP).
Inherence (e.g., fingerprint).
Significantly enhances security.
Biometric Authentication
Uses unique physical traits.
Benefits− Difficult to forge.
Examples− Apple Face ID, fingerprint scanners.
Authorization Mechanisms in System Design
Role-Based Access Control (RBAC)
Assigns permissions based on roles.
Example−
Admin− Full access.
Editor− Create and edit.
Viewer− Read-only.
Attribute-Based Access Control (ABAC)
Uses dynamic attributes to determine access.
Example− A manager in "Sales" can access sales reports for their region.
Policy-Based Access Control (PBAC)
Centralized access policies stored in external engines.
Example− AWS IAM policies.
Best Practices for Designing Authentication and Authorization
For Authentication
Use Secure Password Storage− Hash passwords using algorithms like bcrypt or Argon2.
Implement MFA− Add an additional layer of security.
Token Expiry− Set expiration times for session tokens.
For Authorization
Follow the Principle of Least Privilege− Grant only the necessary permissions.
Audit Permissions Regularly− Remove unused roles or excessive privileges.
Externalize Authorization Logic− Use dedicated policy engines for scalability.
Challenges in Implementing Authentication and Authorization
Scalability− Handling millions of authentication requests in distributed systems.
Security Risks− Protecting against attacks like session hijacking or privilege escalation.
User Experience− Balancing security with ease of use.
Integration Complexity− Integrating authentication and authorization mechanisms across services.
Conclusion
Authentication and authorization are foundational components of system security. While authentication ensures only legitimate users access the system, authorization determines their privileges. Together, they safeguard sensitive resources and ensure seamless operation.
Understanding the differences, mechanisms, and best practices for implementing these processes is crucial for designing secure, scalable, and user-friendly systems. As systems grow increasingly distributed and complex, robust authentication and authorization mechanisms become indispensable.
System Design - Performance Optimization
Introduction
System design is a critical discipline that underpins the development of scalable, efficient,and reliable software systems. Performance optimization plays a central role in this domain,ensuring that systems can meet growing demands without sacrificing responsiveness or stability.
In today’s fast-paced world, where users expect near-instantaneous responses and systems operate across global networks, designing for performance is no longer optional. This article explores the strategies, tools, and trade-offs involved in system performance optimization.
From addressing bottlenecks to adopting emerging technologies, we aim to provide actionable insights for developers, architects, and organizations striving for excellence in system design.
Understanding System Performance
System performance is a measure of how effectively a system meets its goals under expected conditions. Key aspects include−
Core Performance Metrics
Latency− Time to process a single request. For example, in high-frequency trading systems, latency can make or break success.
Throughput− The number of requests processed per second, critical for APIs and backend services.
Error Rate− High error rates indicate system instability, often caused by resource constraints or coding bugs.
Capacity− Maximum load a system can handle before degradation.
Example− A global e-commerce platform might track checkout latency and throughput during peak events like Black Friday to ensure smooth customer experiences.
Why Performance Matters
User Satisfaction− Studies show users abandon websites if pages take more than 3 seconds to load.
Competitive Edge− Faster systems attract and retain customers.
Cost Efficiency− Optimized systems reduce waste in compute resources and operational costs.
Performance Bottlenecks
Identifying Bottlenecks
Pinpointing bottlenecks requires an understanding of system behavior under various workloads. Profiling tools like Flamegraphs, New Relic, and Datadog visualize hotspots in system performance, such as−
Slow API Calls− Calls dependent on third-party integrations often introduce delays.
Database Locks− High contention during complex queries.
Memory Leaks− Gradual degradation due to improper resource management.
Example− A social media platform reduced photo upload latency by profiling disk I/O operations and switching to an SSD-based storage solution.
The Chain Reaction of Bottlenecks
A slow database query might cascade into high CPU usage on the application server, increased thread contention, and delayed responses. Understanding these interdependencies is crucial for targeted optimization.
Optimization Strategies
Caching
Content Delivery Networks (CDNs)− Deliver static assets (e.g., images, videos) from geographically distributed servers.
Tiered Caching− Combining browser, edge, and database caches for maximum efficiency.
Cache Invalidation− Strategies to avoid serving stale data, such as time-based expiration and versioned keys.
Database Optimization
Materialized Views− Precomputed results for commonly accessed queries.
Partitioning− Splitting large tables into smaller, more manageable chunks.
Database Connection Pools− Preventing bottlenecks by limiting concurrent database connections.
Resource Scaling
Auto-scaling in Cloud Environments− AWS Auto Scaling or Kubernetes Horizontal.
Pod Autoscaler dynamically adjusts resources based on workload.
Tools and Techniques
Monitoring Tools
Prometheus and Grafana− For real-time metrics and alerts.
Elasticsearch, Logstash, Kibana (ELK)− Aggregates logs to provide actionable insights.
Jaeger− Distributed tracing for microservices.
Testing Techniques
Stress Testing− Identifying breaking points by simulating extreme conditions.
Soak Testing− Verifying long-term system stability under sustained loads.
Chaos Engineering
Simulating failures to test system resilience. For example, Netflix's Chaos Monkey randomly shuts down instances to ensure their systems handle outages gracefully.
Trade-offs and Limitations
Performance vs. Reliability
Aggressive caching can speed up responses but may lead to stale data, particularly in systems with high data churn.
Performance vs. Development Speed
Adding complexity, such as partitioning or distributed computing, may slow development and debugging cycles.
Over-Optimization Risks
Spending excessive resources on optimizing rarely-used features can lead to wasted effort and increased maintenance overhead.
Security in Performance Optimization
While performance is crucial, it must not come at the cost of security. Optimization strategies must ensure−
Secure Caching
Avoid exposing sensitive information via poorly configured caches. Use cache encryption for sensitive data.
Rate Limiting and Throttling
Rate-limiting APIs prevent abuse while optimizing server load.
Secure Resource Scaling
Ensure scaling policies do not inadvertently increase attack surfaces (e.g., unprotected additional server instances).
Cultural and Organizational Considerations
Cross-functional Collaboration
Performance optimization requires collaboration between development, operations, and business teams. A DevOps culture fosters−
Rapid Feedback Loops− Identifying and resolving performance issues quickly.
Shared Responsibility− Developers and operations teams work together to optimize production systems.
Measuring Success
Key performance indicators (KPIs) should align with business goals, such as conversion rates or customer retention.
Performance-First Mindset
Embedding performance concerns early in the software development lifecycle (SDLC) minimizes technical debt. Teams can adopt practices like performance budgeting and code reviews with a focus on efficiency.
Case Studies and Real-World Examples
High-Performance Streaming
A video streaming service like Netflix optimized its delivery network by using Open Connect Appliances, reducing latency by 40%.
E-commerce Platform Scaling
An online retailer implemented database sharding during holiday seasons, enabling seamless transactions for over 10 million users concurrently.
SaaS Microservices Optimization
A SaaS company restructured its monolithic architecture into microservices, using Kubernetes for auto-scaling, which improved deployment times and performance metrics by 50%.
Serverless Optimization
A startup adopted serverless computing to process millions of events daily without maintaining infrastructure, leveraging AWS Lambda’s pay-as-you-go model for cost and performance benefits.
Future Trends in Performance Optimization
AI-driven Optimization
AI tools like TensorFlow Extended (TFX) analyze performance logs to suggest improvements automatically.
Edge Computing
Bringing compute closer to users significantly reduces latency for IoT and real-time applications.
Serverless Architectures
These architectures eliminate the need to manage infrastructure while scaling automatically based on demand.
Quantum Computing
Though in its infancy, quantum computing could revolutionize performance for specific tasks like cryptography and complex simulations.
Conclusion
Performance optimization in system design is a balancing act, requiring careful analysis, strategic planning, and the judicious use of tools. While the pursuit of performance offers competitive advantages, organizations must navigate trade-offs between cost, complexity, and security.
By adopting a performance-first mindset and staying abreast of emerging trends, engineers can build systems that not only meet current demands but also anticipate future challenges. Optimization is not a one-time task but a continuous process that evolves alongside user needs and technological advancements.
System Design - Containerization Architecture
Introduction
In modern software development, containerization has emerged as a revolutionary architecture that enables applications to run consistently across environments. Containerization encapsulates application code, dependencies, libraries, and runtime into isolated containers, ensuring portability, scalability, and flexibility.
Traditional approaches like virtual machines (VMs) faced inefficiencies such as high resource consumption and slow boot times. Containers solve these issues with lightweight, fast, and efficient deployments.
This article explores containerization architecture, its key components, advantages, challenges, tools like Docker and Kubernetes, and real-world case studies. Finally, we will discuss future trends that are redefining containerization in modern system design.
What is Containerization?
Definition
Containerization is a method of packaging applications and their dependencies into isolated environments called containers. Each container runs independently and shares the host OS kernel, making it lightweight compared to virtual machines.
Containers vs. Virtual Machines (VMs)
| Sr.No. | Feature | Containers | Virtual Machines |
|---|---|---|---|
| 1 | Overhead | Lightweight, shares kernel | Heavy, includes OS |
| 2 | Boot Time | Milliseconds | Minutes |
| 3 | Resource Utilization | Efficient | Resource-intensive |
| 4 | Portability | High | Moderate |
Why Containers?
Portability− Works across local, testing, and production environments.
Isolation− Ensures applications do not interfere with each other.
Scalability− Easy to scale horizontally using orchestration tools.
Faster Deployments− Lightweight containers start and stop quickly.
Example− A microservices architecture uses containers to encapsulate each service (e.g., user authentication, payments, inventory).
Core Components of Containerization Architecture
Containers− Self-contained execution environments with code, runtime, dependencies, and configurations.
Images− Immutable blueprints for containers. Created using Dockerfiles.
Container Engine− The software that creates, runs, and manages containers. Example: Docker Engine.
Orchestration Tools− Tools like Kubernetes, Docker Swarm, and Amazon ECS manage the deployment, scaling, and operations of containerized applications.
Container Registries− Centralized repositories to store container images. Example: Docker Hub, Google Container Registry (GCR), and Amazon Elastic Container Registry (ECR).
Advantages of Containerization Architecture
Portability Across Environments− Containers abstract dependencies, ensuring code runs the same way locally, in staging, and in production.
Resource Efficiency− Containers share the host OS kernel, consuming fewer resources than VMs.
Faster Development and Deployment− Containers integrate seamlessly into CI/CD pipelines for faster releases.
Scalability− Containers scale horizontally with orchestration tools. Kubernetes can spin up or remove containers based on load.
Improved Fault Isolation− Containers are isolated; failures in one container do not affect others.
Consistency− Development teams benefit from a consistent runtime environment.
Containerization Tools and Platforms
Docker
Docker is the leading containerization platform for building, packaging, and running containers.
Dockerfile− A text file with instructions to build a Docker image.
Docker Compose− Manages multi-container applications locally.
Docker Hub− Public registry for container images.
Example Dockerfile
FROM node:14 WORKDIR /app COPY . /app RUN npm install CMD ["node", "server.js"]
Kubernetes
Kubernetes (K8s) is the most popular container orchestration tool. It automates−
Container deployment
Scaling based on resource usage
Load balancing
Self-healing by restarting failed containers
Key Components of Kubernetes
Pods− The smallest deployable unit in Kubernetes (a single container or group of containers).
Services− Abstract networking to expose applications.
Deployments− Declarative management for containerized applications.
Nodes− Worker machines where containers run.
Docker Swarm
A native clustering tool in Docker for simpler orchestration compared to Kubernetes.
Amazon ECS and Fargate
AWS's managed container services for deploying and managing containers.
OpenShift
A Kubernetes-based platform by Red Hat with enterprise-grade features.
Container Orchestration
Container orchestration automates the deployment, scaling, and management of containerized applications.
Why Orchestration?
Scaling− Automatically handles load spikes.
Health Management− Detects and restarts failed containers.
Load Balancing− Routes traffic to the most available containers.
Example− A Kubernetes cluster running a microservices application scales up services like "payments" during high load and scales them down during idle times.
Comparison of Orchestration Tools
| Sr.No. | Feature | Kubernetes | Docker Swarm | Amazon ECS |
|---|---|---|---|---|
| 1 | Scalability | High | Moderate | High |
| 2 | Ease of Use | Steep Learning Curve | Easy | Managed by AWS |
| 3 | Community Support | Excellent | Moderate | Strong |
Challenges of Containerization
Learning Curve− Tools like Kubernetes can be complex to adopt.
Resource Management− Containers still consume resources; improper configuration can lead to inefficiencies.
Security−
Containers share the host kernel, which can be a risk if one container is compromised.
Solution− Use security tools like Seccomp and container scanning tools (e.g., Trivy).
Storage Persistence− Stateless containers struggle with persistent data storage. Tools like Persistent Volumes in Kubernetes help mitigate this.
Monitoring− Managing logs and metrics for distributed containerized applications is challenging. Tools like Prometheus, ELK, and Grafana are essential.
Use Cases and Case Studies
Microservices Architecture− Containers isolate individual services like authentication, payments, and notifications.
CI/CD Pipelines− Containers ensure consistency throughout development, testing, and production environments.
Cloud-Native Applications− Containers power modern, cloud-native architectures. Example: Netflix runs its video streaming services using containers on AWS.
Case Study: Spotify− Spotify uses containers and Kubernetes to scale its music streaming services for millions of users.
Security in Containerization
Image Scanning− Detect vulnerabilities in container images using tools like Clair and Trivy.
Runtime Security− Implement policies with tools like Falco for container runtime monitoring.
Least Privilege− Containers should run with minimal permissions.
Isolation Mechanisms− Leverage namespaces, cgroups, and security modules (e.g., AppArmor).
Future Trends in Containerization
Edge Computing− Containers bring lightweight, distributed compute power closer to users.
Serverless Containers− Tools like AWS Fargate and Google Cloud Run integrate serverless and container technologies.
AI/ML Workloads− Containers enable distributed training and inference in machine learning pipelines.
Service Meshes− Tools like Istio and Linkerd manage container communication in microservices architectures.
Conclusion
Containerization has transformed system design by enabling consistency, portability, and scalability. Tools like Docker, Kubernetes, and cloud platforms empower teams to build cloud-native, microservices-driven applications.
Despite challenges like security and persistent storage, containerization is rapidly advancing with innovations like serverless architectures and edge computing. Organizations adopting containerization gain a competitive advantage through faster development cycles and more reliable systems.
As technology evolves, containerization will remain at the heart of modern application development, enabling the next generation of distributed systems.
System Design - Modularity and Interfaces
Introduction
Modularity and interfaces are core principles of system design that enable the development of scalable, maintainable, and reusable systems.
What is Modularity?
Modularity involves dividing a system into smaller, independent components called modules. Each module performs a specific function and interacts with other modules through defined interfaces.
What are Interfaces?
An interface defines how different system components communicate with each other. It abstracts the internal workings of a module, exposing only what is necessary for integration. In this article, we explore how modularity and interfaces improve system architecture, enhance maintainability, and support scalability in modern applications.
Principles of Modularity in System Design
Separation of Concerns
Each module should address a specific functionality, reducing overlap and dependency.
Example− In an e-commerce system, separate modules handle user authentication, product catalog, and payment processing.
High Cohesion
Modules should have closely related functionality to ensure a well-defined purpose.
Low Coupling
Modules should minimize dependencies on each other. This makes it easier to modify one module without affecting others.
Encapsulation
Encapsulation hides a module’s internal implementation, exposing only necessary details via interfaces.
Benefits of Modularity
Scalability− Modular systems scale by adding or replicating specific components.
Reusability− Modules can be reused across projects or within the same system.
Maintainability− Well-structured modular systems are easier to debug, test, and update.
Parallel Development− Teams can work on different modules independently.
Resilience− A failure in one module is less likely to disrupt the entire system.
Designing Modular Systems
Identify Modules
Break the system into logical components. For example, a social media platform could have modules for user profiles, posts, and notifications.
Define Responsibilities
Assign each module a clear set of tasks to avoid overlapping functionalities.
Design Interfaces
Create APIs, protocols, or other interfaces to enable communication between modules.
Use Dependency Injection
Dependency injection allows modules to depend on abstractions rather than concrete implementations, increasing flexibility.
Testing Modular Systems
Each module should be independently testable to ensure functionality and reliability.
Understanding Interfaces in System Design
Interfaces are the glue that connects modular components. They define the contract between two entities, specifying how they communicate and interact.
Key Properties of Interfaces
Clarity− Interfaces should be simple and easy to understand.
Stability− Interfaces should not change frequently to avoid breaking dependent systems.
Versioning− Interfaces should support backward compatibility.
Example− A payment module exposes an interface for processing payments. It hides internal details like payment gateway integration.
Types of Interfaces
Programmatic Interfaces−
APIs (e.g., RESTful APIs, GraphQL).
Example− A weather service API provides weather data for external applications.
User Interfaces−
Interfaces designed for human interaction (e.g., graphical or command-line interfaces).
Hardware Interfaces−
Define communication between hardware components (e.g., USB, HDMI).
Database Interfaces−
Interfaces for querying and managing data in databases (e.g., SQL, ORMs).
Communication Interfaces−
Protocols for inter-module communication (e.g., gRPC, Message Queues).
The Role of APIs in Modular System Design
APIs (Application Programming Interfaces) play a vital role in enabling modularity by standardizing how modules interact.
RESTful APIs
Lightweight and widely used for web applications.
Example− A microservice exposes a RESTful API to provide user account details.
GraphQL
A query language for APIs allowing clients to specify the exact data they need.
gRPC
A high-performance communication protocol often used in distributed systems.
Examples of Modular Systems
Microservices Architecture
Each service represents a module, communicating via APIs.
Example− An e-commerce system’s cart service interacts with inventory and payment services.
Modular Monoliths
A single application organized into independent modules.
Example− A healthcare application has modules for patient records, billing, and reporting.
Plug-In Architectures
Allows extending system functionality without altering the core.
Example− Content Management Systems (CMS) like WordPress use plug-ins for added features.
Challenges of Modularity and Interface Design
Complexity in Interface Design− Poorly designed interfaces can cause communication issues.
Overhead of Managing Dependencies− Excessive modularity may introduce dependency management challenges.
Versioning Issues− Interface changes can break compatibility.
Performance Overhead− Inter-module communication can add latency.
Best Practices for Modularity and Interfaces
Start Small− Begin with a few well-defined modules and evolve as needed.
Focus on Interface Design− Clearly define what each module exposes and consumes.
Adopt Standard Protocols− Use established protocols like REST, gRPC, or AMQP for communication.
Document Interfaces− Maintain comprehensive documentation for all interfaces.
Automated Testing− Use integration tests to validate inter-module communication.
Modularity in Microservices Architecture
How Microservices Use Modularity
Each microservice represents a modular unit with its own database, logic, and API.
Advantages
Independent Deployment− Teams can deploy services independently.
Resilience− Failures are isolated to individual services.
Scalability− Services scale independently.
Example− Uber uses microservices for managing ride requests, payments, and notifications.
Future Trends in Modular System Design
AI-Driven Modular Design− Tools powered by AI assist in identifying and designing optimal modules.
Serverless Architectures− Serverless computing aligns well with modularity by abstracting infrastructure.
Event-Driven Architectures− Enables modules to react to system events asynchronously.
Service Meshes− Tools like Istio and Linkerd streamline inter-service communication in modular systems.
Conclusion
Modularity and interfaces form the backbone of modern system design, enabling scalability, maintainability, and flexibility. Whether through microservices, modular monoliths, or plug-in architectures, breaking down systems into smaller, reusable components is essential for managing complexity in software development.
By leveraging best practices, robust interfaces, and emerging trends, teams can build systems that are not only efficient but also adaptable to changing business needs. As technology evolves, modularity and interfaces will remain fundamental principles of successful system architecture.
CI/CD Pipelines: Automating Software Development and Delivery
Introduction
Modern software development relies on speed, quality, and reliability. CI/CD (Continuous Integration/Continuous Delivery/Deployment) enables teams to deliver software faster and more efficiently through automation.
CI/CD is a DevOps practice that automates−
Integration− Code merges and builds.
Delivery− Packaging and testing software for production.
Deployment− Automated release of software to production environments.
With CI/CD pipelines, teams adopt iterative development, ensuring that every change is tested, integrated, and deployed seamlessly.
Understanding Continuous Integration (CI)
Definition
Continuous Integration (CI) is a practice where developers frequently merge their code into a shared repository, triggering automated builds and tests.
Goals of CI
Early Detection of Bugs− Frequent integrations catch issues early.
Improved Collaboration− Developers integrate and resolve conflicts daily.
Faster Development Cycles− Code integration is automated.
Key Processes in CI
Code Commit− Developers push changes to a version control system like Git.
Build Automation− Tools like Maven or Gradle build the software.
Automated Testing− Unit tests, integration tests, and static code analysis run.
Code Quality Checks− Tools like SonarQube analyze code quality.
Example− A team uses Jenkins for CI. Each Git commit triggers a build, runs unit tests, and generates reports for developers.
Understanding Continuous Delivery and Continuous Deployment
Continuous Delivery (CD)
Continuous Delivery ensures that the software is always in a deployable state. It automates the packaging and testing of software, requiring manual approval before deployment.
Continuous Deployment
In Continuous Deployment, every successful change is automatically deployed to production without manual intervention.
Differences
| Sr.No. | Feature | Continous Delivery | Continous Deployment |
|---|---|---|---|
| 1 | Deployment | Manual approval needed | Fully automated |
| 2 | Use Case | Enterprise software, compliance | SaaS, startups, fast-moving teams |
Benefits of CI/CD Pipelines
Faster Releases− Teams can release code changes frequently (multiple times a day).
Improved Code Quality− Automated testing catches errors early.
Reduced Risks− Small, incremental changes are easier to test and deploy.
Consistent Environments− CI/CD pipelines ensure consistency across development, staging, and production.
Developer Productivity− Automating builds and testing reduces manual effort.
Example− Facebook deploys code thousands of times a day using CI/CD, reducing deployment risks.
Key Components of CI/CD Pipelines
Version Control System− Example: Git, GitHub, GitLab, Bitbucket.
Build Tools− Example: Maven, Gradle, or NPM (for JavaScript projects).
Testing Frameworks−
Unit Tests− JUnit, PyTest, Mocha.
Integration Tests− Selenium, Postman.
CI/CD Orchestration Tools− Example: Jenkins, GitHub Actions, GitLab CI/CD, CircleCI.
Artifact Repository− Example: JFrog Artifactory, Nexus Repository.
Deployment Tools− Example: Kubernetes, Docker, Terraform, AWS CodeDeploy.
Monitoring and Logging− Tools: Prometheus, ELK Stack, Grafana.
Popular CI/CD Tools and Platforms
| Sr.No. | Tools | Features | Use Case |
|---|---|---|---|
| 1 | Jenkins | Open-source, customizable, large plugin ecosystem. | Versatile for enterprises. |
| 2 | GitHub Actions | Native CI/CD for GitHub, integrates with repositories. | Seamless for GitHub users. |
| 3 | GitLab CI/CD | Built-in CI/CD, powerful pipelines. | Integrated GitOps workflows. |
| 4 | CircleCI | Fast builds, supports Docker and Kubernetes. | Startups and cloud-native projects. |
| 5 | AWS CodePipeline | Fully managed CI/CD by AWS. | Cloud-native apps on AWS. |
Example Jenkins Pipeline
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'mvn clean package'
}
}
stage('Test') {
steps {
sh 'mvn test'
}
}
stage('Deploy') {
steps {
sh 'scp target/app.jar user@server:/deployments/'
}
}
}
}
Designing a CI/CD Pipeline
Define Stages−
Build− Compile code and resolve dependencies.
Test− Run unit tests, integration tests, and security checks.
Package− Package application into artifacts or containers.
Deploy− Deploy to staging or production.
Choose Tools− Select tools like Jenkins, GitLab, or AWS CodePipeline.
Automate Workflows−
Trigger pipelines on code commits.
Use YAML files for configuration (e.g., .gitlab-ci.yml, Jenkinsfile).
Set Up Monitoring− Add logging and error notifications.
CI/CD Pipeline Best Practices
Commit Code Frequently− Encourage small, frequent code commits.
Run Automated Tests− Include unit, integration, and performance tests.
Parallelize Workloads− Run builds and tests in parallel to save time.
Fail Fast− Stop the pipeline immediately if a stage fails.
Environment Consistency− Use containers (Docker) to standardize environments.
Monitor Pipeline Health− Visualize pipeline status and logs with tools like Grafana.
Challenges in CI/CD Implementation
Tool Complexity− Learning tools like Kubernetes and Jenkins can be challenging.
Flaky Tests− Intermittent test failures delay pipelines.
Legacy Systems− Integrating CI/CD with older codebases.
Security Risks− Poorly configured pipelines can expose systems to attacks.
Security in CI/CD Pipelines (DevSecOps)
Static Code Analysis− Tools like SonarQube detect vulnerabilities.
Secrets Management− Use HashiCorp Vault to store credentials securely.
Container Scanning− Scan Docker images for vulnerabilities (e.g., Trivy, Clair).
Security Gates− Block deployments if vulnerabilities exceed thresholds.
CI/CD for Microservices
Each microservice has its own CI/CD pipeline.
Containers and Kubernetes manage deployments.
Use service meshes like Istio for traffic management.
Example− Netflix uses CI/CD pipelines for its 1,000+ microservices to automate builds, testing, and deployments.
Case Studies of CI/CD in Action
Amazon− Deploys code every 11.7 seconds using CI/CD.
Netflix− Automates deployments to its cloud infrastructure with Spinnaker.
Airbnb− Uses GitHub Actions and Kubernetes to deploy new features.
Future Trends in CI/CD
AI/ML in CI/CD− Predicting test failures and automating optimizations.
GitOps− Using Git as a single source of truth for deployments.
Serverless CI/CD− Simplifying pipelines with serverless platforms.
Security-First CI/CD− Integrating security throughout the pipeline.
Conclusion
CI/CD pipelines are the backbone of modern software delivery, enabling teams to release faster, reduce errors, and improve collaboration. By adopting CI/CD tools, best practices, and automation, organizations can achieve continuous innovation and meet customer expectations effectively.
System Design - Data Partitioning Techniques
Introduction
Data partitioning, also known as sharding, involves dividing a large dataset into smaller, manageable segments (partitions) to optimize storage, improve query performance, and enhance scalability. Partitioning is particularly useful in distributed systems and large-scale applications.
Why Partition Data?
Scalability− Distributed storage across multiple servers.
Performance− Faster queries and reduced response time.
Cost Optimization− Efficient resource utilization.
Example− A global e-commerce platform might partition user data by region to improve latency for users in different parts of the world.
Benefits of Data Partitioning
Scalability
Partitioning allows data to scale horizontally by adding more nodes to the system.
Improved Performance
Queries operate on smaller datasets, reducing search and processing time.
High Availability
Data replication across partitions ensures minimal downtime during node failures.
Cost Efficiency
By partitioning less-accessed data to cheaper storage solutions, organizations can optimize costs.
Challenges in Data Partitioning
Data Skew
Uneven data distribution among partitions can lead to hot spots and degraded performance.
Complexity in Querying
Partitioning may require rewriting queries to handle distributed data.
Rebalancing Overhead
When new partitions are added, rebalancing data across partitions is resource-intensive.
Cross-Partition Queries
Queries spanning multiple partitions can increase latency.
Example− Inconsistent hash functions might cause some partitions to store disproportionately large datasets.
Horizontal Partitioning (Sharding)
Horizontal partitioning involves splitting a table into rows and storing subsets of rows in different partitions.
How It Works
Each partition contains rows that meet specific criteria.
Example− A user table might be divided by geographical regions−
Partition 1− Users from North America.
Partition 2− Users from Europe.
Advantages
Supports horizontal scaling.
Easier to manage growing datasets.
Disadvantages
Rebalancing data when partitions grow can be costly.
Diagram Idea− Show a table divided into multiple partitions based on region.
Vertical Partitioning
Vertical partitioning splits a table into columns and stores subsets of columns in separate partitions.
How It Works
Each partition contains a specific subset of columns.
Example
Partition 1− User ID, Name, Email.
Partition 2− User ID, Preferences, Settings.
Advantages
Improves query performance for specific fields.
Reduces I/O for queries targeting selected columns.
Disadvantages
Joins across partitions can be expensive.
Range-Based Partitioning
Range partitioning involves dividing data into partitions based on a range of values.
How It Works
Define ranges for partition keys. Data is stored in partitions corresponding to the range.
Example
Partition 1− Orders with OrderDate from Jan–Jun.
Partition 2− Orders with OrderDate from Jul–Dec.
Advantages
Intuitive and easy to implement.
Efficient for range queries.
Disadvantages
Can result in data skew if ranges are uneven.
Hash-Based Partitioning
Hash partitioning uses a hash function to determine the partition for each data item.
How It Works
A hash function is applied to a partition key (e.g., UserID) to distribute data evenly across partitions.
Example
Partition 1− hash(UserID) % 3 == 0
Partition 2− hash(UserID) % 3 == 1
Advantages
Ensures even distribution.
Prevents data skew.
Disadvantages
Rebalancing requires rehashing, which is resource-intensive.
Key-Based Partitioning
Key-based partitioning assigns data to partitions based on specific keys.
How It Works
Data is assigned to a partition using predefined keys.
Example
Partition 1− Users with IDs 1–1000.
Partition 2− Users with IDs 1001–2000.
Advantages
Simple and predictable.
Disadvantages
Requires manual rebalancing when partitions are added.
Directory-Based Partitioning
Directory-based partitioning uses a lookup table to determine the partition for each data item.
How It Works
The lookup table maps keys to specific partitions.
Example
| Sr.No. | Key | Partition |
|---|---|---|
| 1 | User1 | Partition1 |
| 2 | User2 | Partition2 |
Advantages
Flexible and adaptable to changes.
Disadvantages
Requires maintaining the lookup table.
Dynamic Partitioning Techniques
Dynamic partitioning adjusts partitions automatically based on load or data changes.
Techniques
Auto-Sharding− Databases like MongoDB dynamically create shards.
Time-Based Partitioning− Create partitions based on time intervals.
Advantages
Reduces manual intervention.
Adapts to changing workloads.
Real-World Use Cases
E-Commerce Platforms− Partition user data by region to reduce query latency.
Social Media− Shard posts by UserID for balanced distribution.
IoT Systems− Use time-based partitioning for sensor data.
Conclusion and Future Trends
Data partitioning is a cornerstone of scalable system design, enabling distributed systems to handle growing datasets efficiently.
Future Trends
AI-Driven Partitioning− Automatically optimize partitions based on usage patterns.
Serverless Partitioning− Integration with serverless architectures for elastic scalability.
As data grows exponentially, mastering partitioning techniques is essential for building resilient and high-performing systems.
System Design - Essential Security Measures
Introduction to Security in System Design
Security in system design ensures the protection of data, resources, and operations from unauthorized access and malicious attacks. It is a critical aspect of modern application development, where threats continue to evolve.
Why Security Matters?
Protect User Data− Safeguard sensitive information like personal details and financial records.
Ensure Business Continuity− Prevent downtime from security breaches.
Maintain Trust− A secure system builds user confidence.
Example− Data breaches, like those affecting social media platforms, highlight the importance of robust security measures.
Principles of Secure System Design
Defense in Depth
Employ multiple layers of security to protect systems.
Example− Firewalls, encryption, and user authentication.
Least Privilege
Grant users and services the minimum permissions needed to perform their tasks.
Fail Securely
Design systems to fail in a way that doesn’t expose vulnerabilities.
Regular Updates
Ensure that all software components are patched against known vulnerabilities.
Authentication Mechanisms
Authentication verifies the identity of users or systems.
Password-Based Authentication
Enforce strong password policies (minimum length, complexity, expiration).
Multi-Factor Authentication (MFA)
Combine at least two factors−
Something you know (password).
Something you have (OTP).
Biometric Authentication
Use fingerprints, facial recognition, or voice authentication.
Example Code: Spring Security Password Authentication
@Bean
public UserDetailsService userDetailsService() {
return new InMemoryUserDetailsManager(
User.withDefaultPasswordEncoder()
.username("user")
.password("password")
.roles("USER")
.build()
);
}
Authorization and Access Control
Role-Based Access Control (RBAC)
Assign roles to users and restrict access to resources based on roles.
Attribute-Based Access Control (ABAC)
Access decisions based on attributes like time, location, or device.
Zero Trust Architecture
Verify every access request, regardless of origin.
Example− An admin role can access /admin/* endpoints, while a user role is restricted to /user/*.
Data Encryption
Encryption protects data in transit and at rest by converting it into an unreadable format.
Symmetric Encryption
Single key for encryption and decryption.
Example− AES (Advanced Encryption Standard).
Asymmetric Encryption
Public and private key pairs.
Example− RSA for secure key exchanges.
Hashing
One-way encryption for storing sensitive data like passwords.
Example− SHA-256.
Code Snippet: Encrypting Data with AES in Java
Cipher cipher = Cipher.getInstance("AES");
SecretKey key = new SecretKeySpec("MySecretKey12345".getBytes(), "AES");
cipher.init(Cipher.ENCRYPT_MODE, key);
byte[] encrypted = cipher.doFinal("Sensitive Data".getBytes());
Secure APIs
APIs are critical communication channels between systems and must be secured.
Use HTTPS
Encrypt API communications using TLS.
API Authentication
Use OAuth 2.0 or API keys to authenticate API requests.
Input Validation
Prevent injection attacks by validating API inputs.
Example− Implement rate limiting to protect APIs from denial-of-service (DoS) attacks.
Network Security
Network security ensures that the infrastructure connecting systems remains secure.
Firewalls
Block unauthorized traffic.
Example− Web Application Firewalls (WAF) protect against common web threats.
VPNs
Securely connect users to internal systems.
Segmentation
Divide networks into segments to limit the spread of attacks.
Logging and Monitoring for Security
Logging and monitoring help detect suspicious activities and respond to threats.
Log Critical Events
Log user logins, failed authentication attempts, and resource access.
Use Monitoring Tools
Tools like Splunk, ELK Stack, and Prometheus help monitor systems in real time.
Alerting
Set up alerts for unusual activities like high login failure rates.
Example− Configure Spring Boot to log user activity with an AuditEventRepository.
Security Testing and Vulnerability Management
Penetration Testing
Simulate attacks to identify vulnerabilities.
Static Code Analysis
Analyze source code for security flaws.
Dependency Scanning
Identify vulnerabilities in third-party libraries.
Tools− Snyk, Dependabot.
Example− Automate vulnerability scanning in CI/CD pipelines.
Incident Response and Recovery
Incident Response Plan
Prepare a plan to handle security breaches, including−
Identifying the breach.
Containing the attack.
Recovering systems.
Backup and Recovery
Regularly back up critical data and test recovery procedures.
Post-Incident Analysis
Review incidents to identify root causes and prevent recurrence.
Compliance and Legal Considerations
Compliance Standards
GDPR (General Data Protection Regulation).
HIPAA (Health Insurance Portability and Accountability Act).
Data Protection
Ensure user data is handled securely and in compliance with regulations.
Audits
Regular audits ensure adherence to security policies.
Example− A financial service must comply with PCI DSS for secure payment processing.
Future Trends in System Security
AI-Driven Security
Machine learning models detect threats in real time.
Zero Trust Evolution
Adoption of Zero Trust for complete end-to-end security.
Quantum-Resistant Encryption
Prepare for future quantum-computing threats.
Decentralized Security
Blockchain-based systems for immutable data verification.
Conclusion
Secure system design is a fundamental requirement for modern applications. By adopting a layered approach, implementing best practices, and staying updated with evolving threats, organizations can protect their systems and user data. Future advancements in security technologies will further empower developers to build resilient, trustworthy systems.
Input / Output & Forms Design
Input Design
In an information system, input is the raw data that is processed to produce output. During the input design, the developers must consider the input devices such as PC, MICR, OMR, etc.
Therefore, the quality of system input determines the quality of system output. Welldesigned input forms and screens have following properties −
It should serve specific purpose effectively such as storing, recording, and retrieving the information.
It ensures proper completion with accuracy.
It should be easy to fill and straightforward.
It should focus on user’s attention, consistency, and simplicity.
All these objectives are obtained using the knowledge of basic design principles regarding −
What are the inputs needed for the system?
How end users respond to different elements of forms and screens.
Objectives for Input Design
The objectives of input design are −
To design data entry and input procedures
To reduce input volume
To design source documents for data capture or devise other data capture methods
To design input data records, data entry screens, user interface screens, etc.
To use validation checks and develop effective input controls.
Data Input Methods
It is important to design appropriate data input methods to prevent errors while entering data. These methods depend on whether the data is entered by customers in forms manually and later entered by data entry operators, or data is directly entered by users on the PCs.
A system should prevent user from making mistakes by −
- Clear form design by leaving enough space for writing legibly.
- Clear instructions to fill form.
- Clear form design.
- Reducing key strokes.
- Immediate error feedback.
Some of the popular data input methods are −
- Batch input method (Offline data input method)
- Online data input method
- Computer readable forms
- Interactive data input
Input Integrity Controls
Input integrity controls include a number of methods to eliminate common input errors by end-users. They also include checks on the value of individual fields; both for format and the completeness of all inputs.
Audit trails for data entry and other system operations are created using transaction logs which gives a record of all changes introduced in the database to provide security and means of recovery in case of any failure.
Output Design
The design of output is the most important task of any system. During output design, developers identify the type of outputs needed, and consider the necessary output controls and prototype report layouts.
Objectives of Output Design
The objectives of input design are −
To develop output design that serves the intended purpose and eliminates the production of unwanted output.
To develop the output design that meets the end users requirements.
To deliver the appropriate quantity of output.
To form the output in appropriate format and direct it to the right person.
To make the output available on time for making good decisions.
Let us now go through various types of outputs −
External Outputs
Manufacturers create and design external outputs for printers. External outputs enable the system to leave the trigger actions on the part of their recipients or confirm actions to their recipients.
Some of the external outputs are designed as turnaround outputs, which are implemented as a form and re-enter the system as an input.
Internal outputs
Internal outputs are present inside the system, and used by end-users and managers. They support the management in decision making and reporting.
There are three types of reports produced by management information −
Detailed Reports − They contain present information which has almost no filtering or restriction generated to assist management planning and control.
Summary Reports − They contain trends and potential problems which are categorized and summarized that are generated for managers who do not want details.
Exception Reports − They contain exceptions, filtered data to some condition or standard before presenting it to the manager, as information.
Output Integrity Controls
Output integrity controls include routing codes to identify the receiving system, and verification messages to confirm successful receipt of messages that are handled by network protocol.
Printed or screen-format reports should include a date/time for report printing and the data. Multipage reports contain report title or description, and pagination. Pre-printed forms usually include a version number and effective date.
Forms Design
Both forms and reports are the product of input and output design and are business document consisting of specified data. The main difference is that forms provide fields for data input but reports are purely used for reading. For example, order forms, employment and credit application, etc.
During form designing, the designers should know −
who will use them
where would they be delivered
the purpose of the form or report
During form design, automated design tools enhance the developer’s ability to prototype forms and reports and present them to end users for evaluation.
Objectives of Good Form Design
A good form design is necessary to ensure the following −
To keep the screen simple by giving proper sequence, information, and clear captions.
To meet the intended purpose by using appropriate forms.
To ensure the completion of form with accuracy.
To keep the forms attractive by using icons, inverse video, or blinking cursors etc.
To facilitate navigation.
Types of Forms
Flat Forms
It is a single copy form prepared manually or by a machine and printed on a paper. For additional copies of the original, carbon papers are inserted between copies.
It is a simplest and inexpensive form to design, print, and reproduce, which uses less volume.
Unit Set/Snap out Forms
These are papers with one-time carbons interleaved into unit sets for either handwritten or machine use.
Carbons may be either blue or black, standard grade medium intensity. Generally, blue carbons are best for handwritten forms while black carbons are best for machine use.
Continuous strip/Fanfold Forms
These are multiple unit forms joined in a continuous strip with perforations between each pair of forms.
It is a less expensive method for large volume use.
No Carbon Required (NCR) Paper
They use carbonless papers which have two chemical coatings (capsules), one on the face and the other on the back of a sheet of paper.
When pressure is applied, the two capsules interact and create an image.
Testing and Quality Assurance
The software system needs to be checked for its intended behavior and direction of progress at each development stage to avoid duplication of efforts, time and cost overruns, and to assure completion of the system within stipulated time.The software system needs to be checked for its intended behavior and direction of progress at each development stage to avoid duplication of efforts, time and cost overruns, and to assure completion of the system within stipulated time.
System testing and quality assurance come to aid for checking the system. It includes −
- Product level quality (Testing)
- Process level quality.
Let us go through them briefly −
Testing
Testing is the process or activity that checks the functionality and correctness of software according to specified user requirements in order to improve the quality and reliability of system. It is an expensive, time consuming, and critical approach in system development which requires proper planning of overall testing process.
A successful test is one that finds the errors. It executes the program with explicit intention of finding error, i.e., making the program fail. It is a process of evaluating system with an intention of creating a strong system and mainly focuses on the weak areas of the system or software.
Characteristics of System Testing
System testing begins at the module level and proceeds towards the integration of the entire software system. Different testing techniques are used at different times while testing the system. It is conducted by the developer for small projects and by independent testing groups for large projects.
Stages of System Testing
The following stages are involved in testing −
Test Strategy
It is a statement that provides information about the various levels, methods, tools, and techniques used for testing the system. It should satisfy all the needs of an organization.
Test Plan
It provides a plan for testing the system and verifies that the system under testing fulfils all the design and functional specifications. The test plan provides the following information −
- Objectives of each test phase
- Approaches and tools used for testing
- Responsibilities and time required for each testing activity
- Availability of tools, facilities, and test libraries
- Procedures and standards required for planning and conducting the tests
- Factors responsible for successful completion of testing process
Test Case Design
A number of test cases are identified for each module of the system to be tested.
Each test case will specify how the implementation of a particular requirement or design decision is to be tested and the criteria for the success of the test.
The test cases along with the test plan are documented as a part of a system specification document or in a separate document called test specification or test description.
Test Procedures
It consists of the steps that should be followed to execute each of the test cases. These procedures are specified in a separate document called test procedure specification. This document also specifies any special requirements and formats for reporting the result of testing.
Test Result Documentation
Test result file contains brief information about the total number of test cases executed, the number of errors, and nature of errors. These results are then assessed against criteria in the test specification to determine the overall outcome of the test.
Types of Testing
Testing can be of various types and different types of tests are conducted depending on the kind of bugs one seeks to discover −
Unit Testing
Also known as Program Testing, it is a type of testing where the analyst tests or focuses on each program or module independently. It is carried out with the intention of executing each statement of the module at least once.
In unit testing, accuracy of program cannot be assured and it is difficult to conduct testing of various input combination in detail.
It identifies maximum errors in a program as compared to other testing techniques.
Integration Testing
In Integration Testing, the analyst tests multiple module working together. It is used to find discrepancies between the system and its original objective, current specifications, and systems documentation.
Here the analysts are try to find areas where modules have been designed with different specifications for data length, type, and data element name.
It verifies that file sizes are adequate and that indices have been built properly.
Functional Testing
Function testing determines whether the system is functioning correctly according to its specifications and relevant standards documentation. Functional testing typically starts with the implementation of the system, which is very critical for the success of the system.
Functional testing is divided into two categories −
Positive Functional Testing − It involves testing the system with valid inputs to verify that the outputs produced are correct.
Negative Functional Testing − It involves testing the software with invalid inputs and undesired operating conditions.
Rules for System Testing
To carry out system testing successfully, you need to follow the given rules −
Testing should be based on the requirements of user.
Before writing testing scripts, understand the business logic should be understood thoroughly.
Test plan should be done as soon as possible.
Testing should be done by the third party.
It should be performed on static software.
Testing should be done for valid and invalid input conditions.
Testing should be reviewed and examined to reduce the costs.
Both static and dynamic testing should be conducted on the software.
Documentation of test cases and test results should be done.
Quality Assurance
It is the review of system or software products and its documentation for assurance that system meets the requirements and specifications.
Purpose of QA is to provide confidence to the customers by constant delivery of product according to specification.
Software quality Assurance (SQA) is a techniques that includes procedures and tools applied by the software professionals to ensure that software meet the specified standard for its intended use and performance.
The main aim of SQA is to provide proper and accurate visibility of software project and its developed product to the administration.
It reviews and audits the software product and its activities throughout the life cycle of system development.
Objectives of Quality Assurance
The objectives of conducting quality assurance are as follows −
To monitor the software development process and the final software developed.
To ensure whether the software project is implementing the standards and procedures set by the management.
To notify groups and individuals about the SQA activities and results of these activities.
To ensure that the issues, which are not solved within the software are addressed by the upper management.
To identify deficiencies in the product, process, or the standards, and fix them.
Levels of Quality Assurance
There are several levels of QA and testing that need to be performed in order to certify a software product.
Level 1 − Code Walk-through
At this level, offline software is examined or checked for any violations of the official coding rules. In general, the emphasis is placed on examination of the documentation and level of in-code comments.
Level 2 − Compilation and Linking
At this level, it is checked that the software can compile and link all official platforms and operating systems.
Level 3 − Routine Running
At this level, it is checked that the software can run properly under a variety of conditions such as certain number of events and small and large event sizes etc.
Level 4 − Performance test
At this final level, it is checked that the performance of the software satisfies the previously specified performance level.
System Implementation and Maintenance
Implementation is a process of ensuring that the information system is operational. It involves −
- Constructing a new system from scratch
- Constructing a new system from the existing one.
Implementation allows the users to take over its operation for use and evaluation. It involves training the users to handle the system and plan for a smooth conversion.
Training
The personnel in the system must know in detail what their roles will be, how they can use the system, and what the system will or will not do. The success or failure of welldesigned and technically elegant systems can depend on the way they are operated and used.
Training Systems Operators
Systems operators must be trained properly such that they can handle all possible operations, both routine and extraordinary. The operators should be trained in what common malfunctions may occur, how to recognize them, and what steps to take when they come.
Training involves creating troubleshooting lists to identify possible problems and remedies for them, as well as the names and telephone numbers of individuals to contact when unexpected or unusual problems arise.
Training also involves familiarization with run procedures, which involves working through the sequence of activities needed to use a new system.
User Training
End-user training is an important part of the computer-based information system development, which must be provided to employees to enable them to do their own problem solving.
User training involves how to operate the equipment, troubleshooting the system problem, determining whether a problem that arose is caused by the equipment or software.
Most user training deals with the operation of the system itself. The training courses must be designed to help the user with fast mobilization for the organization.
Training Guidelines
- Establishing measurable objectives
- Using appropriate training methods
- Selecting suitable training sites
- Employing understandable training materials
Training Methods
Instructor-led training
It involves both trainers and trainees, who have to meet at the same time, but not necessarily at the same place. The training session could be one-on-one or collaborative. It is of two types −
Virtual Classroom
In this training, trainers must meet the trainees at the same time, but are not required to be at the same place. The primary tools used here are: video conferencing, text based Internet relay chat tools, or virtual reality packages, etc.
Normal Classroom
The trainers must meet the trainees at the same time and at the same place. They primary tools used here are blackboard, overhead projectors, LCD projector, etc.
Self-Paced Training
It involves both trainers and trainees, who do not need to meet at the same place or at the same time. The trainees learn the skills themselves by accessing the courses at their own convenience. It is of two types −
Multimedia Training
In this training, courses are presented in multimedia format and stored on CD-ROM. It minimizes the cost in developing an in-house training course without assistance from external programmers.
Web-based Training
In this training, courses are often presented in hyper media format and developed to support internet and intranet. It provides just–in-time training for end users and allow organization to tailor training requirements.
Conversion
It is a process of migrating from the old system to the new one. It provides understandable and structured approach to improve the communication between management and project team.
Conversion Plan
It contains description of all the activities that must occur during implementation of the new system and put it into operation. It anticipates possible problems and solutions to deal with them.
It includes the following activities −
- Name all files for conversions.
- Identifying the data requirements to develop new files during conversion.
- Listing all the new documents and procedures that are required.
- Identifying the controls to be used in each activity.
- Identifying the responsibility of person for each activity.
- Verifying conversion schedules.
Conversion Methods
The four methods of conversion are −
- Parallel Conversion
- Direct Cutover Conversion
- Pilot Approach
- Phase-In Method
| Method | Description | Advantages | Disadvantages |
|---|---|---|---|
Parallel Conversion |
Old and new systems are used simultaneously. | Provides fallback when new system fails. Offers greatest security and ultimately testing of new system. |
Causes cost overruns. New system may not get fair trail. |
Direct Cutover Conversion |
New system is implemented and old system is replaced completely. |
Forces users to make new system work Immediate benefit from new methods and control. |
No fall back if problems arise with new system Requires most careful planning |
Pilot Approach |
Supports phased approach that gradually implement system across all users |
Allows training and installation without unnecessary use of resources. Avoid large contingencies from risk management. |
A long term phasein causes a problem of whether conversion goes well or not. |
Phase-In Method |
Working version of system implemented in one part of organization based on feedback, it is installed throughout the organization all alone or stage by stage. |
Provides experience and line test before implementation When preferred new system involves new technology or drastic changes in performance. |
Gives impression that old system is erroneous and it is not reliable. |
File Conversion
It is a process of converting one file format into another. For example, file in WordPerfect format can be converted into Microsoft Word.
For successful conversion, a conversion plan is required, which includes −
- Knowledge of the target system and understanding of the present system
- Teamwork
- Automated methods, testing and parallel operations
- Continuous support for correcting problems
- Updating systems/user documentation, etc
Many popular applications support opening and saving to other file formats of the same type. For example, Microsoft Word can open and save files in many other word processing formats.
Post-Implementation Evaluation Review (PIER)
PIER is a tool or standard approach for evaluating the outcome of the project and determine whether the project is producing the expected benefits to the processes, products or services. It enables the user to verify that the project or system has achieved its desired outcome within specified time period and planned cost.
PIER ensures that the project has met its goals by evaluating the development and management processes of the project.
Objectives of PIER
The objectives of having a PIER are as follows −
To determine the success of a project against the projected costs, benefits, and timelines.
To identify the opportunities to add additional value to the project.
To determine strengths and weaknesses of the project for future reference and appropriate action.
To make recommendations on the future of the project by refining cost estimating techniques.
The following staff members should be included in the review process −
- Project team and Management
- User staff
- Strategic Management Staff
- External users
System Maintenance / Enhancement
Maintenance means restoring something to its original conditions. Enhancement means adding, modifying the code to support the changes in the user specification. System maintenance conforms the system to its original requirements and enhancement adds to system capability by incorporating new requirements.
Thus, maintenance changes the existing system, enhancement adds features to the existing system, and development replaces the existing system. It is an important part of system development that includes the activities which corrects errors in system design and implementation, updates the documents, and tests the data.
Maintenance Types
System maintenance can be classified into three types −
Corrective Maintenance − Enables user to carry out the repairing and correcting leftover problems.
Adaptive Maintenance − Enables user to replace the functions of the programs.
Perfective Maintenance − Enables user to modify or enhance the programs according to the users’ requirements and changing needs.
System Security and Audit
System Audit
It is an investigation to review the performance of an operational system. The objectives of conducting a system audit are as follows −
To compare actual and planned performance.
To verify that the stated objectives of system are still valid in current environment.
To evaluate the achievement of stated objectives.
To ensure the reliability of computer based financial and other information.
To ensure all records included while processing.
To ensure protection from frauds.
Audit of Computer System Usage
Data processing auditors audits the usage of computer system in order to control it. The auditor need control data which is obtained by computer system itself.
The System Auditor
The role of auditor begins at the initial stage of system development so that resulting system is secure. It describes an idea of utilization of system that can be recorded which helps in load planning and deciding on hardware and software specifications. It gives an indication of wise use of the computer system and possible misuse of the system.
Audit Trial
An audit trial or audit log is a security record which is comprised of who has accessed a computer system and what operations are performed during a given period of time. Audit trials are used to do detailed tracing of how data on the system has changed.
It provides documentary evidence of various control techniques that a transaction is subject to during its processing. Audit trials do not exist independently. They are carried out as a part of accounting for recovering lost transactions.
Audit Methods
Auditing can be done in two different ways −
Auditing around the Computer
- Take sample inputs and manually apply processing rules.
- Compare outputs with computer outputs.
Auditing through the Computer
- Establish audit trial which allows examining selected intermediate results.
- Control totals provide intermediate checks.
Audit Considerations
Audit considerations examine the results of the analysis by using both the narratives and models to identify the problems caused due to misplaced functions, split processes or functions, broken data flows, missing data, redundant or incomplete processing, and nonaddressed automation opportunities.
The activities under this phase are as follows −
- Identification of the current environment problems
- Identification of problem causes
- Identification of alternative solutions
- Evaluation and feasibility analysis of each solution
- Selection and recommendation of most practical and appropriate solution
- Project cost estimation and cost benefit analysis
Security
System security refers to protecting the system from theft, unauthorized access and modifications, and accidental or unintentional damage. In computerized systems, security involves protecting all the parts of computer system which includes data, software, and hardware. Systems security includes system privacy and system integrity.
System privacy deals with protecting individuals systems from being accessed and used without the permission/knowledge of the concerned individuals.
System integrity is concerned with the quality and reliability of raw as well as processed data in the system.
Control Measures
There are variety of control measures which can be broadly classified as follows −
Backup
Regular backup of databases daily/weekly depending on the time criticality and size.
Incremental back up at shorter intervals.
Backup copies kept in safe remote location particularly necessary for disaster recovery.
Duplicate systems run and all transactions mirrored if it is a very critical system and cannot tolerate any disruption before storing in disk.
Physical Access Control to Facilities
- Physical locks and Biometric authentication. For example, finger print
- ID cards or entry passes being checked by security staff.
- Identification of all persons who read or modify data and logging it in a file.
Using Logical or Software Control
- Password system.
- Encrypting sensitive data/programs.
- Training employees on data care/handling and security.
- Antivirus software and Firewall protection while connected to internet.
Risk Analysis
A risk is the possibility of losing something of value. Risk analysis starts with planning for secure system by identifying the vulnerability of system and impact of this. The plan is then made to manage the risk and cope with disaster. It is done to accesses the probability of possible disaster and their cost.
Risk analysis is a teamwork of experts with different backgrounds like chemicals, human error, and process equipment.
The following steps are to be followed while conducting risk analysis −
Identification of all the components of computer system.
Identification of all the threats and hazards that each of the components faces.
Quantify risks i.e. assessment of loss in the case threats become reality.
Risk Analysis – Main Steps
As the risks or threats are changing and the potential loss are also changing, management of risk should be performed on periodic basis by senior managers.
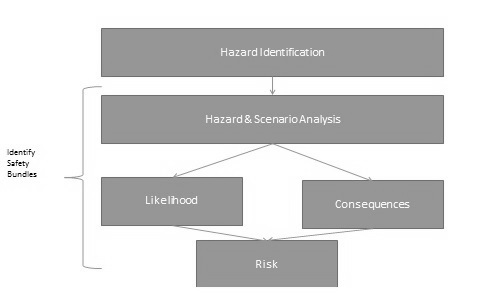
Risk management is a continuous process and it involves the following steps −
Identification of security measures.
Calculation of the cost of implementation of security measures.
Comparison of the cost of security measures with the loss and probability of threats.
Selection and implementation of security measures.
Review of the implementation of security measures.
Object Oriented Approach
In the object-oriented approach, the focus is on capturing the structure and behavior of information systems into small modules that combines both data and process. The main aim of Object Oriented Design (OOD) is to improve the quality and productivity of system analysis and design by making it more usable.
In analysis phase, OO models are used to fill the gap between problem and solution. It performs well in situation where systems are undergoing continuous design, adaption, and maintenance. It identifies the objects in problem domain, classifying them in terms of data and behavior.
The OO model is beneficial in the following ways −
It facilitates changes in the system at low cost.
It promotes the reuse of components.
It simplifies the problem of integrating components to configure large system.
It simplifies the design of distributed systems.
Elements of Object-Oriented System
Let us go through the characteristics of OO System −
Objects − An object is something that is exists within problem domain and can be identified by data (attribute) or behavior. All tangible entities (student, patient) and some intangible entities (bank account) are modeled as object.
Attributes − They describe information about the object.
Behavior − It specifies what the object can do. It defines the operation performed on objects.
Class − A class encapsulates the data and its behavior. Objects with similar meaning and purpose grouped together as class.
Methods − Methods determine the behavior of a class. They are nothing more than an action that an object can perform.
Message − A message is a function or procedure call from one object to another. They are information sent to objects to trigger methods. Essentially, a message is a function or procedure call from one object to another.
Features of Object-Oriented System
An object-oriented system comes with several great features which are discussed below.
Encapsulation
Encapsulation is a process of information hiding. It is simply the combination of process and data into a single entity. Data of an object is hidden from the rest of the system and available only through the services of the class. It allows improvement or modification of methods used by objects without affecting other parts of a system.
Abstraction
It is a process of taking or selecting necessary method and attributes to specify the object. It focuses on essential characteristics of an object relative to perspective of user.
Relationships
All the classes in the system are related with each other. The objects do not exist in isolation, they exist in relationship with other objects.
There are three types of object relationships −
Aggregation − It indicates relationship between a whole and its parts.
Association − In this, two classes are related or connected in some way such as one class works with another to perform a task or one class acts upon other class.
Generalization − The child class is based on parent class. It indicates that two classes are similar but have some differences.
Inheritance
Inheritance is a great feature that allows to create sub-classes from an existing class by inheriting the attributes and/or operations of existing classes.
Polymorphism and Dynamic Binding
Polymorphism is the ability to take on many different forms. It applies to both objects and operations. A polymorphic object is one who true type hides within a super or parent class.
In polymorphic operation, the operation may be carried out differently by different classes of objects. It allows us to manipulate objects of different classes by knowing only their common properties.
Structured Approach Vs. Object-Oriented Approach
The following table explains how the object-oriented approach differs from the traditional structured approach −
| Structured Approach | Object Oriented Approach |
|---|---|
| It works with Top-down approach. | It works with Bottom-up approach. |
| Program is divided into number of submodules or functions. | Program is organized by having number of classes and objects. |
| Function call is used. | Message passing is used. |
| Software reuse is not possible. | Reusability is possible. |
| Structured design programming usually left until end phases. | Object oriented design programming done concurrently with other phases. |
| Structured Design is more suitable for offshoring. | It is suitable for in-house development. |
| It shows clear transition from design to implementation. | Not so clear transition from design to implementation. |
| It is suitable for real time system, embedded system and projects where objects are not the most useful level of abstraction. | It is suitable for most business applications, game development projects, which are expected to customize or extended. |
| DFD & E-R diagram model the data. | Class diagram, sequence diagram, state chart diagram, and use cases all contribute. |
| In this, projects can be managed easily due to clearly identifiable phases. | In this approach, projects can be difficult to manage due to uncertain transitions between phase. |
Unified Modeling Language (UML)
UML is a visual language that lets you to model processes, software, and systems to express the design of system architecture. It is a standard language for designing and documenting a system in an object oriented manner that allow technical architects to communicate with developer.
It is defined as set of specifications created and distributed by Object Management Group. UML is extensible and scalable.
The objective of UML is to provide a common vocabulary of object-oriented terms and diagramming techniques that is rich enough to model any systems development project from analysis through implementation.
UML is made up of −
Diagrams − It is a pictorial representations of process, system, or some part of it.
Notations − It consists of elements that work together in a diagram such as connectors, symbols, notes, etc.
Example of UML Notation for class

Instance diagram-UML notation

Operations Performed on Objects
The following operations are performed on the objects −
Constructor/Destructor − Creating new instances of a class and deleting existing instances of a class. For example, adding a new employee.
Query − Accessing state without changing value, has no side effects. For example, finding address of a particular employee.
Update − Changes value of one or more attributes & affect state of object For example, changing the address of an employee.
Uses of UML
UML is quite useful for the following purposes −
- Modeling the business process
- Describing the system architecture
- Showing the application structure
- Capturing the system behavior
- Modeling the data structure
- Building the detailed specifications of the system
- Sketching the ideas
- Generating the program code
Static Models
Static models show the structural characteristics of a system, describe its system structure, and emphasize on the parts that make up the system.
They are used to define class names, attributes, methods, signature, and packages.
UML diagrams that represent static model include class diagram, object diagram, and use case diagram.
Dynamic Models
Dynamic models show the behavioral characteristics of a system, i.e., how the system behaves in response to external events.
Dynamic models identify the object needed and how they work together through methods and messages.
They are used to design the logic and behavior of system.
UML diagrams represent dynamic model include sequence diagram, communication diagram, state diagram, activity diagram.
Object Oriented System Development Life Cycle
It consists of three macro processes −
- Object Oriented Analysis (OOA)
- Object oriented design (OOD)
- Object oriented Implementation (OOI)
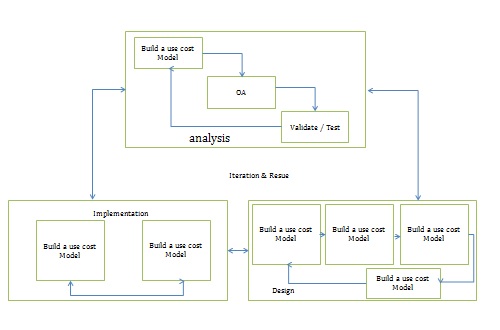
Object Oriented Systems Development Activities
Object-oriented systems development includes the following stages −
- Object-oriented analysis
- Object-oriented design
- Prototyping
- Implementation
- Incremental testing
Object-Oriented Analysis
This phase concerns with determining the system requirements and to understand the system requirements build a use-case model. A use-case is a scenario to describe the interaction between user and computer system. This model represents the user needs or user view of system.
It also includes identifying the classes and their relationships to the other classes in the problem domain, that make up an application.
Object-Oriented Design
The objective of this phase is to design and refine the classes, attributes, methods, and structures that are identified during the analysis phase, user interface, and data access. This phase also identifies and defines the additional classes or objects that support implementation of the requirement.
Prototyping
Prototyping enables to fully understand how easy or difficult it will be to implement some of the features of the system.
It can also give users a chance to comment on the usability and usefulness of the design. It can further define a use-case and make use-case modeling much easier.
Implementation
It uses either Component-Based Development (CBD) or Rapid Application Development (RAD).
Component-based development (CBD)
CODD is an industrialized approach to the software development process using various range of technologies like CASE tools. Application development moves from custom development to assembly of pre-built, pre-tested, reusable software components that operate with each other. A CBD developer can assemble components to construct a complete software system.
Rapid Application Development (RAD)
RAD is a set of tools and techniques that can be used to build an application faster than typically possible with traditional methods. It does not replace SDLC but complements it, since it focuses more on process description and can be combined perfectly with the object oriented approach.
Its task is to build the application quickly and incrementally implement the user requirements design through tools such as visual basic, power builder, etc.
Incremental Testing
Software development and all of its activities including testing are an iterative process. Therefore, it can be a costly affair if we wait to test a product only after its complete development. Here incremental testing comes into picture wherein the product is tested during various stages of its development.