This document provides an overview of the End-to-End AutoML pipeline and components. To learn how to train a model with End-to-End AutoML, see Train a model with End-to-End AutoML.
Tabular Workflow for End-to-End AutoML is a complete AutoML pipeline for classification and regression tasks. It is similar to the AutoML API, but allows you to choose what to control and what to automate. Instead of having controls for the whole pipeline, you have controls for every step in the pipeline. These pipeline controls include:
- Data splitting
- Feature engineering
- Architecture search
- Model training
- Model ensembling
- Model distillation
Benefits
The following are some of the benefits of Tabular Workflow for End-to-End AutoML :
- Supports large datasets that are multiple TB in size and have up to 1000 columns.
- Allows you to improve stability and lower training time by limiting the search space of architecture types or skipping architecture search.
- Allows you to improve training speed by manually selecting the hardware used for training and architecture search.
- Allows you to reduce model size and improve latency with distillation or by changing the ensemble size.
- Each AutoML component can be inspected in a powerful pipelines graph interface that lets you see the transformed data tables, evaluated model architectures, and many more details.
- Each AutoML component gets extended flexibility and transparency, such as being able to customize parameters, hardware, view process status, logs, and more.
End-to-End AutoML on Vertex AI Pipelines
Tabular Workflow for End-to-End AutoML is a managed instance of Vertex AI Pipelines.
Vertex AI Pipelines is a serverless service that runs Kubeflow pipelines. You can use pipelines to automate and monitor your machine learning and data preparation tasks. Each step in a pipeline performs part of the pipeline's workflow. For example, a pipeline can include steps to split data, transform data types, and train a model. Since steps are instances of pipeline components, steps have inputs, outputs, and a container image. Step inputs can be set from the pipeline's inputs or they can depend on the output of other steps within this pipeline. These dependencies define the pipeline's workflow as a directed acyclic graph.
Overview of pipeline and components
The following diagram shows the modeling pipeline for Tabular Workflow for End-to-End AutoML :

The pipeline components are:
- feature-transform-engine: Perform feature engineering. See Feature Transform Engine for details.
- split-materialized-data:
Split the materialized data into a training set, an evaluation set, and a test set.
Input:
- Materialized data
materialized_data.
Output:
- Materialized training split
materialized_train_split. - Materialized evaluation split
materialized_eval_split. - Materialized test set
materialized_test_split.
- Materialized data
- merge-materialized-splits - Merge the materialized evaluation split and the materialized train split.
automl-tabular-stage-1-tuner - Perform model architecture search and tune hyperparameters.
- An architecture is defined by a set of hyperparameters.
- Hyperparameters include the model type and the model parameters.
- Model types considered are neural networks and boosted trees.
- A model is trained for each architecture considered.
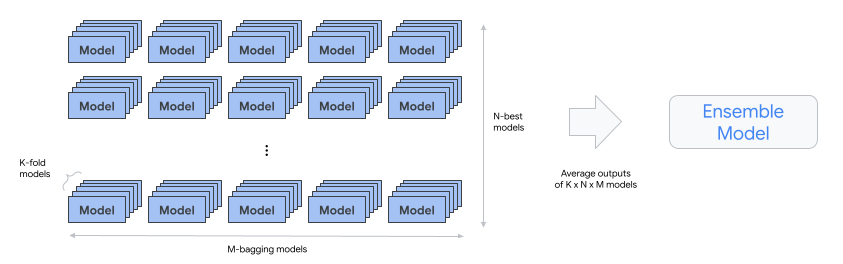
automl-tabular-cv-trainer - Cross-validate architectures by training models on different folds of the input data.
- The architectures considered are those that gave the best results in the previous step.
- Approximately ten best architectures are selected. The precise number is defined by the training budget.
automl-tabular-ensemble - Ensemble the best architectures to produce a final model.
- The following diagram is an illustration of K-fold cross validation with bagging:
condition-is-distill - Optional. Create a smaller version of the ensemble model.
- A smaller model reduces latency and cost for prediction.
automl-tabular-infra-validator - Validate whether the trained model is a valid model.
model-upload - Upload the model.
condition-is-evaluation - Optional. Use the test set to calculate evaluation metrics.