This page shows you how to train a forecasting model from a tabular dataset with Tabular Workflow for Forecasting.
To learn about the service accounts used by this workflow, see Service accounts for Tabular Workflows.
If you receive an error related to quotas while running Tabular Workflow for Forecasting, you might need to request a higher quota. To learn more, see Manage quotas for Tabular Workflows.
Tabular Workflow for Forecasting does not support model export.
Workflow APIs
This workflow uses the following APIs:
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
Get the URI of the previous hyperparameter tuning result
If you have previously completed a Tabular Workflow for Forecasting run, you can use the hyperparameter tuning result from the previous run to save training time and resources. You can find the previous hyperparameter tuning result by using the Google Cloud console or by loading it programmatically with the API.
Google Cloud console
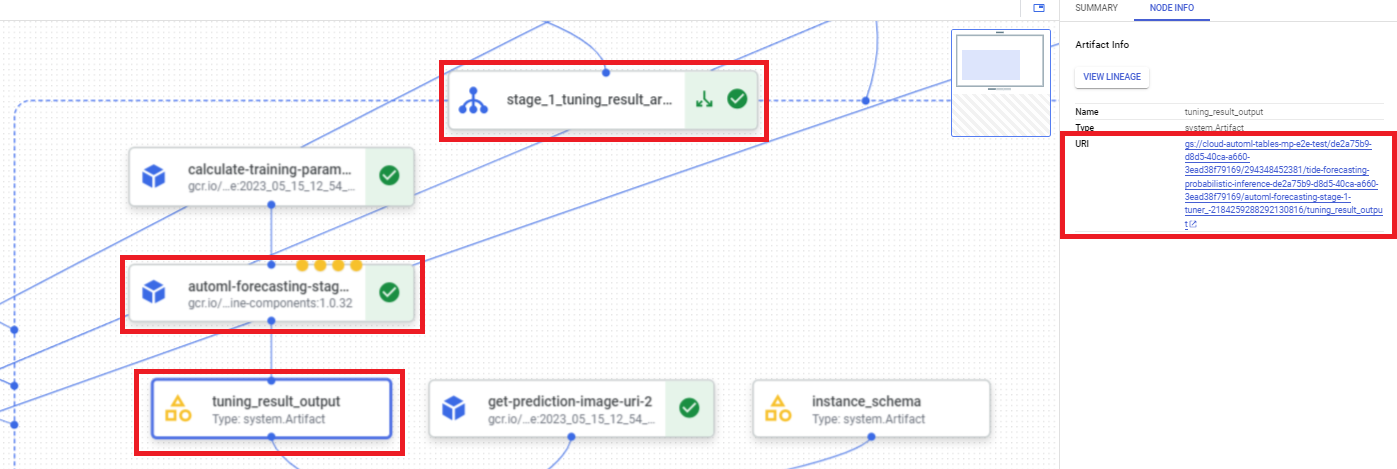
To find the hyperparameter tuning result URI by using the Google Cloud console, perform the following steps:
In the Google Cloud console, in the Vertex AI section, go to the Pipelines page.
Select the Runs tab.
Select the pipeline run you want to use.
Select Expand Artifacts.
Click on component exit-handler-1.
Click on component stage_1_tuning_result_artifact_uri_empty.
Find component automl-forecasting-stage-1-tuner.
Click on the associated artifact tuning_result_output.
Select the Node Info tab.
Copy the URI for use in the Train a model step.
API: Python
The following sample code demonstrates how you can load the hyperparameter
tuning result by using the API. The variable job refers to the previous
model training pipeline run.
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
Train a model
The following sample code demonstrates how you can run a model training pipeline:
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
The optional service_account parameter in job.run() lets you set the
Vertex AI Pipelines service account to an account of your choice.
Vertex AI supports the following methods for training your model:
Time series Dense Encoder (TiDE). To use this model training method, define your pipeline and parameter values by using the following function:
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Temporal Fusion Transformer (TFT). To use this model training method, define your pipeline and parameter values by using the following function:
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L). To use this model training method, define your pipeline and parameter values by using the following function:
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+. To use this model training method, define your pipeline and parameter values by using the following function:
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
To learn more, see Model training methods.
The training data can be either a CSV file in Cloud Storage or a table in BigQuery.
The following is a subset of model training parameters:
| Parameter name | Type | Definition |
|---|---|---|
optimization_objective |
String | By default, Vertex AI minimizes the root-mean-squared error (RMSE). If you want a different optimization objective for your forecast model, choose one of the options in Optimization objectives for forecasting models. If you choose to minimize the quantile loss, you must also specify a value for quantiles. |
enable_probabilistic_inference |
Boolean | If set to true, Vertex AI models the probability distribution of the forecast. Probabilistic inference can improve model quality by handling noisy data and quantifying uncertainty. If quantiles are specified, then Vertex AI also returns the quantiles of the distribution. Probabilistic inference is compatible only with the Time series Dense Encoder (TiDE) and the AutoML (L2L) training methods. Probabilistic inference is incompatible with the minimize-quantile-loss optimization objective. |
quantiles |
List[float] | Quantiles to use for minimize-quantile-loss optimization objective and probabilistic inference. Provide a list of up to five unique numbers between 0 and 1, exclusive. |
time_column |
String | The time column. To learn more, see Data structure requirements. |
time_series_identifier_columns |
List[str] | The time series identifier columns. To learn more, see Data structure requirements. |
weight_column |
String | (Optional) The weight column. To learn more, see Add weights to your training data. |
time_series_attribute_columns |
List[str] | (Optional) The name or names of the columns that are time series attributes. To learn more, see Feature type and availability at forecast. |
available_at_forecast_columns |
List[str] | (Optional) The name or names of the covariate columns whose value is known at forecast time. To learn more, see Feature type and availability at forecast. |
unavailable_at_forecast_columns |
List[str] | (Optional) The name or names of the covariate columns whose value is unknown at forecast time. To learn more, see Feature type and availability at forecast. |
forecast_horizon |
Integer | (Optional) The forecast horizon determines how far into the future the model forecasts the target value for each row of prediction data. To learn more, see Forecast horizon, context window, and forecast window. |
context_window |
Integer | (Optional) The context window sets how far back the model looks during training (and for forecasts). In other words, for each training datapoint, the context window determines how far back the model looks for predictive patterns. To learn more, see Forecast horizon, context window, and forecast window. |
window_max_count |
Integer | (Optional) Vertex AI generates forecast windows from the input data using a rolling window strategy. The default strategy is Count. The default value for the maximum number of windows is 100,000,000. Set this parameter to provide a custom value for the maximum number of windows. To learn more, see Rolling window strategies. |
window_stride_length |
Integer | (Optional) Vertex AI generates forecast windows from the input data using a rolling window strategy. To select the Stride strategy, set this parameter to the value of the stride length. To learn more, see Rolling window strategies. |
window_predefined_column |
String | (Optional) Vertex AI generates forecast windows from the input data using a rolling window strategy. To select the Column strategy, set this parameter to the name of the column with True or False values. To learn more, see Rolling window strategies. |
holiday_regions |
List[str] | (Optional) You can select one or more geographical regions to enable holiday effect modeling. During training, Vertex AI creates holiday categorical features within the model based on the date from time_column and the specified geographical regions. By default, holiday effect modeling is disabled. To learn more, see Holiday regions. |
predefined_split_key |
String | (Optional) By default, Vertex AI uses a chronological split algorithm to separate your forecasting data into the three data splits. If you want to control which training data rows are used for which split, provide the name of the column containing the data split values (TRAIN, VALIDATION, TEST). To learn more, see Data splits for forecasting. |
training_fraction |
Float | (Optional) By default, Vertex AI uses a chronological split algorithm to separate your forecasting data into the three data splits. 80% of the data is assigned to the training set, 10% is assigned to the validation split, and 10% is assigned to the test split. Set this parameter if you want to customize the fraction of the data that is assigned to the training set. To learn more, see Data splits for forecasting. |
validation_fraction |
Float | (Optional) By default, Vertex AI uses a chronological split algorithm to separate your forecasting data into the three data splits. 80% of the data is assigned to the training set, 10% is assigned to the validation split, and 10% is assigned to the test split. Set this parameter if you want to customize the fraction of the data that is assigned to the validation set. To learn more, see Data splits for forecasting. |
test_fraction |
Float | (Optional) By default, Vertex AI uses a chronological split algorithm to separate your forecasting data into the three data splits. 80% of the data is assigned to the training set, 10% is assigned to the validation split, and 10% is assigned to the test split. Set this parameter if you want to customize the fraction of the data that is assigned to the test set. To learn more, see Data splits for forecasting. |
data_source_csv_filenames |
String | A URI for a CSV stored in Cloud Storage. |
data_source_bigquery_table_path |
String | A URI for a BigQuery table. |
dataflow_service_account |
String | (Optional) Custom service account to run Dataflow jobs. The Dataflow job can be configured to use private IPs and a specific VPC subnet. This parameter acts as an override for the default Dataflow worker service account. |
run_evaluation |
Boolean | If set to True, Vertex AI evaluates the ensembled model on the test split. |
evaluated_examples_bigquery_path |
String | The path of the BigQuery dataset used during model evaluation. The dataset serves as a destination for the predicted examples. The parameter value must be set if run_evaluation is set to True and must have the following format: bq://[PROJECT].[DATASET]. |
Transformations
You can provide a dictionary mapping of auto- or type-resolutions to feature columns. The supported types are: auto, numeric, categorical, text, and timestamp.
| Parameter name | Type | Definition |
|---|---|---|
transformations |
Dict[str, List[str]] | Dictionary mapping of auto- or type-resolutions |
The following code provides a helper function for populating the transformations
parameter. It also demonstrates how you can use this function to apply automatic
transformations to a set of columns defined by a features variable.
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
To learn more about transformations, see Data types and transformations.
Workflow customization options
You can customize the Tabular Workflow for Forecasting by defining argument values that are passed in during pipeline definition. You can customize your workflow in the following ways:
- Configure hardware
- Skip architecture search
Configure hardware
The following model training parameter lets you configure the machine types and the number of machines for training. This option is a good choice if you have a large dataset and want to optimize the machine hardware accordingly.
| Parameter name | Type | Definition |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (Optional) Custom configuration of the machine types and the number of machines for training. This parameter configures the automl-forecasting-stage-1-tuner component of the pipeline. |
The following code demonstrates how to set n1-standard-8 machine type for the
TensorFlow chief node and n1-standard-4 machine type for the
TensorFlow evaluator node:
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
Skip architecture search
The following model training parameter lets you run the pipeline without the architecture search and provide a set of hyperparameters from a previous pipeline run instead.
| Parameter name | Type | Definition |
|---|---|---|
stage_1_tuning_result_artifact_uri |
String | (Optional) URI of the hyperparameter tuning result from a previous pipeline run. |
What's next
- Learn about batch predictions for forecasting models.
- Learn about pricing for model training.