
Embora a adoção da IA generativa (gen AI) esteja aumentando rapidamente, ainda há um potencial amplamente inexplorado para criar produtos com sua aplicação a dados que têm requisitos mais altos para garantir que permaneçam particulares e confidenciais.
Por exemplo, isso pode significar a aplicação da gen AI para:
Em certas aplicações como essas, pode haver requisitos mais rigorosos em relação à privacidade/confidencialidade, transparência e capacidade de verificação externa do processamento de dados.
O Google desenvolveu várias tecnologias que você pode usar para começar a fazer experimentos e explorar o potencial da gen AI para processar dados que precisem permanecer particulares. Nesta postagem, explicaremos como você pode usar o projeto de código aberto GenC recentemente lançado para combinar a Computação confidencial, os modelos de código aberto do Gemma e as plataformas móveis para começar a criar seus próprios apps habilitados pela gen AI com capacidade para lidar com dados que tenham requisitos mais rigorosos em relação à privacidade/confidencialidade, transparência e capacidade de verificação externa.
O cenário em que nos concentraremos nesta postagem, ilustrado abaixo, envolve um app para dispositivos móveis que tem acesso a dados do dispositivo e deseja realizar o processamento da gen AI nesses dados usando um LLM.
Por exemplo, imagine um app de assistente pessoal que está sendo solicitado a resumir ou responder a uma pergunta sobre notas, um documento ou uma gravação armazenados no dispositivo. O conteúdo pode incluir informações particulares, como mensagens trocadas com outra pessoa, por isso é preciso garantir que ele permaneça particular.
Em nosso exemplo, escolhemos a família Gemma de modelos de código aberto. Observe que, embora nos concentremos aqui em um app para dispositivos móveis, os mesmos princípios se aplicam às empresas que hospedam seus próprios dados no local.
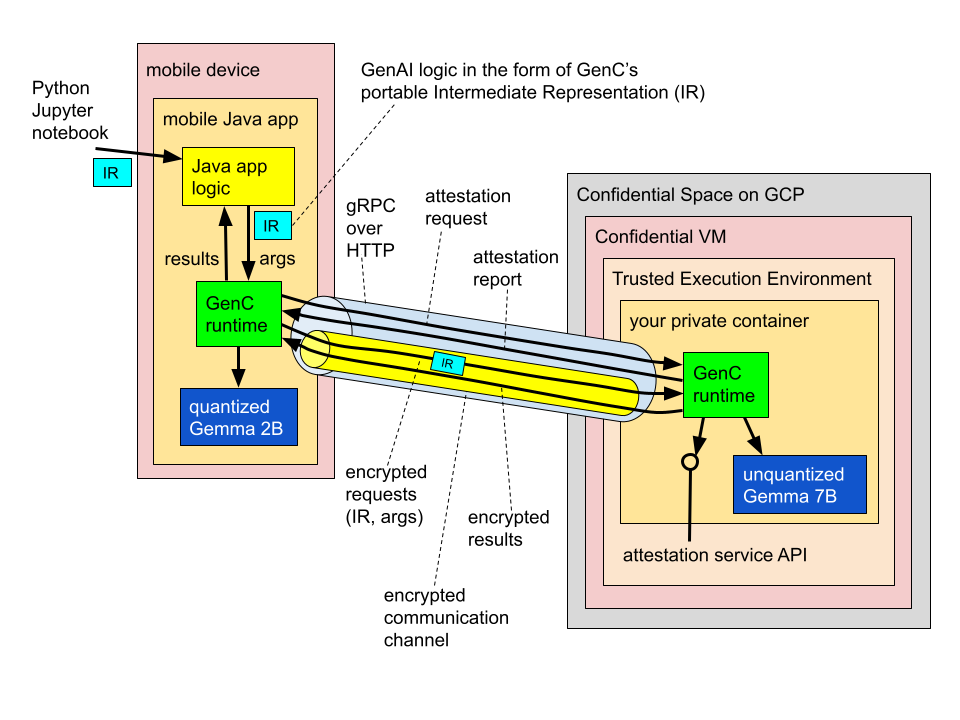
Este exemplo mostra uma configuração "híbrida" que envolve dois LLMs, um executado localmente no dispositivo do usuário e outro hospedado em um ambiente de execução confiável (TEE) do Confidential Space do Google Cloud habilitado por Computação confidencial. Essa arquitetura híbrida permite que o app para dispositivos móveis aproveite os recursos do dispositivo e da nuvem para se beneficiar das vantagens exclusivas de:
Em nosso exemplo, os dois modelos funcionam juntos, conectados a uma cascata de modelos na qual o Gemma 2B menor, mais barato e mais rápido serve como o primeiro nível e lida com consultas mais simples, enquanto o Gemma 7B maior serve como backup para consultas que o primeiro não pode tratar sozinho. Por exemplo, no snippet de código mostrado mais adiante, configuramos o Gemma 2B para atuar como um roteador no dispositivo que primeiro analisa cada consulta de entrada para decidir qual dos dois modelos é o mais apropriado e, em seguida, com base no resultado disso, lida com a consulta localmente no dispositivo ou a redireciona para o Gemma 7B que reside em um TEE baseado na nuvem.
Você pode pensar no TEE na nuvem nesta arquitetura como efetivamente uma extensão lógica do dispositivo móvel do usuário, contando com transparência, garantias criptográficas e hardware confiável:
À primeira vista, essa configuração pode parecer complexa, e de fato seria se alguém tivesse que configurar tudo completamente do zero. Desenvolvemos o GenC precisamente para facilitar o processo.
Segue o exemplo de código que você realmente teria que escrever para configurar um cenário como o indicado acima no GenC. Temos como padrão o Python como uma escolha popular, embora também ofereçamos APIs de criação em Java e C++. Neste exemplo, usamos a presença de um assunto mais confidencial como um sinal de que a consulta deve ser tratada por um modelo mais avançado (que seja capaz de criar uma resposta mais cuidadosa). Tenha em mente que este exemplo é simplificado para fins ilustrativos. Na prática, a lógica de roteamento pode ser mais elaborada e específica à aplicação, e uma engenharia rápida e cuidadosa é essencial para alcançar um bom desempenho, especialmente com modelos menores.
@genc.authoring.traced_computation
def cascade(x):
gemma_2b_on_device = genc.interop.llamacpp.model_inference(
'/device/llamacpp', '/gemma-2b-it.gguf', num_threads=16, max_tokens=64)
gemma_7b_in_a_tee = genc.authoring.confidential_computation[
genc.interop.llamacpp.model_inference(
'/device/llamacpp', '/gemma-7b-it.gguf', num_threads=64, max_tokens=64),
{'server_address': /* server address */, 'image_digest': /* image digest */ }]
router = genc.authoring.serial_chain[
genc.authoring.prompt_template[
"""Read the following input carefully: "{x}".
Does it touch on political topics?"""],
gemma_2b_on_device,
genc.authoring.regex_partial_match['does touch|touches']]
return genc.authoring.conditional[
gemma_2b_on_device(x), gemma_7b_in_a_tee(x)](router(x))
Você pode ver um detalhamento passo a passo de como criar e executar esses exemplos em nossos tutoriais no GitHub. Como você pode ver, o nível de abstração corresponde ao que você pode encontrar em SDKs populares, como o LangChain. As chamadas de inferência de modelo para o Gemma 2B e 7B são intercaladas aqui com modelos de prompt e analisadores de saída e combinadas em cadeias. (A propósito, oferecemos uma interoperabilidade limitada com o LangChain que pretendemos expandir.)
Observe que, enquanto a chamada de inferência do modelo do Gemma 2B é usada diretamente em uma cadeia executada no dispositivo, a chamada do Gemma 7B é explicitamente incorporada a uma instrução confidential_computation.
O fato é que não há surpresas aqui: o programador está sempre no controle total da decisão de qual processamento executar no dispositivo e qual delegar do dispositivo para um TEE na nuvem. Essa decisão é explicitamente refletida na estrutura do código. (Observe que, neste exemplo, só delegamos as chamadas do Gemma 7B a um único back-end confiável, o mecanismo que fornecemos é genérico e é possível utilizá-lo para delegar blocos maiores de processamento, por exemplo, uma repetição de agente inteira, a um número arbitrário de back-ends.)
Embora o código mostrado acima seja expressado por meio de uma sintaxe do Python familiar, nos bastidores ele está sendo transformado no que chamamos de uma forma portável e independente de plataforma e linguagem que batizamos como representação intermediária (ou "IR", na sigla em inglês).
Essa abordagem oferece uma série de vantagens; como:
Em implantações realistas, o desempenho é muitas vezes um fator crítico. Nossos exemplos publicados no momento estão limitados apenas à CPU, e o GenC atualmente oferece apenas o llama.cpp como driver para modelos em um TEE. No entanto, a equipe de Computação confidencial está estendendo o suporte ao Intel TDX com o acelerador integrado Intel AMX, juntamente com a próxima prévia das GPUs Nvidia H100 em execução no modo confidencial, e estamos trabalhando ativamente para expandir a gama de opções de software e hardware disponíveis para desbloquear o melhor desempenho e suporte possíveis para uma gama mais ampla de modelos. Não perca as próximas atualizações!
Esperamos ter aguçado a sua curiosidade e que esta postagem incentive você a tentar criar seus próprios aplicativos de gen AI usando algumas das tecnologias que introduzimos. E, falando nisso, tenha em mente que o GenC é um framework experimental, desenvolvido para fins experimentais e de pesquisa. Nós o criamos para demonstrar o que é possível e para inspirar você a explorar esse espaço emocionante conosco. Se você quiser contribuir, entre em contato com os autores ou simplesmente fale conosco no GitHub. Adoramos colaborar!

Gemini 2.0: Incremente seus apps com interações multimodais em tempo real
Além do bot de chat: IA agêntica com o Gemma

Prepare-se para o Google I/O, nos dias 20 e 21 de maio

Introducing PaliGemma 2 mix: A vision-language model for multiple tasks

Vamos criar uma casa inteligente melhor